Hello,
I am following the guidance here: https://course.fast.ai/start_gcp.html
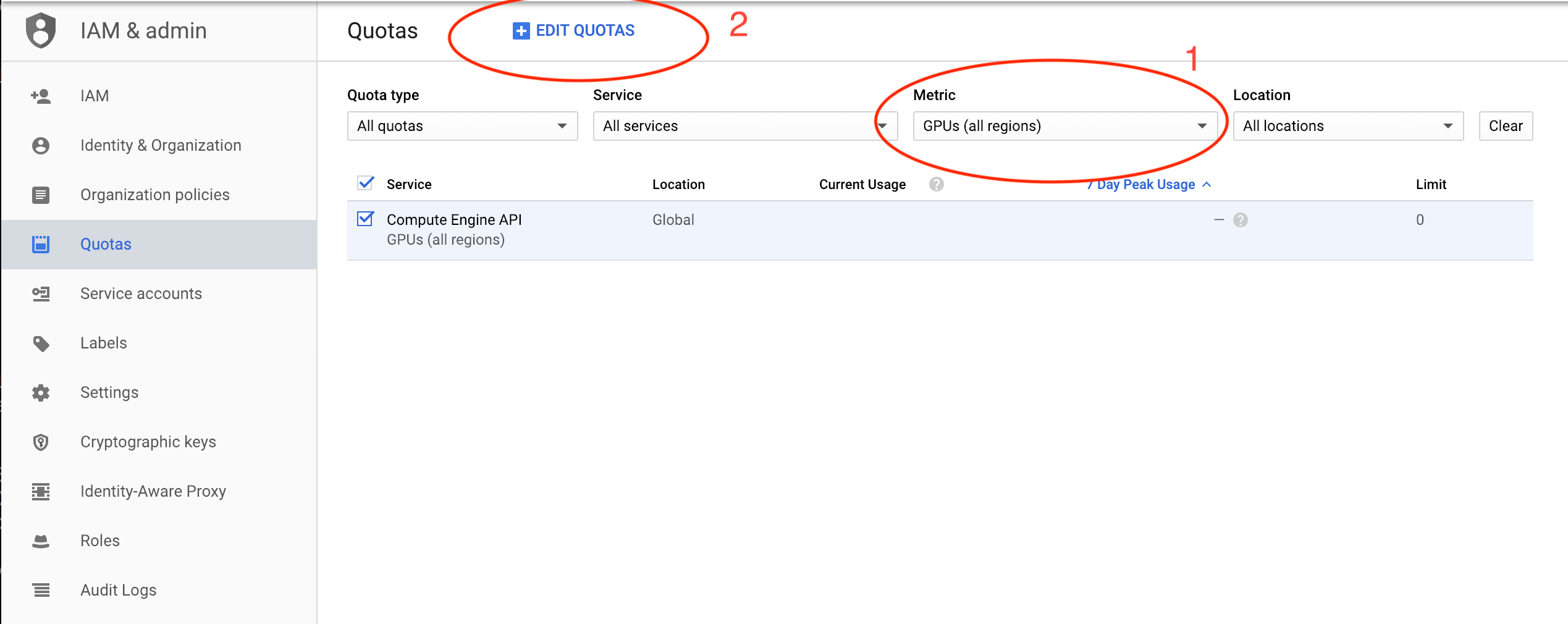
Is anyone else having quota problems with GCP when trying to set up an instance?
$export IMAGE_FAMILY=“pytorch-latest-gpu”
$export ZONE=“us-west2-b”
$export INSTANCE_NAME=“my-fastai-instance”
$export INSTANCE_TYPE=“n1-highmem-8”
$gcloud compute instances create $INSTANCE_NAME
–zone=$ZONE
–image-family=$IMAGE_FAMILY
–image-project=deeplearning-platform-release
–maintenance-policy=TERMINATE
–accelerator=“type=nvidia-tesla-p4,count=1”
–machine-type=$INSTANCE_TYPE
–boot-disk-size=200GB
–metadata=“install-nvidia-driver=True”
–preemptible
I receive this error in return:
ERROR: (gcloud.compute.instances.create) Could not fetch resource:- Quota ‘GPUS_ALL_REGIONS’ exceeded. Limit: 0.0 globally.
What quota do I change on the free account in ‘IAM and accounts’ > ‘Quotas’? I would like to have Standard Compute + Storage
I have linked my billing account to the project.
Thank you for any advice in advance.
Rachel