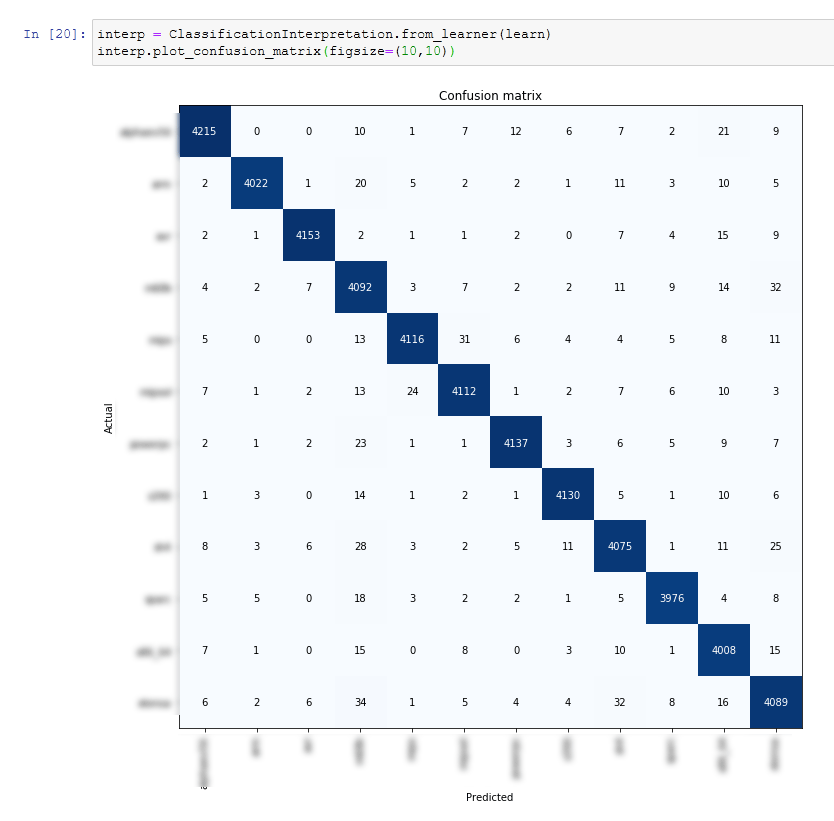
ok… here is what i did…
i created a very small sample filler file of data, just so that i could repeat the train code
but without any intent to use it… (call this the quick and dirty form till I figure out how to do without)
i imported all the same modules then
path = Path(“a/”)
df = pd.read_csv(path / ‘verysmallsamplefiller.txt’)
dep_var = ‘Target’
cat_names = [‘col1’,‘col2’,‘col3’,‘col4’,‘col5’,‘col6’,‘col7’,‘col8’,‘col9’,‘col10’,‘col11’,‘col12’,‘col13’,‘col14’,‘col15’,‘col16’,‘col17’,‘col18’,‘col19’,‘col20’,‘col21’,‘col22’,‘col23’,‘col24’,‘col25’,‘col26’,‘col27’,‘col28’,‘col29’,‘col30’,‘col31’,‘col32’,‘col33’,‘col34’,‘col35’,‘col36’,‘col37’,‘col38’,‘col39’,‘col40’,‘col41’,‘col42’,‘col43’,‘col44’,‘col45’,‘col46’,‘col47’,‘col48’,‘col49’,‘col50’,‘col51’,‘col52’,‘col53’,‘col54’,‘col55’,‘col56’,‘col57’,‘col58’,‘col59’,‘col60’,‘col61’,‘col62’,‘col63’,‘col64’]
cont_names =
procs = [FillMissing, Categorify, Normalize]
testpct = int(len(df) * .10)
valpct = int(len(df)* .20)
trainpct = int(len(df) * .70)
test = TabularList.from_df(df.iloc[-testpct:-1].copy(), path=path, cat_names=cat_names, cont_names=cont_names)
data = (TabularList.from_df(df, path=path, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(list(range(valpct,trainpct)))
.label_from_df(cols=dep_var)
.add_test(test)
.databunch())
learn = tabular_learner(data, layers=[250,400], metrics=accuracy)
learn = learn.load(“Filename”)
now all the above works in the original notebook i developed and trained in
however, when i try to load the weights in the copy it gives an error
[the SAME code in the original notebook does not give an error!!]
To make sure it worked, i copied the original code to a new notebook
shut down jupyter, and then used the new notebook to reconstruct the net
and use the pred = learn.predict(df.iloc[3227]) code, and it worked…
i will work on the error, but here it is just so others can see what happened…
remember, i copied everything from a working model, including the sizes and even loaded in a tiny bit of data (just to get by without changing code)
RuntimeError Traceback (most recent call last)
in
----> 1 learn = learn.load(“Filename”)
C:\Anaconda3\lib\site-packages\fastai\basic_train.py in load(self, file, device, strict, with_opt, purge, remove_module)
271 model_state = state[‘model’]
272 if remove_module: model_state = remove_module_load(model_state)
→ 273 get_model(self.model).load_state_dict(model_state, strict=strict)
274 if ifnone(with_opt,True):
275 if not hasattr(self, ‘opt’): self.create_opt(defaults.lr, self.wd)
C:\Anaconda3\lib\site-packages\torch\nn\modules\module.py in load_state_dict(self, state_dict, strict)
828 if len(error_msgs) > 0:
829 raise RuntimeError(‘Error(s) in loading state_dict for {}:\n\t{}’.format(
→ 830 self.class.name, “\n\t”.join(error_msgs)))
831 return _IncompatibleKeys(missing_keys, unexpected_keys)
832
RuntimeError: Error(s) in loading state_dict for TabularModel:
size mismatch for embeds.0.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([133, 25]).
size mismatch for embeds.1.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([145, 26]).
size mismatch for embeds.2.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([147, 26]).
size mismatch for embeds.3.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([143, 26]).
size mismatch for embeds.4.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([138, 25]).
size mismatch for embeds.5.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([146, 26]).
size mismatch for embeds.6.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([148, 26]).
size mismatch for embeds.7.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([144, 26]).
size mismatch for embeds.8.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([145, 26]).
size mismatch for embeds.9.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([139, 25]).
size mismatch for embeds.10.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([149, 26]).
size mismatch for embeds.11.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([139, 25]).
size mismatch for embeds.12.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([148, 26]).
size mismatch for embeds.13.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([152, 27]).
size mismatch for embeds.14.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([145, 26]).
size mismatch for embeds.15.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([143, 26]).
size mismatch for embeds.16.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([140, 25]).
size mismatch for embeds.17.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([153, 27]).
size mismatch for embeds.18.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([137, 25]).
size mismatch for embeds.19.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([152, 27]).
size mismatch for embeds.20.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([149, 26]).
size mismatch for embeds.21.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([145, 26]).
size mismatch for embeds.22.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([141, 26]).
size mismatch for embeds.23.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([143, 26]).
size mismatch for embeds.24.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([145, 26]).
size mismatch for embeds.25.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([147, 26]).
size mismatch for embeds.26.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([141, 26]).
size mismatch for embeds.27.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([149, 26]).
size mismatch for embeds.28.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([143, 26]).
size mismatch for embeds.29.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([144, 26]).
size mismatch for embeds.30.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([135, 25]).
size mismatch for embeds.31.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([147, 26]).
size mismatch for embeds.32.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([164, 28]).
size mismatch for embeds.33.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([143, 26]).
size mismatch for embeds.34.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([146, 26]).
size mismatch for embeds.35.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([137, 25]).
size mismatch for embeds.36.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([144, 26]).
size mismatch for embeds.37.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([149, 26]).
size mismatch for embeds.38.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([143, 26]).
size mismatch for embeds.39.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([143, 26]).
size mismatch for embeds.40.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([147, 26]).
size mismatch for embeds.41.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([143, 26]).
size mismatch for embeds.42.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([149, 26]).
size mismatch for embeds.43.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([135, 25]).
size mismatch for embeds.44.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([148, 26]).
size mismatch for embeds.45.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([136, 25]).
size mismatch for embeds.46.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([140, 25]).
size mismatch for embeds.47.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([143, 26]).
size mismatch for embeds.48.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([153, 27]).
size mismatch for embeds.49.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([133, 25]).
size mismatch for embeds.50.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([144, 26]).
size mismatch for embeds.51.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([151, 27]).
size mismatch for embeds.52.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([141, 26]).
size mismatch for embeds.53.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([137, 25]).
size mismatch for embeds.54.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([152, 27]).
size mismatch for embeds.55.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([147, 26]).
size mismatch for embeds.56.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([154, 27]).
size mismatch for embeds.57.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([139, 25]).
size mismatch for embeds.58.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([140, 25]).
size mismatch for embeds.59.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([150, 26]).
size mismatch for embeds.60.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([149, 26]).
size mismatch for embeds.61.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([136, 25]).
size mismatch for embeds.62.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([133, 25]).
size mismatch for embeds.63.weight: copying a param with shape torch.Size([257, 36]) from checkpoint, the shape in current model is torch.Size([142, 26]).
size mismatch for layers.0.weight: copying a param with shape torch.Size([250, 2304]) from checkpoint, the shape in current model is torch.Size([250, 1656]).
and i am NOT trying to do batch…
each request is singular… so i cant batch them…
i have to answer single requests in a row…
so the code above will work…
its just not pretty…
(once i figure out why the load is giving the error… and yes, i know it says its different, but its not, its an exact copy from the working model, and matches a copy of a copy to make sure)
thanks…
this is great…
so close, but yet so far