Great idea! BTW instead of defining this function, you could use lbl_tfm.__getitem__ directly in the pipeline ![]()
I’m going to add this to the Imagenette tutorial because I think it’s really cool!
Great idea! BTW instead of defining this function, you could use lbl_tfm.__getitem__ directly in the pipeline ![]()
I’m going to add this to the Imagenette tutorial because I think it’s really cool!
Suppose I’m working on a problem where the input is an image and the output is a list of two boolean masks over the input image. What’s the best way to specify the tfms that goes into DataSource? When each sample is shown, I’d like each boolean mask to be over the image in a separate axis.
I’ve tried creating something that holds the two boolean masks with a show method:
class TwoMasks(Tuple):
def show(self, ctx=None, **kwargs):
bmsk1, bmsk2 = self
_, axs = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
bmsk1.show(ctx=axs[0])
bmsk2.show(ctx=axs[1])
Then, a Transform that converts a multi-category mask (like in the camvid example in 08_pets_tutorial) to a boolean mask. Then these two new classes are gather into a single Transform that will go from the image file name to a TwoMasks:
class TwoMaskTfm(Transform):
def __init__(self, catids): self.catids = L(catids)
def encodes(self, o):
masks = []
for i in self.catids:
pipe = Pipeline([cv_label, PILMask.create, BoolMaskTfm(i)])
masks.append(pipe(o))
return Tuple(masks)
def decodes(self, o): return TwoMasks(o)
Finally, they are used with DataSource like in this example:
tfms = [[PILImage.create], [TwoMaskTfm([17, 21])]]
camvid2 = DataSource(cv_items, tfms=tfms)
img, (msk1, msk2) = camvid2[10]
camvid2.decode((img, (msk1, msk1)))
camvid2.show((img, (msk1, msk2)));
getting:
To extend this for DataBlock:
def get_lbl2txt(o): return lbl_tfm.__getitem__(parent_label(o))
Now we can pass it to DataBlock as get_y parameter:
imagenette = DataBlock(ts=(PILImage, Category),
get_items=get_image_files,
splitter=GrandparentSplitter(valid_name='val'),
get_y=get_lbl2txt)
to get the same result:
In your show method, you don’t use the ctx and create a new plot. If you want to superpose the masks to your input, you have to use it.
Here it’s probably easier to just use subscript:
def get_lbl2txt(o): return lbl_tfm[parent_label(o)]
Although maybe that’s not needed…:
If you want to avoid creating an extra function, you don’t even need to define get_lbl2txt, but can just say:
get_y=compose(parent_label,lbl_tfm.__getitem__)
(These are, of course, just minor tweaks to your approach - in case that’s of interest.)
I’ve just made a change to data.block so you can now just say:
get_y=[parent_label,lbl_tfm.__getitem__]
![]()
I’d like to do some semantic segmentation. What’s the best way to go about this in fastai v2…to get a Unet?
The unet model hasn’t been ported to v2 yet. I’m working on this and it should land today or tomorrow.
Hi,
First of all thanks Jeremy and Sylvain for the great work, the library looks awesome already!
I’m trying to get my hands dirty and integrate MobileNetV2 in the library.
I downloaded it from torchvision.models import mobilenet_v2, attached a simple custom head (identical with different number of classes) and tried to train it on the pets dataset.
Eventually on fitting I get a size mismatch which I don’t quite understand because I keep the input in the custom head the same as the original mobileNet.
RuntimeError: size mismatch, m1: [573440 x 7], m2: [1280 x 22] at /opt/conda/conda-bld/pytorch_1570910687650/work/aten/src/THC/generic/THCTensorMathBlas.cu:290
Thanks in advance for any hints!
I attached the notebook in PDF format:
MobileNetV2.pdf (136.5 KB)
Looking forward to contribute to v2.
You need to add some flattening of your inputs. In the mobilenet model, they take the mean over the last two channels before going through the head (see this line) and this is missing in your code.
Thank you very much!
I managed to get it working. Would it be interesting to add MobileNetV2 to the list of libraries?
Yes it would!
Ok good to know. Ill try to create a pull request after some fine-tuning
A question about the splitter function. This function is used to set different learning rates for different parts of the network, right?
On what grounds have the split values been chosen for the networks?
The default we use come from experiments, though it’s very likely changing them for one layer or two won’t change the final result much.
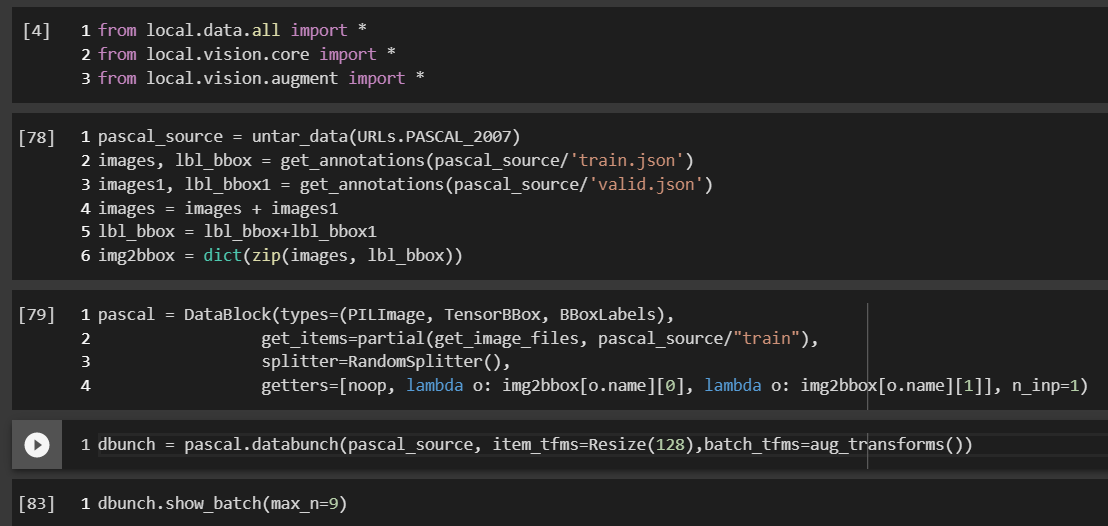
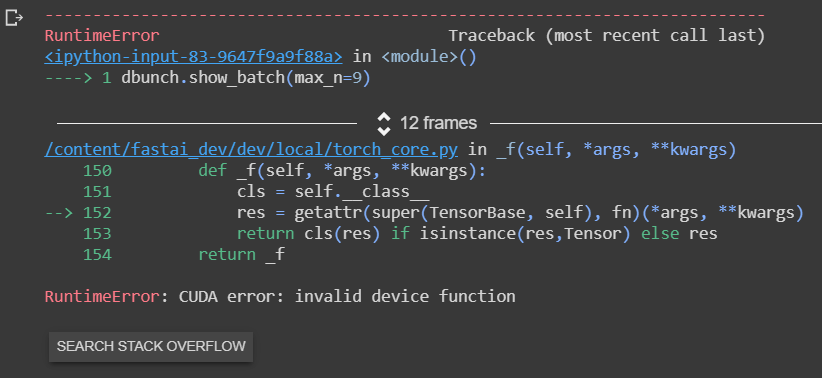
I try to create databunch with pascal-2007 data using following code on Colab:
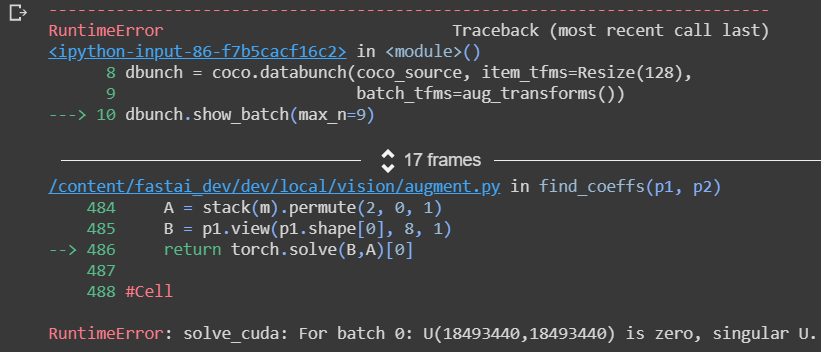
The problem may only happen on Colab. When using CoCo data, err is similar as below:
Can you check you have the latest pytorch installed?
Yes, Pytorch is installed. Databunch was create successfully but cannot be show_batch. And when I switch to cpu mode, it works again.
@fanyi When doing aug transforms try passing in max_warp=0 And see if that helps. I was seeing that issue too
@muellerzr, I tried as you adviced but not work. It only get to work until I fully remove the after_batch transform. problem seems come from AffineCoordTfm.