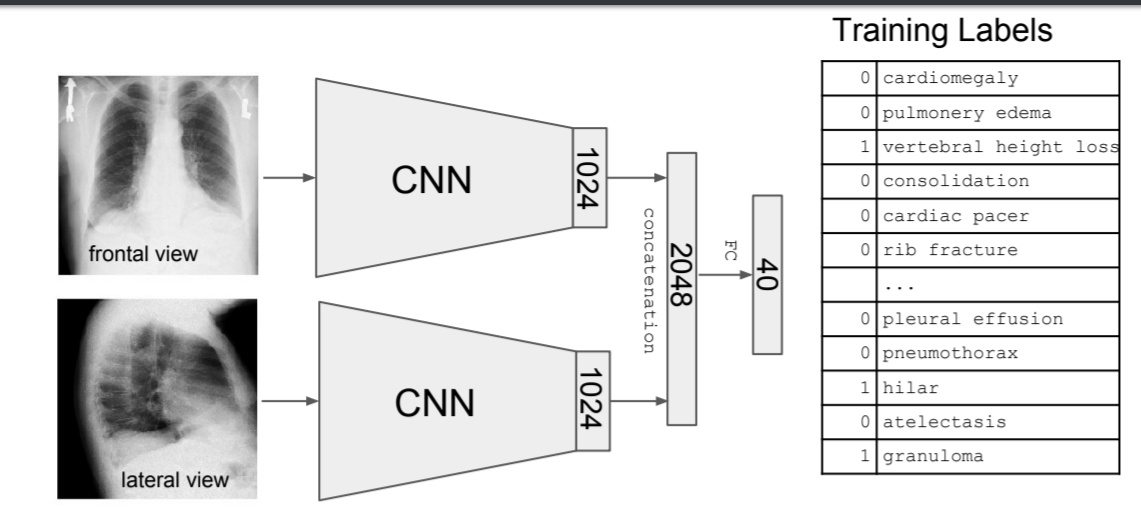
There are ML problems when we need to stack more than one model. Take for example chest X-Rays need stacking 2 CNNs for front and lateral views like this model :
Because the output of each CNN in the 1st image has way more features describing each xray image, which is crucially important…
Since the physician will not be able to classify with the frontal view alone or the lateral view alone.
We need to combine (stack) features and not label outputs.
I mean the 2nd image is just like if you give the front view xray to physician1 and give the lateral view to phyisician2 and average their decisions. It is not a good idea because neither physician1 nor physician2 will be able to give a good diagnosis with only one xray view. It needs combining a lot of features in one model just like in the 1st image.
The paper mentioned how they trained the model: We start by applying a CNN (DenseNet121[5]) on the Lateral and PA views (separately). We removed the last fully connected layer from each CNN and concatenated their outputs (just after the average pooling layer).
I’ve been thinking about @hwasiti’s question too. I think I can understand the part regarding using a custom head, but how would you join the 2 separately-trained convnet into one NN? That part I’m a bit confused.
Not to forget that it may be necessary to fine-tune the combined network, hence the backprop has to go from the loss function to both inputs. Can helpto explain more?
@TheShadow29 Many thanks for the time to write that! I had the same question of @wyquek but I thought people are doing training of such custom CNN models in two stages.
I thought, first they would train the multiple input models (CNN in our example) separately on the training data just like when you train a single vanilla CNN model on the training data. Then they would cut their heads and pass all the training data to get the activations of these CNNs. The activations are then stacked and passed as training data on the custom head NN (FC NN in our case).
In fact I believe there are custom heads that are not NN like XGBoost and perhaps the only choice is this two step training (I am happy to be corrected if this is not the case).
For the xray model above the author of the paper states:
Model Our model, called TextRay, is illustrated in Fig. 1. We start by applying a CNN (DenseNet121[5]) on the Lateral and PA views (separately). We removed the last fully connected layer from each CNN and concatenated their outputs (just after the average pooling layer). We then applied our own fully-connected layer resulting in K = 40 outputs, one for each finding, followed by a sigmoid activation.
which I understand they made it in two steps.
However for NN custom_heads I think your solution seems more elegant. I am very curious, do you remember Jeremy showed such code like yours to combine custom_head with an input and train them all in one step?
I want to decide whether to rush to study part 2 if it needed for solving such type of problems. Since, I have a similar model I need to train.
The cifar notebook is kinda similar to Shadow’s solution, like how the resnet layer or batchnorm layer was built separately, then brought into the main NN. Something like this:
class ConvNet2(nn.Module):
def __init__(self, layers, c):
super().__init__()
self.layers = nn.ModuleList([ConvLayer(layers[i], layers[i + 1])
for i in range(len(layers) - 1)])
self.out = nn.Linear(layers[-1], c)
def forward(self, x):
for l in self.layers: x = l(x)
x = F.adaptive_max_pool2d(x, 1)
x = x.view(x.size(0), -1)
return F.log_softmax(self.out(x), dim=-1)```
What I couldn’t figure out was how to bring in two separate models into the bigger model, as @TheShadow29 has shown. I still have a sketchy idea, but I think it would be clearer to me once I am able to wrap my head around DL2 better. But DL2 will take time to digest.
As for the codes, @TheShadow29 seems pretty conversant with pytorch. Hopefully he would enlighten us further.
You may also want to reconsider doing a simple concat - you’re throwing away spatial information.
Something at the top of the frontal image will roughly correspond to something at the top of the lateral image. It might be better to concatenation along a new dimension and doing a 2D convolution rather than a normal concat and a fully connected layer.
You should also consider sharing weights between the frontal and lateral networks, at least for early layers, since they are processing similar data.
I did something like this for CC and MLO mammograms in Keras, don’t have working pytorch code for it yet.
I didn’t note it was done separately. In that case it is best to save the features to disk. So you could do something like
out = model1(inp)
save_output(out, fnames)
And then use these features to train the final fc layers. So in a separate file learn.model = nn.Sequential(nn.Linear(*args), nn.ReLU(), nn.Linear(*args2))
If you need a slightly inefficient way then taking from the earlier example:
detach would prevent backward flow. However, do note you are doing the forward pass multiple times, so best to save it to a disk. However, that would require you to redefine your Dataset, especially the __getitem__ function.
There are some efficient ways to do that. I think in previous versions fastai used bcolz which might be worth exploring for fast reading of numpy arrays. A not so good version of doing this is https://github.com/TheShadow29/FAI-notes/blob/master/notebooks/Using-Forward-Hook-To-Save-Features.ipynb (especially the last part of saving and loading the features).
Do note that with new pytorch and fastai versions, some of it is outdated, so might not work out of the box.
You would pool along the horizontal dimension to get a dimension of 1 horizontal, 7 vertical or whatever the output size of your network is.
You would then add a convolutional layer or two on what would now be 2x7 or 7x2 depending on your image orientation. (Would obviously not be able to use a 3x3 kernel.)
Just curious, when you did your data-augmentation for the lateral images, do you perform anything special other than the usual transforms_side_on ? For example, in fastai normal images we do transforms_side_on, saterlite images we do transforms_top_down…
It seems like the more optimal approach would be to jointly model these images. Flipping would then be OK, so long as if one is flipped then the other is also flipped. That is, it would preserve the spatial co-dependence. However, it is much easier for me to say offhand that than to actually produce a model reflecting that viewpoint.
I don’t have the dataset, but reading that paper made me curious how such models can be built using fastai. And this is not the first time I see such models. A lot of kaggle comp winners used such complex models. I don’t remember where though. But this is something that intrigued me for so long…