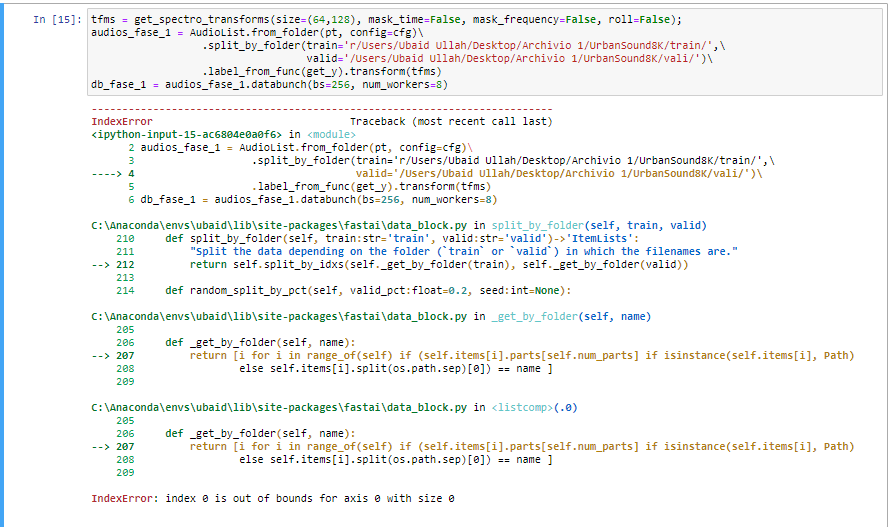
I’ve spent > 8 hours tracking this down. Why aren’t the predictions in the order of the test set?
import fastai
print(fastai.__version__)
1.0.59
I have a MNIST dataset in the proper folder format
train/
0/
1/
2/
:
:
9/
valid/
0/
1/
2/
:
:
9/
test/
testimg_00000.jpg
testimg_00001.jpg
:
:
testimg_27999.jpg
Using the preferred data_block API
path = Path('/kaggle/working/data')
data = (ImageList.from_folder(path)
.split_by_folder()
.label_from_folder()
.add_test_folder(path/'test')
.databunch())
data
gives
ImageDataBunch;
Train: LabelList (39900 items)
x: ImageList
Image (3, 28, 28),Image (3, 28, 28),Image (3, 28, 28),Image (3, 28, 28),Image (3, 28, 28)
y: CategoryList
4,4,4,4,4
Path: /kaggle/working/data;
Valid: LabelList (2100 items)
x: ImageList
Image (3, 28, 28),Image (3, 28, 28),Image (3, 28, 28),Image (3, 28, 28),Image (3, 28, 28)
y: CategoryList
4,4,4,4,4
Path: /kaggle/working/data;
Test: LabelList (28000 items)
x: ImageList
Image (3, 28, 28),Image (3, 28, 28),Image (3, 28, 28),Image (3, 28, 28),Image (3, 28, 28)
y: EmptyLabelList
,,,,
Path: /kaggle/working/data
The item counts indicate that all is good! However, when I try to predict from a learner, it is evident that the test set is not ordered correctly. This can be seen by indexing the test set:
data.test_ds.x[0]

and then
i = 0
img = imageio.imread(str(f'/kaggle/working/data/test/testimg_{str(i).zfill(5)}.jpg'))
plt.imshow(img);
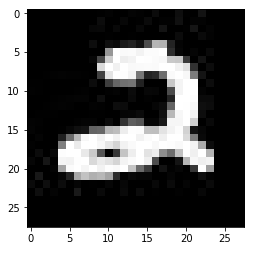
Why would these not be the same image? The file creation dates are in the order of the filenames. They are just created with:
for i in range(len(test)):
imageio.imsave(str(path / f'testimg_{str(i).zfill(5)}.jpg'), test[i])
I was wondering why my validation accuracy was 0.99+ but the Kaggle leaderboard score of the submission was 0.10… The test order is “randomly” scrambled. I confirm that it’s correct above that
If
- you need to predict the test set from a learner in the order of a Kaggle submission file
- your test files alphabetical in the proper order (for example, are of the form
f'testimg_{str(i).zfill(5)}.jpg' like testimg_00133.jpg)
this will do the trick:
preds, _ = learn.get_preds(ds_type=DatasetType.Test)
labels = np.argmax(preds, 1)
test_index = []
num = len(learn.data.test_ds)
for i in range(num):
test_index.append(str(learn.data.test_ds.items[i]).split('/')[-1])
df = (pd.DataFrame(data={"Label": labels, "Filename": test_index})
.sort_values(by='Filename')
.drop('Filename', axis=1)
.assign(ImageId = range(1, len(labels) + 1))
.reset_index(drop=True))[['ImageId', 'Label']]