i think there is a huge communication gulf here…
i am not using this on a website… never said website… go search the thread and no one said website
so that is assuming (remember the trope that goes with it and seems to be true here)
maybe there are deployment examples…
but so far i have not found the core of it…
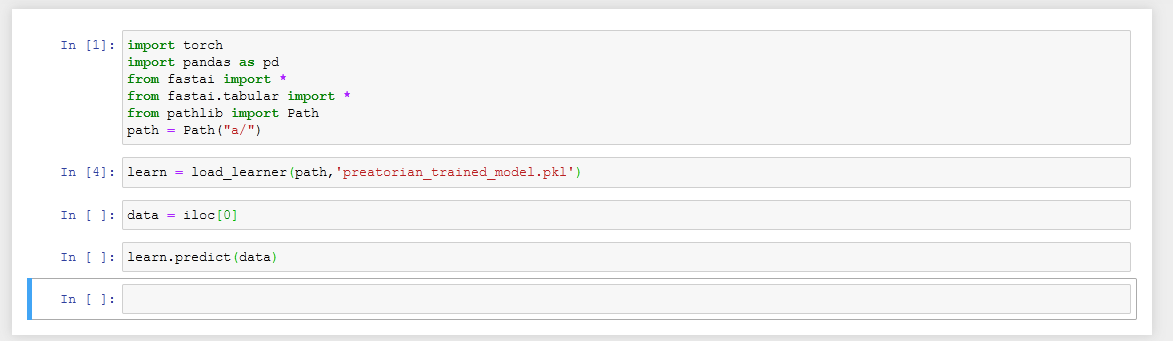
i saved my net… with learn.save(‘filename’)
now i should have used learn.export? ok. fine
but now… where is the example code of instantiating the empty net and loading it?
if it was so easy… why hasnt anyone in this whole thread pointed to the 25 lines of code?
to create a nn, load in data, and restore its weights takes only this
import torch
import pandas as pd
from fastai import *
from fastai.tabular import *
from pathlib import Path
path = Path(“a/”)
df = pd.read_csv(path / ‘lg_binaryol.txt’)
dep_var = ‘Target’
cat_names = [‘col1’,‘col2’,‘col3’,‘col4’,‘col5’,‘col6’,‘col7’,‘col8’,‘col9’,‘col10’,‘col11’,‘col12’,‘col13’,‘col14’,‘col15’,‘col16’,‘col17’,‘col18’,‘col19’,‘col20’,‘col21’,‘col22’,‘col23’,‘col24’,‘col25’,‘col26’,‘col27’,‘col28’,‘col29’,‘col30’,‘col31’,‘col32’,‘col33’,‘col34’,‘col35’,‘col36’,‘col37’,‘col38’,‘col39’,‘col40’,‘col41’,‘col42’,‘col43’,‘col44’,‘col45’,‘col46’,‘col47’,‘col48’,‘col49’,‘col50’,‘col51’,‘col52’,‘col53’,‘col54’,‘col55’,‘col56’,‘col57’,‘col58’,‘col59’,‘col60’,‘col61’,‘col62’,‘col63’,‘col64’]
cont_names =
procs = [FillMissing, Categorify, Normalize]
testpct = int(len(df) * .10)
valpct = int(len(df)* .20)
trainpct = int(len(df) * .70)
test = TabularList.from_df(df.iloc[-testpct:-1].copy(), path=path, cat_names=cat_names, cont_names=cont_names)
data = (TabularList.from_df(df, path=path, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(list(range(valpct,trainpct)))
.label_from_df(cols=dep_var)
.add_test(test)
.databunch())learn = tabular_learner(data, layers=[250,400], metrics=accuracy)
learn = learn.load(savenetII01")
less than 25 lines to be ready to make it learn more, or play with it, and such
it should take LESS than that to import, create a empty net of structure, load structure, load weights and be ready to answer… by sending just a list the same size as the data trained (without a target).
it shouldn’t matter if i am using it in a web app, or on my desk, or in a phone, etc…
because with that core, you could use it anywhere you could run python…
that’s all i have been asking for since the beginning…
because that core can be inserted where its needed…
in my case, inside someone elses framework i have to use
in another case, maybe as a python module called by a coldfusion/java program on a website
in another case, on a phone… or tablet phablet…
all the other stuff around that request has nothing to do with the essential
and thats what i been trying to get at.
how to make a empty shell that matches the training structure, load in whats needed, and then be able to query that to get outputs…
i will look at lesson two…
hopefully the 15 line of code i need are there… (given you can amazingly do most everything else with less than 25 lines… thats incredible!!! )… maybe you guys are overthinking what should be an easy answer… what should be a tiny how to post…
once i figure it out, i will do that post…
but i have to get there from here…
thanks, you guys been great…
but it still boggles the mind (of someone who has been writing code since the late 1970s professionally)
=========================
imagine this all was completed… there is no more training… there is no more test set…
there is only what core remains to be used… THAT is what i am looking for…
of course the first post apologizes that i have not learned the lingo in 3.5 days
so i dont know to use the word inference…
or that learn.save and learn.export are two different things (are they?)
but whatever is around the core code that does the work AFTER all the creation and testing is done
is not relevant… that, as you say, is up to the person deploying that core…
but so far, i have not found that easy answer without all the other stuff around it
its like you cant tell me how to install a water heater without first telling me how to build a house!
and i made a mistake above… been writing code since the late 1970s…
been doing it professionally since about 1984-1985 - about 35 years…
so i am not a dunce when it comes to this stuff… as i am still writing code and learning new stuff
dont get me wrong… what is here is amazing… really it is… (and i am a tough critic)
but whats missing is the easy core without the distracting costume on the outside
the naked person, not the person in a suit, a sari, a samurai outfit, etc…
thanks… i do appreciate it… i am just a bit frustrated…
=======================================
i just looked at Create a Learner for inference…
its still about validation and training… not consumption…
i went through all the text of lesson 2… nothing about after all the work is done what to do to have a naked system to wrap with what you need…
Create a Learner for inference…
third sentence in the tutorial
Now that our data has been properly set up, we can train a model. We already did in the look at your data tutorial so we’ll just load our saved results here.
i dont want to train it… its trained… i dont want to test it, its tested
i want what comes AFTER that… using it without training or testing any more…
at the bottom is the tabular example…
it shows how to load in your whole thing again, with training and test
notice data on top has valid_idx = range (800,1000) which is for the adult database it says above it
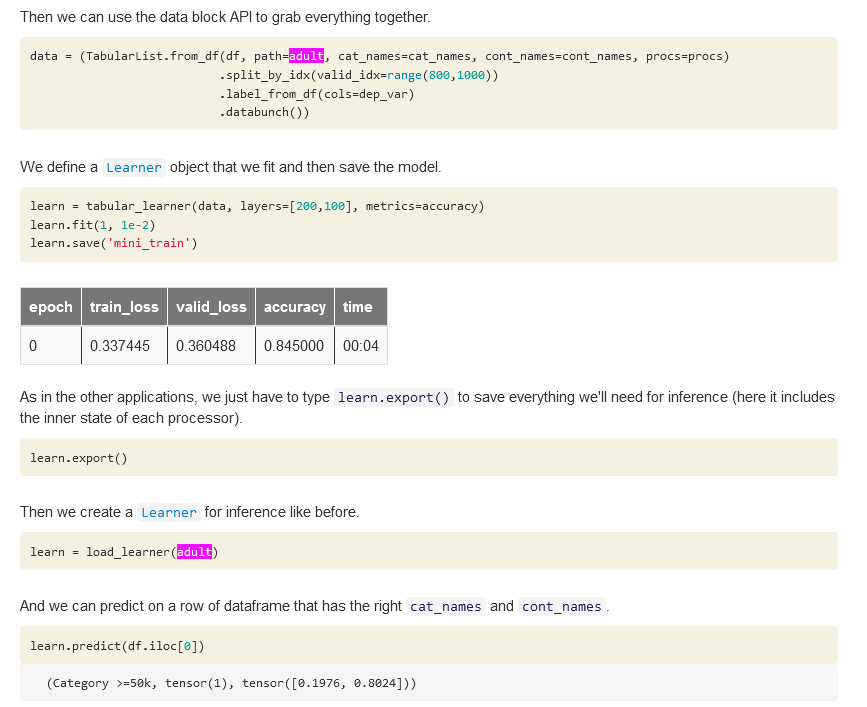
it has learn fit after that… which trains the network, no?
then it says learn.export()… should that be alone or learn.export(‘filename’)
because after that, it says load learner adult…
above it adult is the file adult = untar_data(URLs.ADULT_SAMPLE) from adult
why is that needed for deploy?
and then it calse predict… but its looking for one of the loaded adult data…
its not a simple string someone puts in to get an answer…
so the example you told me to look at doesnt have what you claim it has…
i wouldnt be bothering anyone if it did…