Every day I get a new CSV file to feed my language model with more documents. I don’t want to start training from the very beginning every day, but instead to adjust the weights using the new day’s data only. It’s a never-ending daily process. Is this mock-up (below) the right kind of code for that?
I’m suspicious of the .data property working as a setter instead of a getter. Also I’m suspicious the tmp directory is going to need yesterday’s files removed before the new day’s files get written there by the fastai.text lib, and I don’t know if fastai does that for me, or if I have to do that myself before running every new day’s training.
learner = language_model_learner(...) # On day 1 I created the learner using this
...
learner.save('red_model_3')
# day 2, etc:
learner = fastai.text.LanguageLearner.load(device='gpu', name='red_model_3')
learner.data = TextLMDataBunch.from_csv(path=PATH, csv_name='traincsv_newday') # Point to today's new CSV file
learner.fit_one_cycle(2, 1e-3) # etc etc
learner.save('red_model_3')
I had a situation with tabular daily files, though I was training after the fact rather than updating daily.
I used a similar approach - initialized the model with one day’s data and then built a loop to read a the next day and continue to train the model. That set up worked fine. Instead of a loop, you might be able to pass a date string that would pick the proper csv, and then schedule the job to run daily.
Good to know! Question, did you happen to use a line of code like the above successfully? I’m guessing at this point how to retain the weights that we already trained, and then periodically point to a new bunch of data.
Not the exact line due to ongoing changes in fastai, but your structure is doing what it needs to do. Train, save model, then load that model for the next round, lather rinse repeat.
The one tweak you might need to add is to unfreeze the model after you load it. The current default is to only update the last layer, but you probably want to update the earlier layers at least until things stabilize.
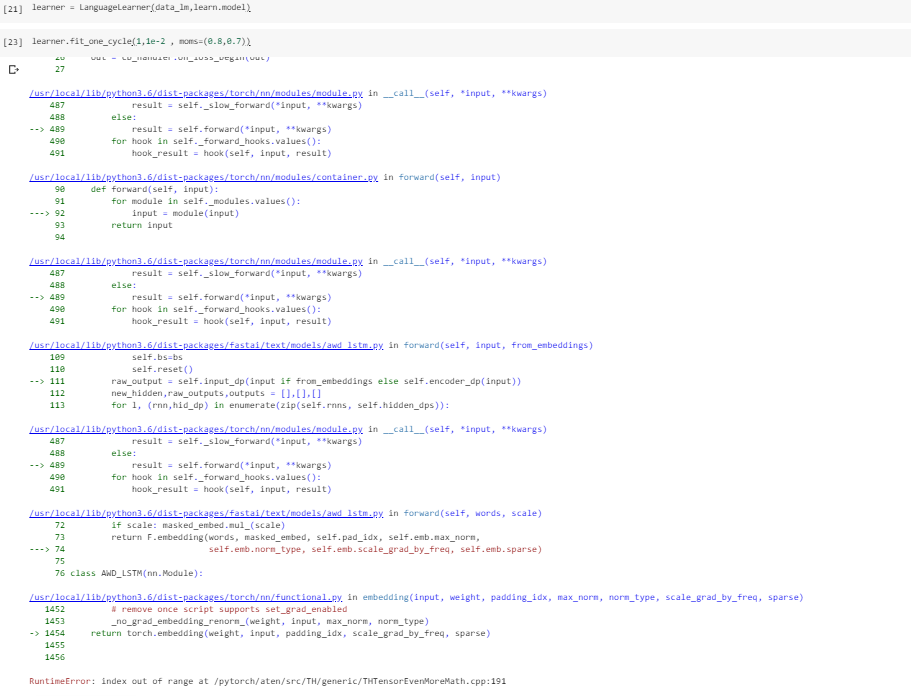
This error is related to the change in the vocab between the two sets. Recall, that the embedding is a lookup of a vector by index. If you have one vocab of 20k words, then you get a new vocab with 30k words, you are going to try to look at, say, index, 31000 and that won’t be in your 20k vocab table. Does that make sense?
Your vocab needs to stay the same when you build your new databunch as the old databunch. New words will show up as xxunk in SpaCy. You can specify this in the factory method with the tokenizer and the vocab. Let me know if that is not clear or does not work in your case.
All depends on the problem you are solving. If you need to expand the vocab, I suspect you can “reserve” some extra space in the embedding matrix, then add new vectors that are the mean of the old and train on that new vocab. But, in the end, the whole idea of embedding puts a hard limit on the index.
If, for your problem, you want less OOV (out-of-vocab) there are a few approaches to take that can minimize that. I have experimented with SentencePiece and that helps a lot (butrequires some custom coding on your side to fit into Fast.ai - nothing too hard, but some bits and bobs.)