I am using the fast-ai library in order to train a sample of the IMDB reviews dataset. I want to use it for sentiment analysis and I have trained the model in a VM by using this tutorial.
I saved the data_lm and data_clas models, then the encoder ft_enc and after that I saved the classifier learner sentiment_model. I, then, got those 4 files from the VM and put them in my machine and wanted to use those pretrained models in order to classify sentiment.
This is what I did:
# Use the IMDB_SAMPLE file
path = untar_data(URLs.IMDB_SAMPLE)
# Language model data
data_lm = TextLMDataBunch.from_csv(path, 'texts.csv')
# Sentiment classifier model data
data_clas = TextClasDataBunch.from_csv(path, 'texts.csv',
vocab=data_lm.train_ds.vocab, bs=32)
# Build a classifier using the tuned encoder (tuned in the VM)
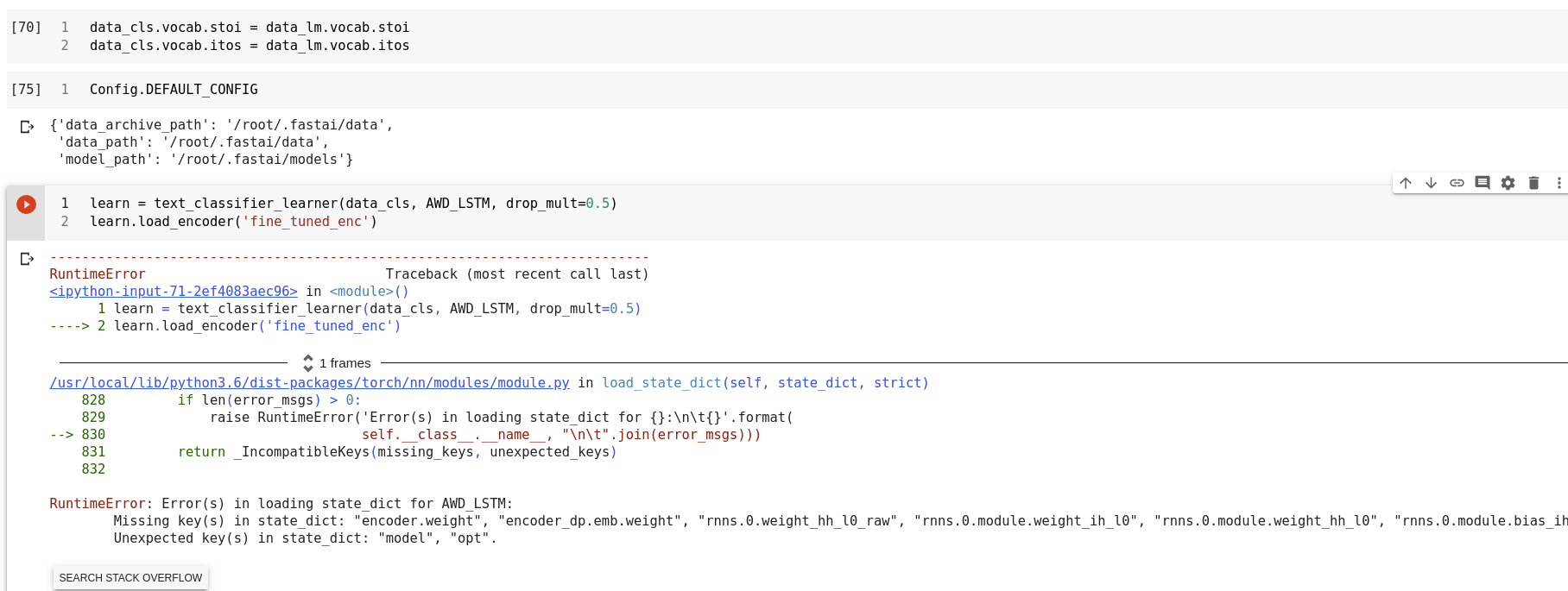
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
learn.load_encoder('ft_enc')
# Load the trained model
learn.load('sentiment_model')
After that, I wanted to use that model in order to predict the sentiment of a sentence. When executing this code, I ran into the following error:
RuntimeError: Error(s) in loading state_dict for AWD_LSTM:
size mismatch for encoder.weight: copying a param with shape torch.Size([8731, 400]) from checkpoint, the shape in current model is torch.Size([8888, 400]).
size mismatch for encoder_dp.emb.weight: copying a param with shape torch.Size([8731, 400]) from checkpoint, the shape in current model is torch.Size([8888, 400]).
And the Traceback is:
Traceback (most recent call last):
File "C:/Users/user/PycharmProjects/SentAn/mainApp.py", line 51, in <module>
learn = load_models()
File "C:/Users/user/PycharmProjects/SentAn/mainApp.py", line 32, in load_models
learn.load_encoder('ft_enc')
File "C:\Users\user\Desktop\py_code\env\lib\site-packages\fastai\text\learner.py", line 68, in load_encoder
encoder.load_state_dict(torch.load(self.path/self.model_dir/f'{name}.pth'))
File "C:\Users\user\Desktop\py_code\env\lib\site-packages\torch\nn\modules\module.py", line 769, in load_state_dict
self.__class__.__name__, "\n\t".join(error_msgs)))
So the error occurs when loading the encoder. But, I also tried to remove the load_encoder line but the same error occurred at the next line learn.load('sentiment_model').
I searched through the fast-ai forum and noticed that others also had this issue but found no solution. In this post the user says that this might have to do with different preprocessing, though I couldn’t understand why this would happen.
Could anyone please help me with that issue. I have tried many different things but I cannot find something to get past this. Any help would be appreciated.
 Has anyone else come up with any solutions to this problem?
Has anyone else come up with any solutions to this problem?