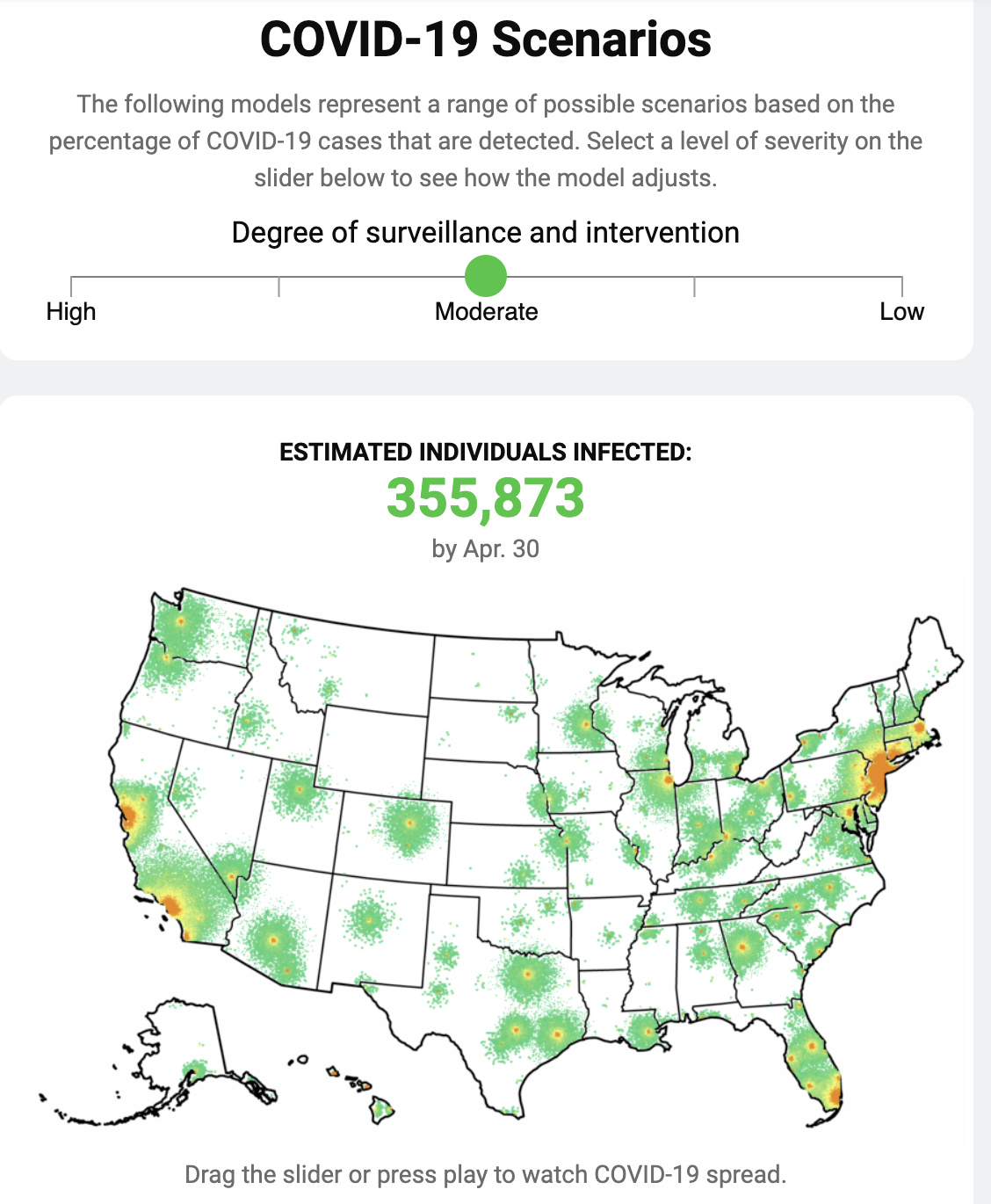
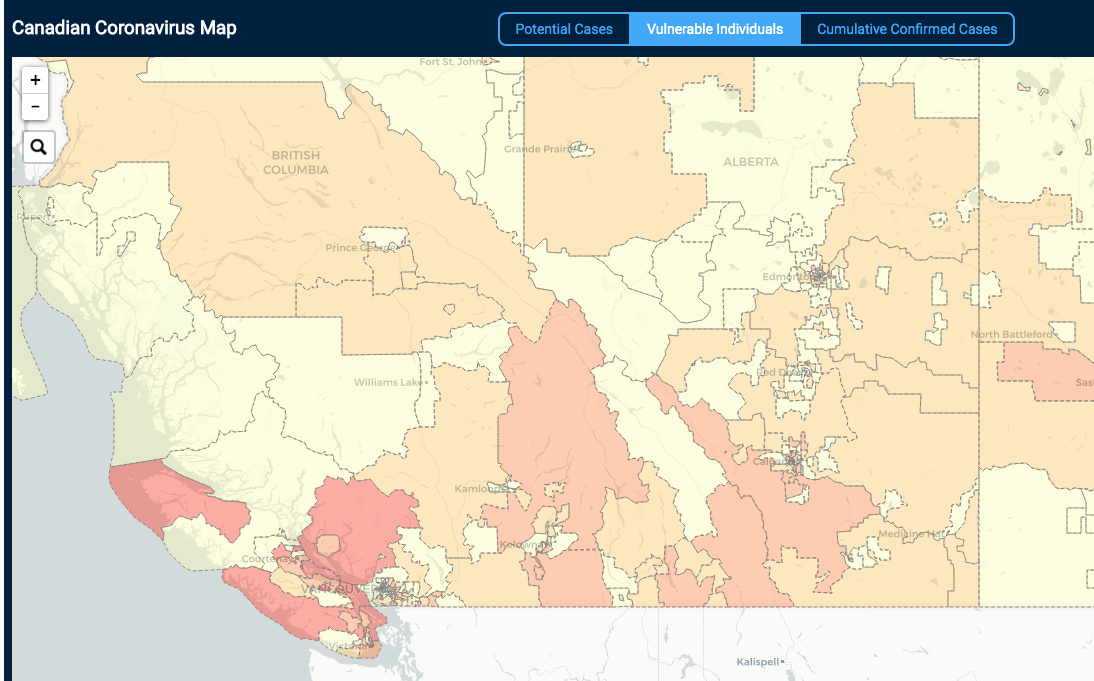
Hi @MadeUpMasters,
This looks so useful and promsing. Thank you and your team for doing this work.
My group of volunteers and I (mostly geospatial data science folks) are working on something very complementary. I just shared some info about it here: Mapping US health system capacity (ICU care in particular) for COVID19 surge preparedness
Re:
- We have a dataset of every hospital and # of beds, how do we best utilize it?
- How can we utilize data about how hospitals will adjust over time (more ICU beds created, elective procedures ceased…etc)?
and
@jordan’s
- Healthcare Service Capacity – “chance that my healthcare system can take care of me”
- Hospitals (preferably Available Beds) per square mile
- Possibly Medical staff per square mile
- Possibly Medical funding per square mile
We’re focused on exactly this part of the problem - to define our current local health systems’ capacity to care for critically ill COVID19 patients (amidst the usual demand of non-COVID patients who also need ICU care), and estimate what their potential is to ramp up surge ICU capacity over what time period, in what spatial distributions across the country, under what scenarios.
We started off with a similar hospital facilities dataset from Medicare called HCRIS which gives the facility-level details but also importantly, the number of and usual occupancy rates of ICU beds. Based on this (and joining it with the HIFLD dataset you have, thank you for that lead!), we will have all hospital facilities geolocated and with relatively current stats about occupied (staffed) and max potential (licensed) ICU and general med/surg beds. We’re working on publishing this in the next days as a cleaned up, validated, open, and easily consumable dataset for your and other epi/risk modelers’ needs.
Then we’ll work on estimating the max capacity of ICU care per facility and per capita in an area based on what resource bottlenecks need to be relieved in different facilities, counties, states, regions. Lifting these constraints include timely and appropriately sized dispatching of scarce resources like staffing (critcare nurses, respiratory technicians), equipment (ventilators, ECMOs), available ICU beds (or conversion of general beds), etc.
The project idea is for us to focus on this one critical part of the overall problem (mapping current and projected supply of intensive care capacity in high spatiotemporal detail) and collaborate with other work like yours to paint the full picture of how rapidly growing case loads (that high peaking demand curve) meets our available/prepared healthcare capacity in different locations and times, how far past that capacity the demand will exceed, and what we need to do to prepare to fill that delta.
Anyways, really happy to see your work and look forward to talking more about how to sync up efforts!
Dave