Hi all,
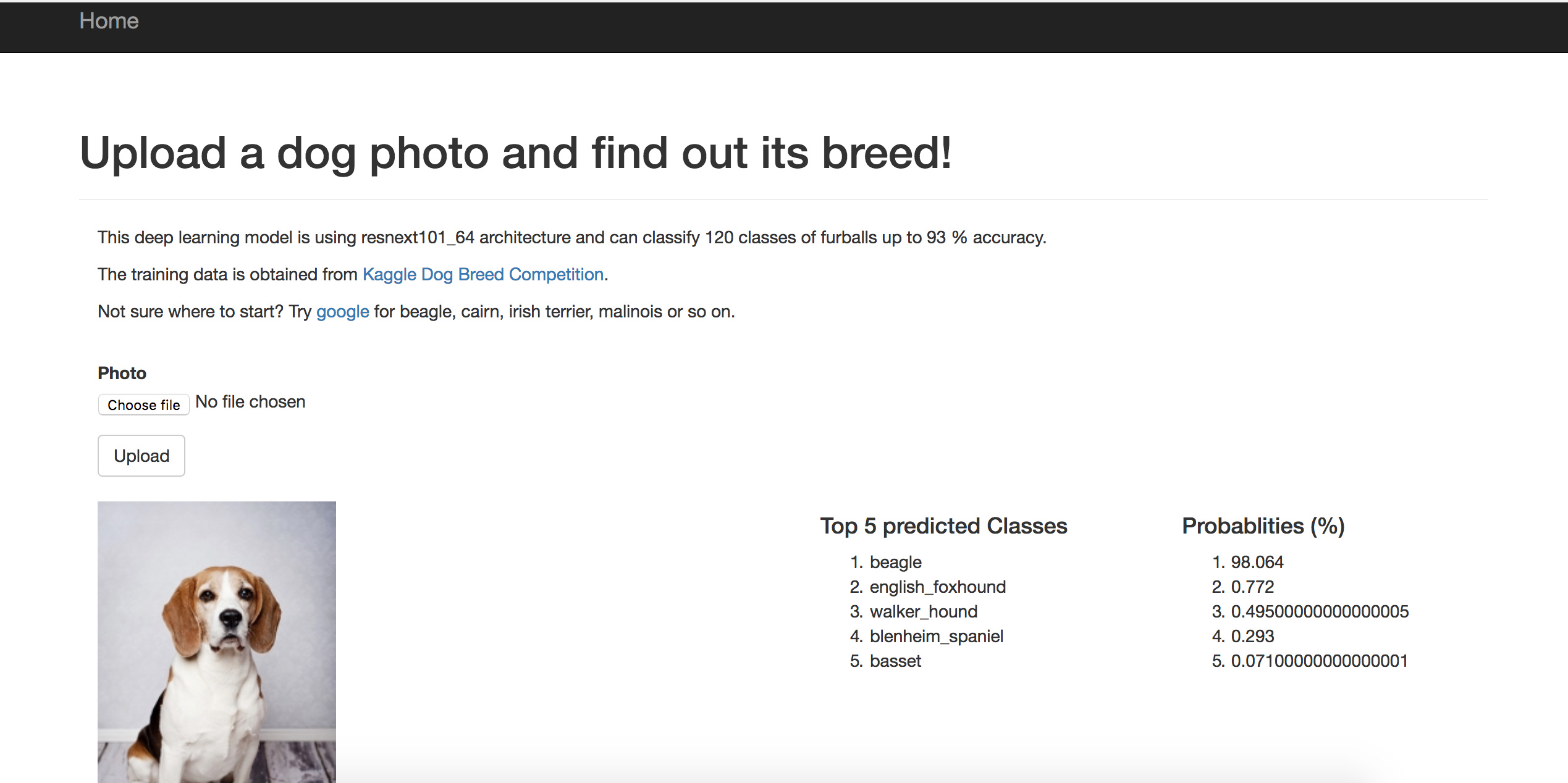
I have created a simple web application built with just Flask and Fastai based on Kaggle Dog Breed Identification that allows user to upload a photo, and then model will predict the the classes of the dogbreeds. I have successfully run it on my local machine, but am having difficulties to host it on Heroku.
Not sure why the torch package cannot be found. Will try to downgrade to version 0.1.2, 0.1.2.post1 and try again.
Collecting torch==0.3.0.post4 (from -r /tmp/build_e09cdcbfaa2f8952363f0a52ea14bf40/requirements.txt (line 78))
Could not find a version that satisfies the requirement torch==0.3.0.post4 (from -r /tmp/build_e09cdcbfaa2f8952363f0a52ea14bf40/requirements.txt (line 78)) (from versions: 0.1.2, 0.1.2.post1)
No matching distribution found for torch==0.3.0.post4 (from -r /tmp/build_e09cdcbfaa2f8952363f0a52ea14bf40/requirements.txt (line 78))
-
Does anyone has experience deploying it to heroku or other cloud providers (AWS, google cloud, pythonanywhere, digital ocean)?
-
For this application, I am using the following approach, load the resnext model, load pretrained weights, and perform forward passing for prediction.
arch = resnext101_64 #load pretrained model learn = ConvLearner.pretrained(arch, data, precompute=False) #load trained weights learn.load('224_pre_resnext101_64')This would require the application to load the pertained weights (330 MBs) and trained weights (330 MBs). This has made the application to be too huge and deployment painfully slow.
Is there a way where we can import the model without using ConvLearner.pretrained ? (I am hoping to omit the pretrained weights). I have tried ConvLearner.from_model_data, but it does not work in this case.
Thanks a lot.


