from the original paper of super-convergence: [1708.07120] Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates
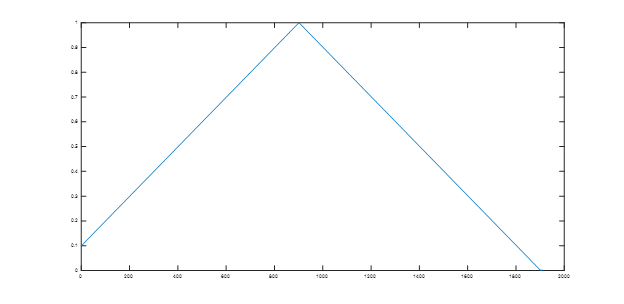
Here we suggest a slight modification of cyclical learning rate policy for super-convergence; always use one cycle that is smaller than the total number of iterations/epochs and allow the learning rate to decrease several orders of magnitude less than the initial learning rate for the remaining iterations.
I could not fully understand the above paragraph. Does he mean after learning rate complete a cycle( initial lr to max lr then back to initial lr), then we should still continue to train further using learning rate “several orders of magnitude less”?
Does it mean something like this:
- train lr = 0.001 to 0.01 for 10 epochs
- train lr = 0.01 to 0.001 for 10 epochs
- train lr = 0.00001 to 0.0001 for 0.5 epochs
- train lr = 0.0001 to 0.00001 for 0.5 epochs
{kind=link}