Wiki topic to discuss fastai v2 vision module.
Hi @jeremy, excited to get going with V2. I remember seeing an implementation of Siamese Neural Networks using v2 on twitter. Is this something that has been emphasized for completing tasks like facial recognition.
Best to look at the notebooks to see what’s there.
1 Like
Hey Jeremy, I’m working through the Imagenette notebook right now making a Pets lesson example (because we all know and love Pets!) One issue I’m having currently is I’ve made my datablock like so:
data = DataBlock(ts=(PILImage, Category),
get_items=get_image_files,
splitter=RandomSplitter(0.2),
labeller=labeller)
and when I go to databunch it, I get TypeError: 'PosixPath' object does not support indexing
Here is how I create the databunch, with source pointing to the images folder:
data = data.databunch(source=source, ds_tfms=ds_img_tfms,
dl_tfms=Normalize(*imagenet_stats), bs=64, num_workers=8)
Where did I mess up?
(Also looks like a few api changes happened when you last updated some example notebooks. I’ll work up a few of the fixes eventually once this is working)
Have a look at the pets example in 50 to see where yours is different.
1 Like
Will do. Thanks! 
For those wondering what was different, labeller is now get_y, and for the databunch I did it as so:
dbunch = pets.databunch(untar_data(URLs.PETS)/'images', ds_tfms=Resize(128))
See below as to why I did not include the dl_tfms
When I try grabbing one batch (following PETS), I get a RuntimeError: solve_cuda: For batch 0: U(52191744,52191744) is zero, singular U.
x,y = dbunch.one_batch()
/content/fastai_dev/dev/local/vision/augment.py in find_coeffs(p1, p2)
334 A = stack(m).permute(2, 0, 1)
335 B = p1.view(p1.shape[0], 8, 1)
--> 336 return torch.solve(B,A)[0]
337
338 def apply_perspective(coords, coeffs):
RuntimeError: solve_cuda: For batch 0: U(18486784,18486784) is zero, singular U.
Possibly a CUDA issue? Are we using cuda 10?
Looks to be tied in with aug_transforms()
However if I leave that out the model is training Thanks Jeremy!
Can you give us the code you used that led to this bug? Thanks!
Sure! Sorry Here is the full code I ran (with a temporary fix for untar_data to grab our data)
path = untar_data(URLs.PETS)/'images'
src = get_image_files(path)
pets = DataBlock(ts=(PILImage, Category),
get_items = get_image_files,
splitter = RandomSplitter(0.2),
get_y=RegexLabeller(pat=r'/([^/]+)_\d+.jpg$'))
dbunch = pets.databunch(untar_data(URLs.PETS)/'images', ds_tfms=Resize(128),
dl_tfms=aug_transforms())
x,y = dbunch.one_batch()
Leaving out the aug_transforms() lets it operate fine.
I’d suggest making sure you’ve got the latest pytorch version. solve uses the MAGMA library I think, but it should all be included automatically in Pytorch’s download AFAIK.
Oh and to answer your question - yes we’re using CUDA 10, although that should be automatically included in Pytorch’s conda install.
1 Like
I’ve got torch 1.2.0 and torchvision 0.4.0 installed with both being used
@sgugger thoughts? If you guys can run it just fine it may be an environment issue I haven’t solved in colab yet…though I’m unsure what I missed.
Yes it’s working for @sgugger too. Neither of us are using colab though.
Got it, okay. I will look into what may be missing on the colab side then. Apologies!
I am currently going through the 07_vision_core notebook and running into some things I’m not quite sure I understand. Looking at what is happening around this test:
im = PILImage.create(TEST_IMAGE)
test_eq(type(im), PILImage)
test_eq(im.mode, 'RGB')
All of that runs fine and if I look at the type(im) I get __main__.PILImage but when I run the resize command below it, and check that type, it is type PIL.Image.Image. I’m just wondering if that’s correct or if it should still be of type __main__.PILImage after being resized.
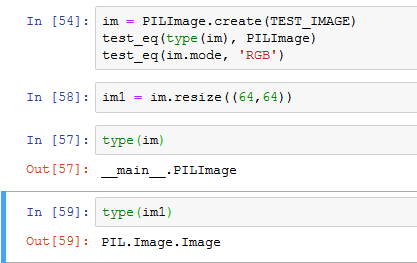
If you don’t use a fastai Transform, you’ll lose the type after doing a transformation, that’s what they are for. Just create a function to do the resize and pass it in a Transform and you’ll see the type stays the same.
1 Like
@sgugger I guess we could patch the PIL Image methods like we do for Tensor…
Thanks
How cool and simple it is to convert Imagenette labels to more sensible texts thanks to transforms!
First we define the function to map labels to alternative text:
lbl_tfm = {
'n01440764': 'tench',
'n02102040': 'English springer',
'n02979186': 'cassette player',
'n03000684': 'chain saw',
'n03028079': 'church',
'n03394916': 'French horn',
'n03417042': 'garbage truck',
'n03425413': 'gas pump',
'n03445777': 'golf ball',
'n03888257': 'parachute'
}
def lbl2txt(o): return lbl_tfm[o]
Then add this function to the list of lists of transformations:
tfms = [[PILImage.create],
[parent_label,
lbl2txt,
Categorize]]
...
dbch.show_batch(max_n=9)
And voila!

8 Likes