It’s not a copy&paste solution but I think these posts should provide you with all the ingredients. I guess the main point for you is that you the need the ds_idx instead of of just iterating of .items.
@haverstind, I checked both of the linked posts, but it seems to me that there what you did was filtering a subset of the predictions so that’s why you needed to keep track of the indices. If no filtering is done in your loops, then i == ds_idx for all entries, and so it’s not really doing anything, I just tried to follow those snippets, but I am still getting inconsistent columns:
Could you please spell out what you had in mind, maybe I misunderstood?
That’s the pr. The code I showed is how I got the filenames associated with when two classes matched. You should be able to extrapolate it from there. Source code link should be there too for my github as well.
I’m using 1.0.44 os I don’t have the class that you are using there. But surely it can’t be that hard zipping together preds and fnames? This such a frustrating thing it should be a no brainer…
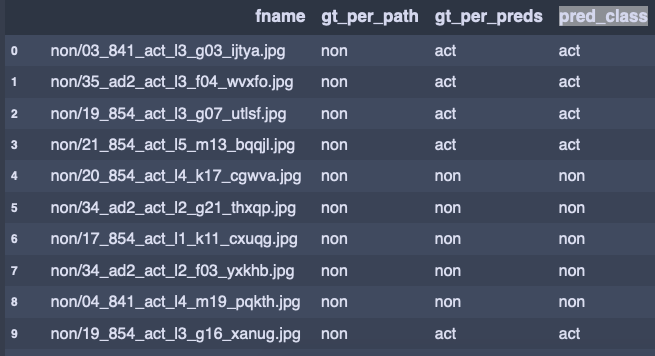
 Here is how I extrapolated:
Here is how I extrapolated: