Notes for the Code Walkthrough 6 - Completed
Importing all the modules to make sure that I can recreate the note book and things did during the walkthrough.
from local.torch_basics import *
from local.test import *
from local.data.load import *
from local.data.transform import *
from local.data.pipeline import *
from local.data.external import *
from local.notebook.showdoc import *
from local.data.all import *
from local.vision.core import *
from local import *
Jeremy starts with TypeDispatch function. He mentions that Aman Arora has got some good write ups on the same in the forums. Let’s look at the code of TypeDispatch
class TypeDispatch:
"Dictionary-like object; `__getitem__` matches keys of types using `issubclass`"
def __init__(self, *funcs):
self.funcs,self.cache = {},{}
for f in funcs: self.add(f)
self.inst = None
def _reset(self):
self.funcs = {k:self.funcs[k] for k in sorted(self.funcs, key=cmp_instance, reverse=True)}
self.cache = {**self.funcs}
def add(self, f):
"Add type `t` and function `f`"
self.funcs[_p1_anno(f) or object] = f
self._reset()
def returns(self, x): return anno_ret(self[type(x)])
def returns_none(self, x):
r = anno_ret(self[type(x)])
return r if r == NoneType else None
def __repr__(self): return str({getattr(k,'__name__',str(k)):v.__name__ for k,v in self.funcs.items()})
def __call__(self, x, *args, **kwargs):
f = self[type(x)]
if not f: return x
if self.inst is not None: f = types.MethodType(f, self.inst)
return f(x, *args, **kwargs)
def __get__(self, inst, owner):
self.inst = inst
return self
def __getitem__(self, k):
"Find first matching type that is a super-class of `k`"
if k in self.cache: return self.cache[k]
types = [f for f in self.funcs if issubclass(k,f)]
res = self.funcs[types[0]] if types else None
self.cache[k] = res
return res
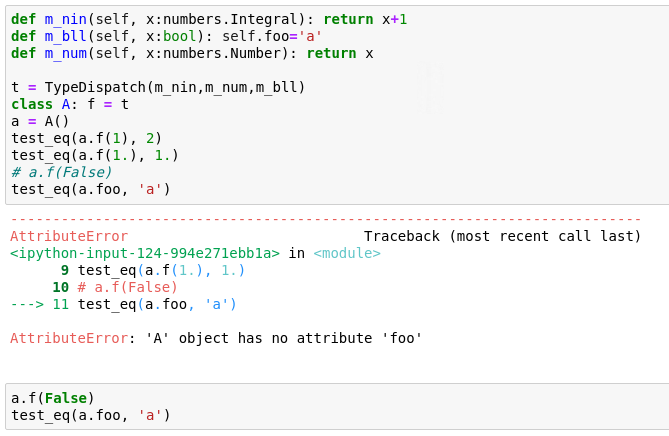
There are tests in 02_data_transforms.ipynb. Let’s look at them. We did not look at the second set of sets last time. The second set have self also in them. So in the test (see below) when we pass a.f, how does python know that it has to be taken as self. This is not default behaviour and we have changed that. f is an attribute of class A, there is nothing in particular that says a.f should be passed as self.
def m_nin(self, x:numbers.Integral): return x+1
def m_bll(self, x:bool): return x
def m_num(self, x:numbers.Number): return x
t = TypeDispatch(m_nin,m_num,m_bll)
class A: f = t
a = A()
test_eq(a.f(1), 2)
test_eq(a.f(1.), 1.)
Please Note:
I have modified the tests below to be able to do some debug. The tests in the actual notebook 02_data_transforms.ipynb are valid and remain the same.
Let’s change the tests a bit to show that we are passing a real self. To test this we need to set g.d(False) and then do test_eq(g.foo,'a'). We will find that it passes the test.
This succeeds because in the code for TypeDispatch, specifically in the __call__ method, we check for self.inst and if it exists we bind the function d to be method to the instance g. This is what happends in the code if self.inst: f = types.MethodType(f, self.inst).
How do we know what self.inst is? self.inst has to be set to g. This is done using __get__ method in TypeDispatch. When we first execute g.d(False), python first executes __get__ in the class d belongs to. It specifically executes g.__get__ in the TypeDispatch as g is an instance of class V and d has been set to be equal to t_new which is a TypeDispatch class.
The place to go and understand all of this is in Python Data Model. Note that g or classV do not have a __get__ defined in them. So this get passed to their ancestors which happens to be TypeDispatch in this case.
def t_m_nin(self, x:numbers.Integral): return x+1
def t_m_bll(self, x:bool): self.foo = 'a'
def t_m_num(self, x:numbers.Number): return x
t_new = TypeDispatch(t_m_nin,t_m_num,t_m_bll)
class V: d = t_new
g = V()
g.d(False)
As you can see in the below cell g.__dict__ has {'foo': 'a'}.
g.__dict__
{'foo': 'a'}
If we now do the test_eq of g.foo and a, it will pass.
test_eq(g.foo,'a')
One things that has been added new in _tfm_methods (Please see class _TfmDict for this) is setups. It already had encodes and decodes. Now setups has been added. setups will be called by function setup like in Transform class. setups is now a TypeDispatch object.
The reason for this is that now we have now started to work with rapids (by nvidia). They provide something like pandas which runs on the GPU. It works like pandas but is not pandas. We want to do tabular transforms and want it to work with RAPIDS dataframes as well as Pandas dataframes. Here we are using setups to help drive this behaviour.
Lets now do 03_data_pipeline.ipynb. Lets create a pipeline. It is easy to start looking at the tests first. In the test below we create an empty Pipeline and assign it to pipe. pipe is callable as pipe(1). But this is an empty pipeline. Whatever we pass on to an empty Pipeline gets returned. So here 1 gets returned as the output of pipe(1). It has the same ‘as item’ behaviour like in Transform. So if you do set_as_item() and pass in a boolean (True or False) inside it, it will set all transforms as_item to be equal to that boolean.
So if we pass a tuple after doing pipe.set_as_item(False) we get back a tuple as you can see in the test below.
# Empty pipeline is noop
pipe = Pipeline()
test_eq(pipe(1), 1)
pipe.set_as_item(False)
test_eq(pipe((1,)), (1,))
# Check pickle works
assert pickle.loads(pickle.dumps(pipe))
Let’s take a Pipeline that has transforms in it. As you can see there are two transforms in it. The int_tfm has an encodes that returns Int (Note: This Int is a fastai specific type and not the python int) and decodes that returns a Float. The neg_tfm just returns a negative value of the variable passed on to it in both encodes as well as decodes.
The encodes is called in the serial order whereas the decodes is called in the reverse order. So for pipe = Pipeline([neg_tfm, int_tfm]) when we call pipe(start) the encodes get to work. First the neg_tfm is called first and then int_tfm is called second. Whereas when we do pipe.decode(t) the int_tfm is called first and then neg_tfm is called second.
The way the Pipeline is executed when pipe(start) is called is via the __call__ defined in Pipeline. It calls the compose_tfms function which take in a list of functions. The list of functions is done via the __init__ in the Pipeline which takes the functions (neg_tfm and int_tfm in this case) and convert them to L(functions) (Note: L is a special list created in fastai), map them to Transform if they are not of Transform class and sort them by order.
The specific code snippets that we are referrring to in the Pipeline code is
def __call__(self, o): return compose_tfms(o, tfms=self.fs, filt=self.filt)
and
def __init__(self, funcs=None, as_item=False, filt=None):
if not funcs: funcs=[noop]
if isinstance(funcs, Pipeline): funcs = funcs.fs
self.filt = filt
self.fs = L(funcs).mapped(mk_transform).sorted(key='order')
self.set_as_item(as_item)
The compose_tfms takes in the variable, the transformations, is primed to do encodes first (is_enc=True is there in the code by default and reverse=False to prevent decodes behaviour). It goes through each function and applies them to the variable. There are tests kept for functions as well as Transform class type.
def compose_tfms(x, tfms, is_enc=True, reverse=False, **kwargs):
"Apply all `func_nm` attribute of `tfms` on `x`, maybe in `reverse` order"
if reverse: tfms = reversed(tfms)
for f in tfms:
if not is_enc: f = f.decode
x = f(x, **kwargs)
return x
When the pipe.decode(t) is called then the same compose_tfms is called but now we set is_enc=False and reverse=True to stimulate decodes behaviour. The below code in Pipeline to handle decode shows the same.
def decode (self, o): return compose_tfms(o, tfms=self.fs, is_enc=False, reverse=True, filt=self.filt)
pipe.show(t) behaves likes this. It takes t and starts decoding it until it gets to type that has the show method in it. In the case of this test, t is of type Int which has a show method that it inherits from ShowTitle.
class Int(int, ShowTitle): pass
class ShowTitle:
"Base class that adds a simple `show`"
_show_args = {'label': 'text'}
def show(self, ctx=None, **kwargs): return show_title(str(self), ctx=ctx, **merge(self._show_args, kwargs))
Please note in the show function of class ShowTitle the ctx is set to None. In this case it shows whatever it is passed. In the ctx you can pass along a plot and Title if you want.
class IntFloatTfm(Transform):
def encodes(self, x): return Int(x)
def decodes(self, x): return Float(x)
int_tfm=IntFloatTfm()
def neg(x): return -x
neg_tfm = Transform(neg, neg)
pipe = Pipeline([neg_tfm, int_tfm])
start = 2.0
t = pipe(start)
test_eq_type(t, Int(-2))
test_eq_type(pipe.decode(t), Float(start))
test_stdout(lambda:pipe.show(t), '-2')
If you notice to test what gets printed the code is lambda:pipe.show(t) and it takes no arguments. This gets passed on to test_stdout to test what gets printed when pipe.show(t) is run. It is a nice way to test this. If we don’t pass this way, we can see the test does not go ahead.
test_stdout(pipe.show(t), '-2')
-2
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-22-c1c41d39d068> in <module>
----> 1 test_stdout(pipe.show(t), '-2')
~/Documents/GitHub/fastai_dev/dev/local/test.py in test_stdout(f, exp, regex)
74 "Test that `f` prints `exp` to stdout, optionally checking as `regex`"
75 s = io.StringIO()
---> 76 with redirect_stdout(s): f()
77 if regex: assert re.search(exp, s.getvalue()) is not None
78 else: test_eq(s.getvalue(), f'{exp}\n' if len(exp) > 0 else '')
TypeError: 'int' object is not callable
When set_as_item is set to False and then pipe.show is called on a tuple then the show is called on each element of the tuple.
pipe.set_as_item(False)
test_stdout(lambda:pipe.show(pipe((1,2))), '-1\n-2')
The reason for that is in a batch we have a tuple. One element is an image and the other is a label. So each element will be shown as per the show defined for their type.
The show method in Pipeline goes through all functions in the pipeline but in reverse order. It will first find if it can show without decoding and if it cannot then it will decode it. Then it will use the show method of the decoded type. This can be seen in the code below that highlights the show part of Pipeline.
def show(self, o, ctx=None, **kwargs):
for f in reversed(self.fs):
res = self._show(o, ctx, **kwargs)
if res is not None: return res
o = f.decode(o, filt=self.filt)
return self._show(o, ctx, **kwargs)
def _show(self, o, ctx, **kwargs):
o1 = [o] if self.as_item or not is_listy(o) else o
if not all(hasattr(o_, 'show') for o_ in o1): return
for o_ in o1: ctx = o_.show(ctx=ctx, **kwargs)
return 1 if ctx is None else ctx
pipe.set_as_item(False)
test_stdout(lambda:pipe.show(pipe((1,2))), '-1\n-2')
r = pipe((1,2)); r
(-1, -2)
pipe.show(r)
-1
-2
Now lets look at TfmdList. This is a subclass of TfmdBase which is a subclass of L. It takes in items and transforms and creates Pipeline of these transforms. It passes the list of items to L. This can be seen in the __init__ method of the same.
class TfmdList(TfmdBase):
"A `Pipeline` of `tfms` applied to a collection of `items`"
def __init__(self, items, tfms, do_setup=True, as_item=True, use_list=None, filt=None):
super().__init__(items, use_list=use_list)
if isinstance(tfms,TfmdList): tfms = tfms.tfms
if isinstance(tfms,Pipeline): do_setup=False
self.tfms = Pipeline(tfms, as_item=as_item, filt=filt)
if do_setup: self.setup()
This is a good time to know more about L. In the __getitem__ method we have defined that if it is an iterator it goes to self._gets and to self._get if it is just an index.
def __getitem__(self, idx): return L(self._gets(idx), use_list=None) if is_iter(idx) else self._get(idx)
def _get(self, i): return getattr(self.items,'iloc',self.items)[i]
def _gets(self, i):
i = mask2idxs(i)
return (self.items.iloc[list(i)] if hasattr(self.items,'iloc')
else self.items.__array__()[(i,)] if hasattr(self.items,'__array__')
else [self.items[i_] for i_ in i])
We overwrite the _get method in TfmdList where we continue to use the self._get of L but we run a transform on the same. This is what enables us to treat the items part of the TfmdList as a list and index into the same.
def _get (self, i): return self.tfms(super()._get(i))
Here we define tl to be a TfmdList of items which is a list of floats (1.,2.,3.) and list of transforms which are (neg_tfm and int_tfm). But we can index into tl and get the first index item in tl which is 2.
tl = TfmdList([1.,2.,3.], [neg_tfm, int_tfm])
t = tl[1]
tl = TfmdList([1.,2.,3.], [neg_tfm, int_tfm])
t = tl[1]
test_eq_type(t, Int(-2))
test_eq(tl.decode_at(1), 2)
test_eq_type(tl.decode(t), Float(2.0))
test_stdout(lambda: tl.show_at(2), '-3')
tl
TfmdList: [1.0, 2.0, 3.0]
tfms - [Transform: True {'object': 'neg'} {'object': 'neg'}, IntFloatTfm: True {'object': 'encodes'} {'object': 'decodes'}]
We are not using TfmdList for datasets as it returns only one thing. We want to be able to get two things from a dataset like x,y instead of just one thing. Let us look at TfmdDS. It looks the same as TfmdList as it takes in items and transforms. It is also a subclass of TfmdBase. But it creates TfmdList for every transform function that it has. So now we have set up ‘n’ pipelines instead of just one pipeline. Normally TfmdDS is used for two pipelines, one each for x and y.
class TfmdDS(TfmdBase):
"A dataset that creates a tuple from each `tfms`, passed thru `ds_tfms`"
def __init__(self, items, tfms=None, do_setup=True, use_list=None, filt=None):
super().__init__(items, use_list=use_list)
if tfms is None: tms = [None]
self.tls = [TfmdList(items, t, do_setup=do_setup, filt=filt, use_list=use_list) for t in L(tfms)]
This is what we used in 08_pets_tutorial where we had two TfmdList list.
tfms = [[PILImage.create, ImageResizer(128), ToTensor(), ByteToFloatTensor()],
[labeller, Categorize()]]
tds = TfmdDS(items, tfms)
We can use .tls to see the two TfmdList and then used .tfms to see the transform applied to them.
tds.tls[0]
tds.tls[1]
tds.tls[0].tfms
tds.tls[1].tfms
When we call decode on it, it will go through each TfmdList and decode each item using each function in the transforms for that TfmdList. This is the decode code in TfmdDS.
def decode(self, o): return tuple(it.decode(o_) for o_,it in zip(o,self.tls))
There was a question on whether both pipelines here have been created using items which are path to images. The answer is yes. The path has the details about both the image as well as the details (labels) of the image. Jeremy goes on to explain the same in the code.
We take a single item from the Pet’s image. We take all the transforms in the first TfmdList and assign to fx. We assign all the transforms in the second TfmdList to fy. Then individually we can see that [PILImage.create, ImageResizer(128), ToTensor(), ByteToFloatTensor()] is being applied to it via fx and it returns a tensor. We can see that [labeller, Categorize()] is being applied to it via fy and it returns a label.
it = items[0]
fx = tds.tls[0].tfms
fy = tds.tls[1].tfms
fx(it)
fy(it)
There was another question as to whether the items in TfmDS can be tuples. The answer is yes. To illustrate that Jeremy uses this example.
its = L((0,1),(1,2),(3,4))
fx = itemgetter(0)
fy = itemgetter(1)
its.mapped(fx) returns (#3) [0,1,3]. its.mapped(fy) returns (#3) [1,2,4]. He goes on to create a TfmdDS with its and fx,fy. The working of the same is shown in the below code.
its = L((0,1),(1,2),(3,4))
fx = itemgetter(0)
fy = itemgetter(1)
print(its.mapped(fx))
print(its.mapped(fy))
(#3) [0,1,3]
(#3) [1,2,4]
tds = TfmdDS(its,[[fx],[fy]])
tds[0]
(0, 1)
This also addresses another question on whether this cannot be used if labels were in a separate file. As long as the items contain both the image and the labels, we can use TfmdDS. They need not be in the same file. Jeremy explains that he and Sylvian have reached here after about 25 iterations and many weeks. It is not necessary to understand these details. But we are here in this walkthrough to get the details. We should not be worried about getting this. It is ok and it could take a while.
As homework, play with 08 notebook to understand all of this. We will use TfmdDS most of the time. But internally TfmdDS uses TfmdList. All of these things TfmdDS and TfmdList are small pieces of code. Go through the code to get a intuitive understanding of what the code does. Then try to understand the tests, specifically why did we add those tests. The tests are not arbitrary. They have been added because Jeremy and Sylvian think that they provide the best clarity. The tests will help to understand. The methods section also has tests. Try and go through and understand them as well.
We now go to notebook 05_data_core.ipynb. Let’s now try to understand setup in Pipeline. Let’s look at Categorize. If we don’t pass a vocab in the __init__ the setups will automatically add a Category. Let’s look at the setup part of the code in Categorize
`
class Categorize(Transform):
def setups(self, dsrc):
if self.vocab is None and dsrc: self.vocab = CategoryMap(getattr(dsrc,'train',dsrc), add_na=self.add_na)
The vocab is a CategoryMap class which will simply find the unique list of items to form the vocab. Unless we pass a Pandas Dataframe, then pandas automatically does it for us. Let’s look at the __init__ part of the code in CategoryMap to understand this.
class CategoryMap(CollBase):
"Collection of categories with the reverse mapping in `o2i`"
def __init__(self, col, sort=True, add_na=False):
if is_categorical_dtype(col): items = L(col.cat.categories, use_list=True)
else:
# `o==o` is the generalized definition of non-NaN used by Pandas
items = L(o for o in L(col, use_list=True).unique() if o==o)
if sort: items = items.sorted()
self.items = '#na#' + items if add_na else items
self.o2i = defaultdict(int, self.items.val2idx()) if add_na else dict(self.items.val2idx())
We don’t have setup method tests defined still in the notebooks as of now. We will have to look at DataSource to see how they are working. So let’s try and understand the setup of Pipeline.
def setup(self, items=None):
self.default = self.items = items
tfms,self.fs = self.fs,[]
for t in tfms: self.add(t,items)
def add(self,t, items=None):
t.setup(items)
self.fs.append(t)
we make the list of functions self.fs an empty list. Then we loop through each transform in tfms and call add. The add function again calls setup on the transform and then appends the transform to self.fs. The reason for doing like this is that in this tfms list [labeller, Categorize()], When Categorize() is called, the labeller is already completed and the vocab can now be formed. This was a very tricky thing to do, but now it is there and it is very handy. This is more clear if we look at the Transform code of setup.
def setup(self, items=None): return self.setups(items)
When t.setup is called it calls self.setups as seen above. We look at a test for Categorize(). There are three items [‘dog’,‘cat’,‘cat’] and then we call Categorize() on it. The vocab comes back with [‘cat’,‘dog’] correctly.
cat = Category.create()
tds = TfmdDS(['cat', 'dog', 'cat'], tfms=[cat])
cat.vocab
(#2) [cat,dog]
Now we have all the things to understand TfmdDL. Here we have defined _dl_tfms = ('after_item','before_batch','after_batch'). Lets look at the __init__ part of the code for TfmdDL.
def __init__(self, dataset, bs=16, shuffle=False, num_workers=None, **kwargs):
if num_workers is None: num_workers = min(16, defaults.cpus)
for nm in _dl_tfms:
kwargs[nm] = Pipeline(kwargs.get(nm,None), as_item=(nm=='before_batch'))
kwargs[nm].setup(self)
super().__init__(dataset, bs=bs, shuffle=shuffle, num_workers=num_workers, **kwargs)
If we pass in any keyword arguments **kwargs in the __init__ then it will take each keyword argument and then create a Pipeline for each of them. It will then call setup kwargs[nm].setup(self). It has self here in the code because the setup needs to know what items are passed. For example in the Categorize() it needs all labelled items. We can also look at the decode of the TfmdDL and see what it is doing.
We look at Cuda(Transform). The encodes sets up on the device and decodes sets up on the CPU. This is a cool function and there are no other ones which will take things to CPU for the purpose of display. This will help address memory leaks. Lets look at 06_data_source.ipynb. We look at DataSource.
It is identical to TfmDS except that it has as an additional argument called filts which is filters.
tds = TfmdDS (items, tfms)
pets = DataSource(items, tfms, filts=split_idx)
The filters tell the DataSource how to get a subset.
pets.subset(1)[0]
This returns a new TfmdDS with items that are in split_idx. split_idx is nothing but list containing two sets of index numbers (one for training set and another for validation set) in the case of the 08_pets_tutorial.ipynb notebook. pets.subset(1) is the same as pets.valid and pets.subset(0) is the same as pets.train. All that the DataSource is doing is that it is returning two TfmdDS using split_idx to separate the items.
Let’s look at the code for DataSource. It comes in a single screen and a large part of that is for databunch. It is a subclass of TfmdDS. But it has a method called subset which calls on function _mk_subset. Let’s see the specific code for subset in DataSource and code for function _mk_subset.
def subset(self, i): return _mk_subset(self, i)
def _mk_subset(self, i):
tfms = [o.tfms for o in self.tls]
return TfmdDS(L._gets(self, self.filts[i]), tfms=tfms, do_setup=False, filt=i)
As you can in _mk_subset it makes a TfmdDS with the set of items in self.filts[i]. It passes do_setup=False as there is no need to recreate the vocab again. This is basically what a DataSource is. We can pass as many filters. Normally it is two but you can pass as many as you want.
assert all_disjoint(self.filts)
This code above is in __init__ of the DataSource and is there to ensure that are no indexes of training in validation and vice versa. So good Data Science practices are also inculcated. In the _mk_subset code we saw that the TfmdDS that was created had a filt variable. Let’s look at why this is there. This is passed from TfmdDS to TfmdList to Pipeline (passed in __call__ and decode in Pipeline) to compose_tfms. From here it goes to the transforms. So that transforms have the ability to know whether they are being performed on the train set or validation set.
So if we look at the code of __init__ of Transform we can see that we can define on which set we want this to be applied.
class Transform(metaclass=_TfmMeta):
"Delegates (`__call__`,`decode`,`setup`) to (`encodes`,`decodes`,`setups`) if `filt` matches"
filt,init_enc,as_item_force,as_item,order = None,False,None,True,0
def __init__(self, enc=None, dec=None, filt=None, as_item=False):
So in data augmentation we can set filt=0 and make sure it is only applied to the training set. If we look at the _call part of the code in Transform, here we are ensuring that we are not accidentally passing in a different filter that was not the filter when the Transform was initiated. In such a case where we accidentally pass along different filters it will not do anything and just return what items it was given.
def _call(self, fn, x, filt=None, **kwargs):
if filt!=self.filt and self.filt is not None: return x
f = getattr(self, fn)
if self.use_as_item or not is_listy(x): return self._do_call(f, x, **kwargs)
res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
return retain_type(res, x)
There was a question on whether the filt was just an integer. The answer is yes. We look at the tests for DataSource. We define a datasource with items being [0.,1.,2.,3.,4.] and no tfms. There are no filters defined which means that it has only one filter which is all items inside it.
inp = [0,1,2,3,4]
dsrc = DataSource(inp, tfms=[None])
test_eq(len(dsrc.filts), 1)
When we index a single item it returns that. But when we index two items it returns a tuple of those individual items. This is because it return TfmdDS which returns a tuple as in PyTorch we need a batch which has two items.
test_eq(*dsrc[2], 2)
test_eq(dsrc[1,2], [(1,),(2,)])
There was a question on whether retain_type should be called in _call if filt!=self.filt. The answer is no. the function retain_type takes the result (res is the name of the result in the code) of the transform done on the input item x and makes res the same type as x. This is done just in case res ends up a sub class of x as a result of the transform. For example, if res is of type Tensor as a result of the transform, whereas x is TensorImage then retain_type will convert res to TensorImage. Here in our case of filt!=self.filt there is no change or transform being done. Only x is returned as such. So there is no need to do retain_type.
TfmdDS works with masks , range and dataframes as well. It works with dataframes in a most optimal way using iloc method. The filters can be tensors and masks. There was a question on how to handle a scenario where transform of y depends on transform of x. Jeremy says that we will get to it in a couple of days.