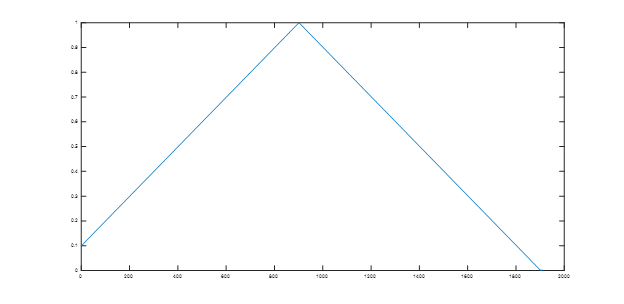
I am sorry for the confusion on the 1cycle policy. It is one cycle but I let the cycle end a little bit before the end of training (and keep the learning rate constant at the smallest value) to allow the weights to settle into the local minima.
I am sorry for the confusion on the 1cycle policy. It is one cycle but I let the cycle end a little bit before the end of training (and keep the learning rate constant at the smallest value) to allow the weights to settle into the local minima.