Thank you for the excellent post @oguiza
Here is an examples for (1):
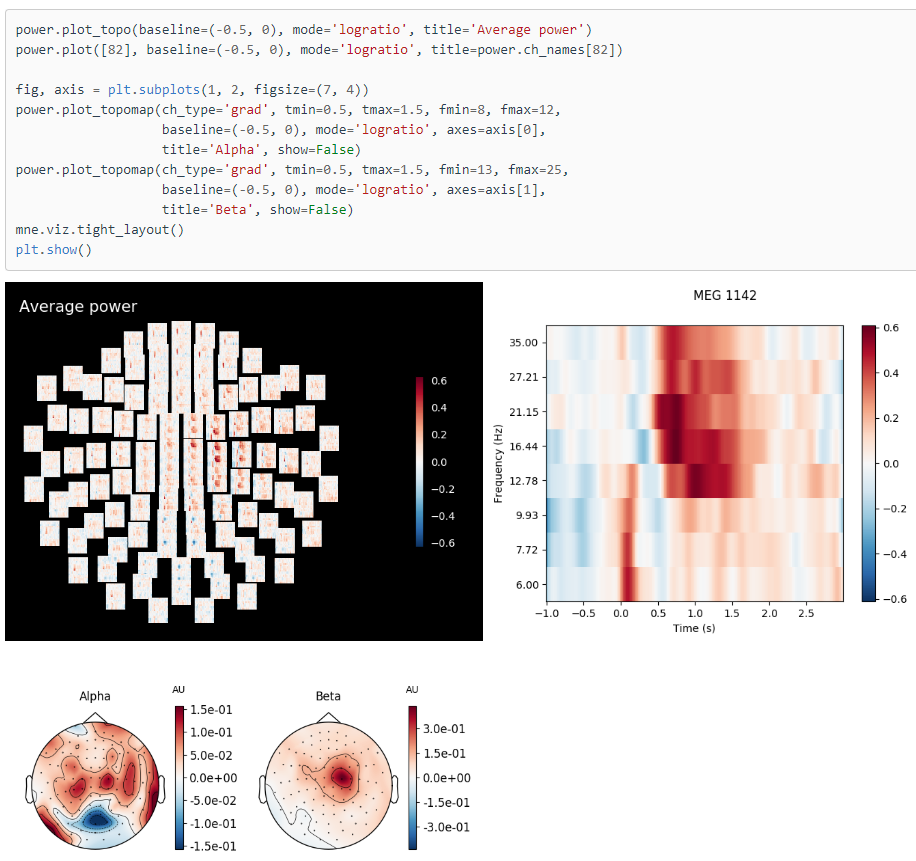
This is something I am working one. Multiple EEG sensors on the scalp. So this is an example of multi-variate time series (each electrode position will pick up a signal that we are interested in its spectrograms, so we have 64 spectrograms). Have a look into the image with the black background :