fastai v2 walk-thru 3 notes
Video | Notes
Fastai v2 daily code walk-thrus
Fastai v2 chat
Thanks to @arora_aman for these notes
Note: Jeremy has made changes 08_pets_tutorial.ipynb, specifically to Siamese Model and has moved class SiameseImage to the top, and removed the create classmethod we had previously.
Also, rather than deriving OpenAndResize from TupleTransform, there is an easier way to do it which is to pass resized_image to TupleTransform like so TupleTransform(resized_image) and in this case just need to make sure that the first parameter has a type if you want your transform to be working on a specific type.
Also, things like tfmDS know how to handle pipeline and we won’t have to create TupleTransform.
Data Core
Let’s look at an example of things that can use TfmdDL -
Cuda
# export
@docs
class Cuda(Transform):
"Move batch to `device` (defaults to `defaults.device`)"
def __init__(self,device=None):
self.device=default_device() if device is None else device
super().__init__(filt=None, as_item=False)
def encodes(self, b): return to_device(b, self.device)
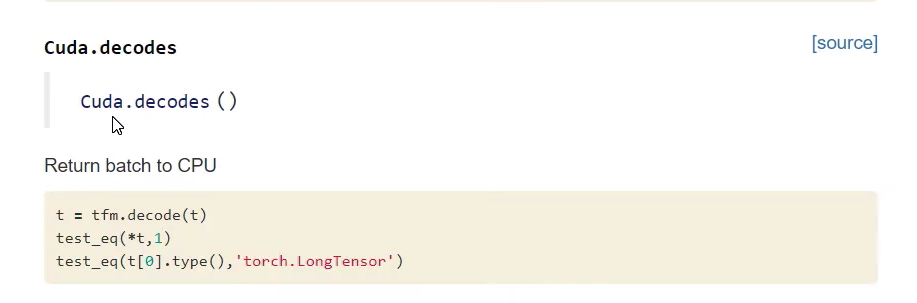
def decodes(self, b): return to_cpu(b)
_docs=dict(encodes="Move batch to `device`", decodes="Return batch to CPU")
Cuda is an example of Transform which will move a batch to some device. It is possible to change default_device by passing in device OR torch.cuda.set_device() and that will change it. Reason there is a default_device as then you can pass in use_cuda and it is a nice easy way to go between Cuda and non Cuda and is a nice easy way to move stuff between GPU and CPU.
Transforms look a lot like function and when we do call a function they call encodes.
(Reasons functions not used instead: 1. Classes can have states. 2. it is possible to have a decode method.)
@docs tries to find an attribute _docs which will be a dictionary and add docs. It is written to keep code concise and also Jeremy likes to have all documentation in one place.
show_doc is a function which returns documentation. It creates the Markdown that generates the documentation which has autogenerated bits and also manual bits.
Note: For classes and functions, you don’t have to use show_doc, but for methods, you do need to have it there.
show_docs creates source links - which if you’re inside the notebook it links to Notebooks and when on the documentation page, it should link to GitHub.
ByteToFloatTensor
# export
class ByteToFloatTensor(Transform):
"Transform image to float tensor, optionally dividing by 255 (e.g. for images)."
order = 20 #Need to run after CUDA if on the GPU
def __init__(self, div=True, div_mask=False, filt=None, as_item=True):
super().__init__(filt=filt,as_item=as_item)
self.div,self.div_mask = div,div_mask
def encodes(self, o:TensorImage): return o.float().div_(255.) if self.div else o.float()
def decodes(self, o:TensorImage): return o.clamp(0., 1.) if self.div else o
def encodes(self, o:TensorMask)->TensorMask: return o.div_(255.).long() if self.div_mask else o.long()
def decodes(self, o:TensorMask): return o
We have once pair of encodes+decodes for TensorImage and one pair for TensorMask. We want different transformation for both types.
The TensorMask version converts to a .long().
And in decodes for TensorImage sometimes you end up with 1.00001 so, fastai clamps it.
Normalization
# export
@docs
class Normalize(Transform):
"Normalize/denorm batch of `TensorImage`"
order=99
def __init__(self, mean, std): self.mean,self.std = mean,std
def encodes(self, x:TensorImage): return (x-self.mean) / self.std
def decodes(self, x:TensorImage): return (x*self.std ) + self.mean
_docs=dict(encodes="Normalize batch", decodes="Denormalize batch")
Here is an example where the Transform is just very helpful because it’s very annoying in fastai v1 and other libraries for having to remember to denormalize images to display them. But thanks to decodes we have states for std and mean so we can decode and it is no longer a manual task.
dl_tfms = [Cuda(), ByteToFloatTensor(), Normalize(mean,std)]
tdl = TfmdDL(train_ds, after_batch=dl_tfms, bs=4)
So, it is now possible to have a Pipeline and we can grab a batch with tdl.one_batch which we can decode and display as an image. It no longer needs to be a manual task, but decoding happens automatically.
Room to improve Normalize perhaps by adding setup which automatically calculates mean and std from Batch itself.
DataBunch
Entire definition in V2 is
# export
@docs
class DataBunch(GetAttr):
"Basic wrapper around several `DataLoader`s."
_xtra = 'one_batch show_batch dataset'.split()
def __init__(self, *dls): self.dls,self.default = dls,dls[0]
def __getitem__(self, i): return self.dls[i]
train_dl,valid_dl = add_props(lambda i,x: x[i])
train_ds,valid_ds = add_props(lambda i,x: x[i].dataset)
_docs=dict(__getitem__="Retrieve `DataLoader` at `i` (`0` is training, `1` is validation)",
train_dl="Training `DataLoader`",
valid_dl="Validation `DataLoader`",
train_ds="Training `Dataset`",
valid_ds="Validation `Dataset`")
If you don’t want to use DataBunch class you could write something like:
db = namedtuple(train_dl =, valid_dl = ) and passing in a train and valid dataloader and now use this as a data bunch but there is no reason to as you could just go db = DataBunch(train_dl, valid_dl) and you’re all done.
Quite a few tricks to make DataBunch nice and concise;
GetAttr:
Basically a wrapper around __getattr__ which is called in Python when an attribute of class not defined. But it has a couple of problems -
- It can grab everything that isn’t defined and that can hide errors because you might be calling something that might be a typo
- You don’t get tab completion. Because Python doesn’t know what can be handled in getattr.
GetAttr overcomes these problems - it gives exactly the same behavior. It will look for default inside Class and anything that is not understood it will look under default.
Example, dbch.train_dl.dataset - If you just said dbch.dataset it would be nice to assume that we are talking about the training set. dbch.dataset selects the training set by default.
Another example would be one_batch which is same as train_dl.one_batch.
The way this works is that you have to inherit and add some attribute default
Optionally define another attr called _xtra and only those things will be delegated to default. _xtra will actually define all of the attributes inside self.default and anything that doesn’t start with _ will be automatically included inside the tab completion list. So we try to keep things manageable by saying _xtra is the subset of stuff we expect.
Back to DataBunch:
We are defining @docs which allows us to add documentation as mentioned before.
DataBunch is flexible with multiple possible data loaders - train, valid, test. self.dls=dls
Also, we can now define __getitem__ so we can index directly into DataBunch to get the nth dataloader.
Now that we have __getitem__ we basically want to say:
@property
def train_dl(self): return self[0]
@property
def valid_dl(self): return self[1]
and that’s a lot of code so in fastai we have add_props which will add those properties. These are shortcuts that come up because often we want a train version of something and a valid version of something.
So that is Data Core!
DataLoader
We are getting into some deep code now. Stuff that starts with 01 is going to be deep code. DL is designed to be a replacement for PyTorch Dataloader.
Why replace? Few reasons:
- Kept finding things that fastai wanted to do and weren’t able to and needed to keep creating own classes
- PyTorch DL is somewhat messy code and hard to understand and work through
Having said that, PyTorch DL is based on rock-solid world tested MultiProcessing system and we want to use that. Good news is that this multiprocessing system is pulled out into _MultiProcessingDataLoaderIter so we can just use that. Unfortunately, PyTorch classes are all kind of tightly coupled so to actually use this we have to do a little bit of ugly code but not too much.
A DL you can use it much the same way as normal PyTorch DL.
So let’s start with dataset and DS is anything that has length and can be indexed into. Example, list of letters.
ds1 = DataLoader(letters, bs=4, drop_last=True, num_workers=0)
test_eq(twoepochs(ds1), 'abcd efgh ijkl mnop qrst uvwx abcd efgh ijkl mnop qrst uvwx')
ds1 = DataLoader(letters,4,num_workers=2)
test_eq(twoepochs(ds1), 'abcd efgh ijkl mnop qrst uvwx yz abcd efgh ijkl mnop qrst uvwx yz')
ds1 = DataLoader(range(12), bs=4, num_workers=3)
test_eq_type(L(ds1), L(tensor([0,1,2,3]),tensor([4,5,6,7]),tensor([8,9,10,11])))
ds1 = DataLoader([str(i) for i in range(11)], bs=4, after_iter=lambda: setattr(t3, 'f', 2))
test_eq_type(L(ds1), L(['0','1','2','3'],['4','5','6','7'],['8','9','10']))
test_eq(t3.f, 2)
it = iter(DataLoader(map(noop,range(20)), bs=4, num_workers=1))
test_eq_type([next(it) for _ in range(3)], [tensor([0,1,2,3]),tensor([4,5,6,7]),tensor([8,9,10,11])])
So we can take a list of letters, pass in bs and say wehether or not drop_last batch if its not size 4 and say how many multiprocessing workers to do and if we take that and run two epochs we get back 'abcd efgh ijkl mnop qrst uvwx abcd efgh ijkl mnop qrst uvwx'
Similarly, Jeremy explains other tests that can be seen here.
That’s kind of the basic behavior of PyTorch DL but fastai DL also has some hooks like after_iter that will run after each iteration. So it is possible to add code that runs after iteration.
Also possible to pass Generator to DL and that will work fine too.
There is more stuff we can do and specifically, we can define a whole list of callbacks.
_methods = 'wif before_iter create_batches sampler create_item after_item before_batch create_batch retain after_batch after_iter'.split()
These are callbacks that are all over fastai V2.
So if you look at __iter__ code
def __iter__(self):
self.before_iter()
for b in _loaders[self.fake_l.num_workers==0](self.fake_l): yield self.after_batch(b)
self.after_iter()
You can see before_iter asnd after_iter being called.
for b in _loaders[self.fake_l.num_workers==0](self.fake_l): yield self.after_batch(b) is the slightly awkward thing for multiprocessing.
It will basically user self.d.sampler() and it will call create_batches for each iteration and create_batches will go through everything in the sample and it will map do_item over it and do_item is going to first create_item and then it will call after_item and then after that it will use a function called chunked which will create batches from list done lazily and then do_batch so just like create_item, do_batch will create batch so that will call before_batch and then create_batch and retain and finally after_batch.
So the idea here is that you can replace any of those things. Things like before_batch, after_batch and after_item are all things which default to noop in other words, you can just use them as CallBacks. But you can actually change everything! So we will see examples of that over time but here’s some.
Example-1:
def create_item(self, s):
r = random.random()
return r if r<0.95 else stop()
L(RandDL())
Here is a subclass of DL and in this subclass, we overwrite create_item and create_item normally grabs ith element of the dataset. Now we overwrite to do something else and specifically return some random number so it will return that random number if it is less than 0.95 otherwise stop.
What is stop? Something that will raise stop iteration exception. In Python, the way that generators/iterators say they are finished is that they raise Stop iteration exception so Python actually uses exceptions for control flow which is interesting insight.
Obviously this particular example is a dummy example but in the real world, you can create a callback that will keep reading from network stream until it hits the end of network stream error, then it will stop. So you can easily create streaming DL. So this is an example of Streaming DL.
Note: DL == DataLoader
L(RandDL(bs=4, drop_last=True)).mapped(len)
One of the interesting things about this is you can pass num_workers to be other than 0 and in this case, it will create 4 streaming data loaders which is kind of really interesting idea. So as you can see you end up with more batches than 0 num_worker version because you have more workers which are all doing this job. So they are doing totally independently. That is pretty interesting.
If you don’t set batch_size, then we don’t do any batching this is actually something which is also built into new PyTorch 1.2 DL - this idea of bs of None.
ds1 = DataLoader(letters)
So if we just do DL on letters then we get the same thing because no batching so get back 26 things.
We can shuffle DL.
test_shuffled(L(DataLoader(letters, shuffle=True)), letters)
And if we do that we get exactly the same thing that we started with but just shuffled. So we have something that is test_shuffled that check two args have the same contents but in diff order.
Something else we can do is pass a DS but sometimes DS m,might not have __getitem__ so you might have DS that only has a next. This will be a case of an infinite stream or somewhere where you have 100s of millions of data and you don’t want to enumerate. This is also in PyTorch 1.2 that is the idea of non-indexed or iterable datasets.
Note: DS == Dataset
By default our DL will check if DS has __getitem__ if it does fastai DL will treat as indexed, if not then iterable but you can overwrite this with indexed = False.
ds1 = DataLoader(letters, indexed=False)
So here ds1 is the same as before but it is doing so by calling next and not __getitem__. Really useful for datasets that are really really huge or over the network.
So that is some of that behavior.
Multiple workers test
For DLs that have more than one worker, one of the things that is difficult is to ensure that everything comes back in the same order.
So here is a test that returns an item from a list but adds a random bit of sleep.
class SleepyDL(list):
def __getitem__(self,i):
time.sleep(random.random()/50)
return super().__getitem__(i)
t = SleepyDL(letters)
%time test_eq(DataLoader(t, num_workers=0), letters)
%time test_eq(DataLoader(t, num_workers=2), letters)
%time test_eq(DataLoader(t, num_workers=4), letters)
test_shuffled(L(DataLoader(t, shuffle=True, num_workers=4)), letters)
So here is a test that if we have multiple workers we get things correctly with multiple workers.
Latency test
Here is a similar example
class SleepyQueue():
"Simulate a queue with varying latency"
def __init__(self, q): self.q=q
def __iter__(self):
while True:
time.sleep(random.random()/100)
try: yield self.q.get_nowait()
except queues.Empty: return
q = Queue()
for o in range(30): q.put(o)
it = SleepyQueue(q)
%time test_shuffled(L(DataLoader(it, num_workers=4)), range(30))
This time simulated a queue and it only has __iter__ and not __getitem__ so if we put in DL then it is only able to iterate. So here is a really good example of kind of what it looks like to work with iterable only with variable latency. This is what something streaming over the network might look like.
So we also have a test that we get back the right thing. And also because we only have __iter__ and not __getitem__ so there is no guarantee of the order in which the order the things will come back. So we end up with something that is shuffled.
%time test_shuffled(L(DataLoader(it, num_workers=4)), range(30))
Note: check out itertools standard library that contains lots and lots of things for functional programming in Python.
Let’s look at some interesting things now:
One is,
class RandDL(DataLoader):
def create_item(self, s):
r = random.random()
return r if r<0.95 else stop()
RandDL does not necessarily have to written like this, instead, we could write a function:
def rand_item(s):
r = random.random()
return r if r<0.95 else stop()
L(RandDL(create_item=rand_item))
So we are now not inheriting from DataLoader but instead creating a function. It will do exactly the same thing. We have this nice functionality where nearly everywhere you have CB by inheritance you could also do it by passing in a parameter with the name of the method that you want to overwrite.
Reason - if you have some little function, overwriting is harder. Especially for newer users, they don’t need to understand inheritance. So a lot of documentation and lessons, we will be able to do a lot of stuff without having to teach inheritance.
Let’s look at how it works behind the scenes ie create_item
create_item was one of the things in a long list of _methods passed. It is a special name that will be looked at by @func_kwargs decorator. This decorator is going to look for _nethds and it will say **kwargs in __init__ are not actually unknown but that list of _methods.
It will automatically grab any **kwargs with these names and replace the methods that we have with the thing that is passed to that kwarg. So create_item gets replaced with rand_item.
You can hit shift+tab on DL and you will see all methods are listed. Also, see we have
assert not kwargs and not (bs is None and drop_last)
inside __init__ and the reason for that is @func_kwargs will remove all methods from kwargs once it processes them. So that way you can be sure that you haven’t passed something that wasn’t recognized.
Example, create_batc=1 we get assertion error. So we are kind of getting best of both worlds with discoverability and concise code. This will avoid nasty bugs.
store_attr
self.dataset, self.bs = dataset, bs
Very very often when setting class we store a bunch of items in self. Problem is you have to make sure order is matched correctly if you add or remove you have to add or remove everywhere make sure names are same and a lot of opportunity for bugs.
So
store_attr(self, 'dataset,bs,drop_last,shuffle,indexed') does exactly the same thing and we have to store once. Minor convenience but definitely avoids bugs.
Because we are doing lot of stuff lazily you will see lot of yield and yield from. To understand fastai from the foundations, need to understand these in Python.
def create_batches(self, samps):
self.it = iter(self.dataset) if self.dataset else None
res = map(self.do_item, samps)
yield from res if self.bs is None else map(self.do_batch, chunked(res, self.bs, self.drop_last))
Usually this with something that is a lazy approach, we ended up with something that is easier to understand and with much fewer bugs and concise code.
def __iter__(self):
self.before_iter()
for b in _loaders[self.fake_l.num_workers==0](self.fake_l): yield self.after_batch(b)
self.after_iter()
So then there is this one ugly bit of code which is basically we create an object of type _FakeLoader . Reason for thgat is that PyTorch assumes it will wprkl with object which has _auto_collation,collate_fn,drop_last,dataset_kind,_index_sampler = False,noops,False,_DatasetKind.Iterable,Inf.count specifc list of things in it.
class _FakeLoader(GetAttr):
_auto_collation,collate_fn,drop_last,dataset_kind,_index_sampler = False,noops,False,_DatasetKind.Iterable,Inf.count
def __init__(self, d, pin_memory, num_workers, timeout):
self.dataset,self.default,self.worker_init_fn = self,d,_wif
store_attr(self, 'd,pin_memory,num_workers,timeout')
self.multiprocessing_context = (None,multiprocessing)[num_workers>0]
So we basically have to create an object with those list of things and set it to values that PyTorch expected. And it calls iter on that object and that’s when we pass it back to fastai DL.
def __iter__(self): return iter(self.d.create_batches(self.d.sampler()))
So that’s what that bit of ugly code is. It does mean that unfortunately we have some private things inside PyTorch ie., if something changes inside PyTorch probably means they changed something.
Something else worth mentioning is PyTorch added thing called worker_init_fn which is handy little callback in there DL infrastructure which will be called every time new process is fired off.
So we have a function worker information which calls PyTorch get_worker_info()
#export
def _wif(worker_id):
info = get_worker_info()
ds = info.dataset.d
ds.nw,ds.offs = info.num_workers,info.id
set_seed(info.seed)
ds.wif()
It will tell us what DS it is processed workign with, how many workers are there and what are there IDs so we can ensure each worker has random seed and random seed not duplciated. Also parallelize things automatically insdie DL.
self.lock,self.rng,self.nw,self.offs = Lock(),random.Random(),1,0
We set offset and the number of workers inside __init__ and then we use that in our sampler to ensure each process handles contiguous things, which is different from other processes.
def sampler(self):
idxs = Inf.count if self.indexed else Inf.nones
if self.n is not None:
idxs = list(itertools.islice(idxs, self.n))
idxs = self.shuffle_fn(idxs) if self.shuffle else idxs
return (b for i,b in enumerate(idxs) if i//(self.bs or 1)%self.nw==self.offs)
PyTorch by default calls something called default_collate to take all items in DS and turn them to a batch of you have a bs otherwise it calls somethings called default_convert.
We have our own fa_conver and fa_collate which handles things that PyTorch does not handle. So it doesn’t really change any behavior but it means more things should work correctly.
So create_batch default uses fa_collate or fa_convert depending on whether your bs is None or not. But again, you can replace that with something else.
We do that in Language Model DL. It’s really easy and concise in V2 compared to most libraries and it’s.
TfmDL
Now we can look at TfmDL which inherits from DataLoader. It gets a bunch of kwargs which will be properly documented and tab completed, thanks to @delegates.
This specific list of callbacks is turned into Transform Pipelines. So basically after you have all of the items together but before collating it will run before_batch CB and after callback after_batch will be called. These will be Pipelines.
There are item transforms and TupleTransforms and TupleTransforms are only the ones that have special behavior that are going to be applied to each element in a Tuple and Jeremy mentioned that tfmDS and tfmDL will handle this for us.
kwargs[nm] = Pipeline(kwargs.get(nm,None), as_item=(nm=='before_batch'))
Here it is, so before_batch is the only thing that will be done as_item.
Other ones will be done as TupleTransforms.
The main thing to recognize is tfmDL is a DL and it has 3 callbacks but they are now actual transformation Pipelines which means they handle decodes and that kind of things.
Decodes needs to be able to decode things. One of the things it will need to know what types to decode to. This is tricky for inference for example. Because for inference in Production all you get back is a tensor and that tensor could be anything. So tfmDL has to remember what are the types.
So it stores them under _retain_ds. The types that come out of DS are stored in _retain_ds and types in batching are stored in _retain_dl.
They are stored as partial functions. And we will look at retain_types later but this is the function that knows how to retain types.
Completed notebooks so far: 1c, 08, 05

