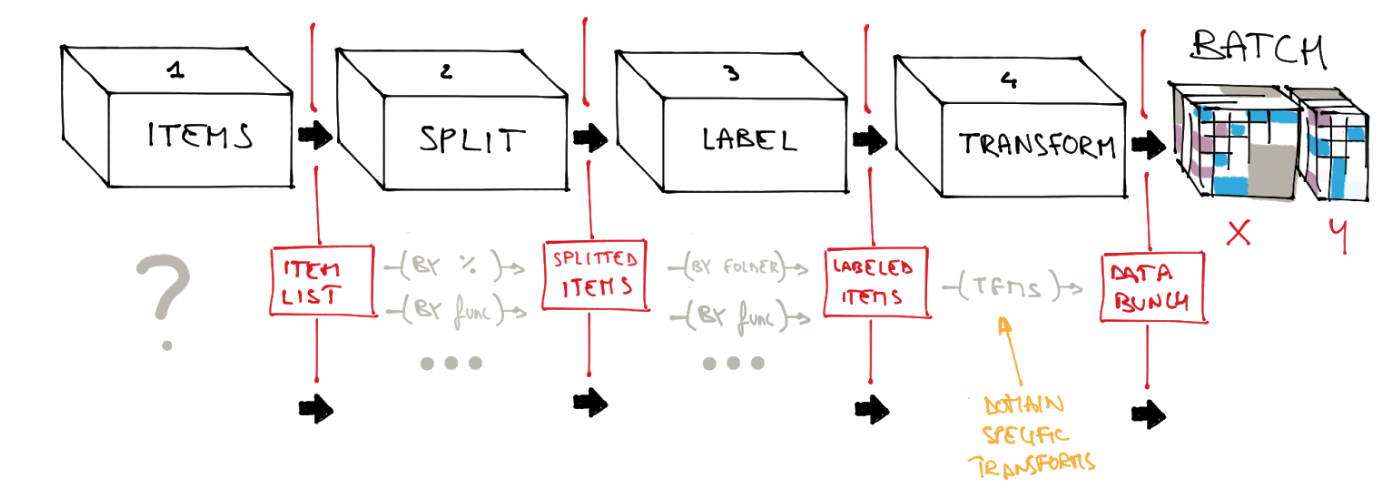
One of the best part of actual python data block api is it’s expressiveness:
databunch = itemsFromWhatever(...)
.splitWithWhatever(...)
.labelWithWhatever(...)
.transform(tfms)
.optionallyAddTest(...)
.databunch(...)
That gives you the perception to control anything.
In swift I would expect something like this:
databunch = items
>| splitWithWhatever(...) // -> TrainTestSplitted
>| labelWithWhatever(...) // -> TrainTestLabeled
>| addTransform(tfms) // -> TrainTestLabeledWithTfms
>| optionallyAddTest(...) // -> TrainTestLabeledWithTfmsAndTest
>| databunch(...)
With the big advantage that all of these are (possibly pure) functions!