Is it possible that is’ using an older version of torchaudio when running the tests? AmplitudeToDB was previously named SpectrogramToDB…
2 Likes
Very possible, I’ll check now. Thanks for the suggestion!
Our version of audio has come a long way, I’ll post notebooks at the end of the week. @baz and I are working on getting all the spectrogram transforms onto the GPU
Most have been straightforward, but I’m having some trouble with SpecAugment and before I dump hours into trying to figure it out I want to make sure I’m on the right track. Here’s the version that works on individual spectrograms:
def MaskFreq(num_masks=1, size=20, start=None, val=None, **kwargs):
def _inner(spectro:AudioSpectrogram)->AudioSpectrogram:
'''Google SpecAugment time masking from https://arxiv.org/abs/1904.08779.'''
nonlocal start
sg = spectro.clone()
channel_mean = sg.contiguous().view(sg.size(0), -1).mean(-1)
mask_val = channel_mean if val is None else val
c, y, x = sg.shape
for _ in range(num_masks):
mask = torch.ones(size, x) * mask_val
if start_ is None: start = random.randint(0, y-size)
if not 0 <= start_ <= y-size:
raise ValueError(f"Start value '{start}' out of range for AudioSpectrogram of shape {sg.shape}")
sg[:,start:start+size,:] = mask
start = None
return AudioSpectrogram.create(sg, settings=spectro.settings)
return _inner
What the transform looks like:
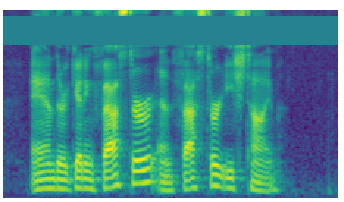
Am I correct in assuming that for a batch of 64, I will need to grab the channel mean of each of those 64 spectrograms, so then I have a 64 layer mask of different values (mask is batch_size by mask_height by sg_width) and then I need to insert that mask at 64 random start positions (otherwise the mask will be in the same position for every image in the batch)? This is bending my brain a little bit and just want to confirm I’m on the right track and there’s not a simpler way. Thanks!
1 Like
So I got the channel mean part working, but I’m still not sure how to make sure the mask is inserted at a different position for each image in the batch. Looking at how RandomResizedCropGPU works in 09_vision_augment, am I right in thinking I need a class to achieve this? I was originally thinking that if I had an array of random insertion points, that I could use that to index into the batch in the same way we did in the batchless version, but I keep running into TypeError: only integer tensors of a single element can be converted to an index. Is there no way to index into a 64x1x128x128 tensor so that each of the 64 images has the mask applied at a different start point in the 3rd dim? Thanks.
It’s difficult, but possible. As well as rrc, which you already noted, there’s also an example in fastai2.medical.imaging.

2 Likes
I’ve managed to get SpecAugment for batches working with two different methods:
Method 1
Uses a for loop but is decorated as a torch script to speed it up
@torch.jit.script
def spec_aug_loop(batch:Tensor, size:int=20):
bsg = batch.clone()
max_y = bsg.shape[-2]-size-1
for i in range(bsg.shape[0]):
s = bsg[i, :]
m = s.flatten(-2).mean()
r = torch.randint(0,max_y,(1,)).squeeze().int()
s[:, r:r+size, :] = m
return bsg
2.83 ms ± 125 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Method 2
Using masks to replace the values in random places
@torch.jit.script
def spec_augment(batch:Tensor, size:int=20):
bsg = batch.clone()
bs, _, x, y = bsg.shape
max_y = y-size-torch.tensor(1)
m = torch.arange(y).repeat(x*bs).view(bs,-1)
rs = torch.randint(0,max_y,(1,bs)).squeeze()[None].t()
gpumask = ((m > rs)) & (m < (rs+size))
gpumask = gpumask.view(bs,x,-1)[:,None,:]
bsg[gpumask] = torch.tensor(0)
return bsg
7.26 ms ± 81.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
The clear winner is method 1 but I believe that there must be something I can do to speed up method 2
3 Likes
Update: We’ve reached a point where we think we have a good working version, but before building on top of it further we feel we could use some feedback in case our implementation has major flaws. We’re hoping @jeremy, @sgugger, @muellerzr, @arora_aman or any others who have been really active in the v2 chat and dev repo can take a quick look and make suggestions. We know everyone is extremely busy with getting v2 ready to ship, so if you don’t have time we understand, but feedback of any kind (especially critical) would be greatly appreciated. Thank you.
Repo: https://github.com/rbracco/fastai_dev/tree/audio_development
NBViewer Notebook Links:
What we could really use feedback on before proceeding:
- The low-level implementation of AudioItem, AudioSpectrogram, AudioToSpec/AudioToMFCC and how we chose to wrap torchaudio and extract default + user-supplied values to be stored in spectrogram.
- How to best GPUify everything. We think using SignalCropping to get a fixed length is the only thing we need to do on the CPU, and all signal augments, conversion to spectrogram, and spectrogram augments can be done on GPU. @baz, could you please post your latest GPU nb and questions here to get feedback?
- Where we should be using RandTransform for our augments.
Known bugs:
-AudioToSpec used to tab-complete with all potential arguments, but stopped recently, we’re trying to trace it.
-Spectrogram display with colorbar + axes doesnt work for multichannel audio, or delta+accelerate (anything that is more than one image)
-Show_batch is currently broken, we know how to fix it but it breaks spectrogram display. There’s a detailed note in the nb.
**Showcase of some high-level features:**
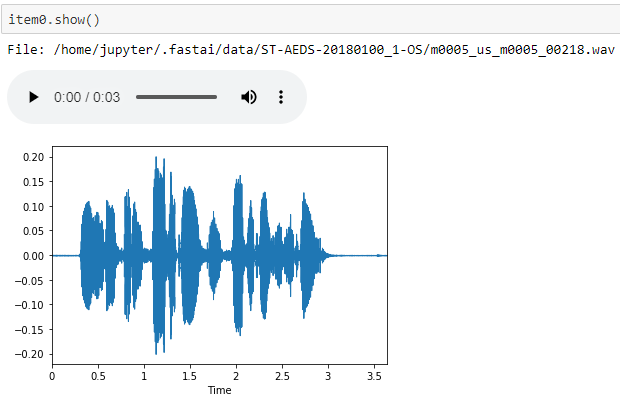
AudioItems display with audio player and waveplot:
Spectrograms store the settings used to generate them in order to show themselves better
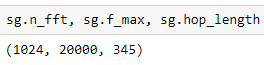
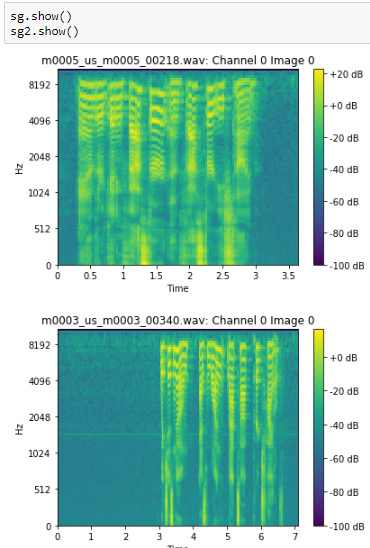
Spectrograms display with decibel colorbar (if db_scaled), time axis, frequency axis. Thanks @TomB for suggesting this
Create regular or mel spectrograms, to_db or non_db easily from same function.
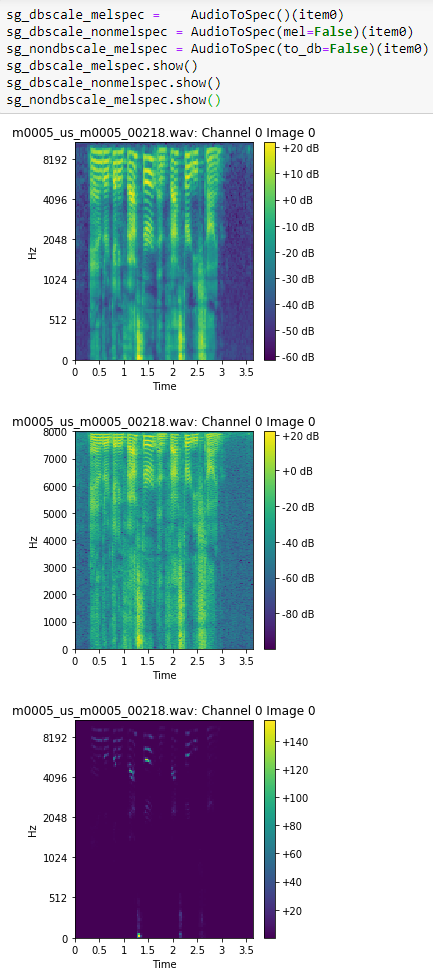
Warnings for missing/extra arguments. If you pass a keyword argument that won’t be applied to the type of spectrogram you’re generating (in this case non-mel spectrogram), you’ll get a warning.

AudioConfig class with optimized settings users can apply to their audio subdomain, e.g. AudioConfig.Voice, which will set the defaults to be good values for voice applications.
Easy MFCC generation, photo is a bad example as it currently stretches to plot, actual data is only 40px tall.
Features in NB71 audio_augment:
- Preprocessing
- Silence Removal: Trim Silence (remove silence at start and end) or remove all silence.
- Efficient Resampling
- Signal Transforms (all fast)
- Signal Cropping/Padding
- Signal Shifting
- Easily add or generate different colors of noise
e.greal_noisy = AddNoise(noise_level=1, color=NoiseColor.Pink)(audio_orig) - Augment volume (louder or quieter)
- Signal cutout (dropping whole sections of the signal) and signal dropping (dropping a % of the samples, sounds like a bad analog signal, code for this is adapted from @ste and @zcaceres, thank you!)
- Downmixing from multichannel to Mono
- Spectrogram Transforms
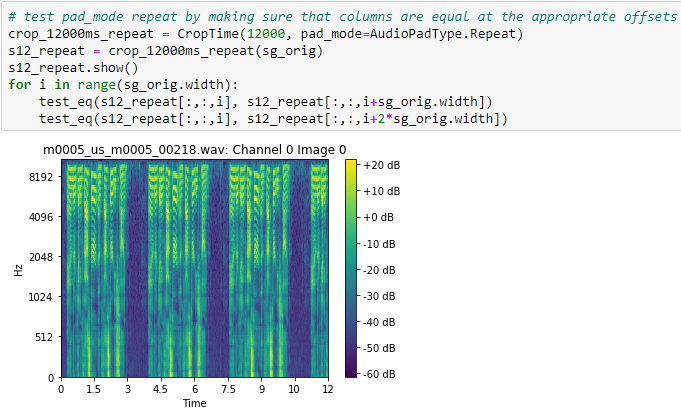
- Time Cropping with zero and repeat padding
- Frequency Masking and Spec Masking (Spec Augment)
- Spectrogram Shifting/Rolling
- Append delta and accelerate (1st and 2nd derivatives of sg)
- Time Cropping with zero and repeat padding
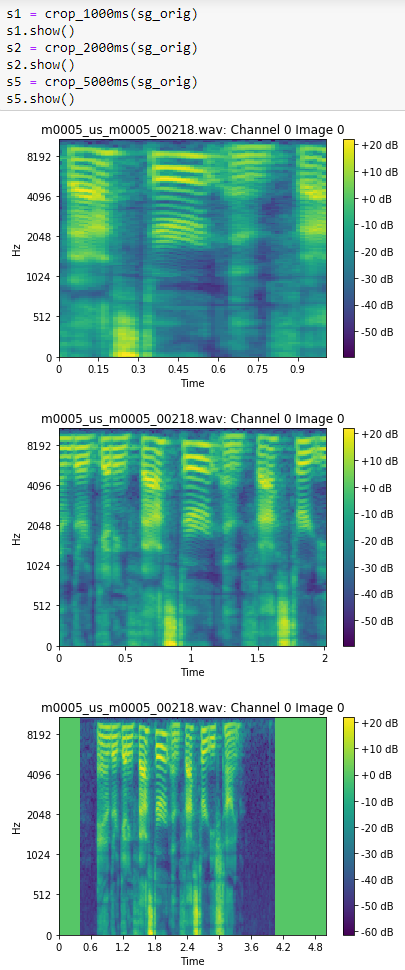
Results from 72_audio_tutorial:
-99.8% accuracy on 10 speaker voice recognition dataset
-95.3% accuracy on 250 speaker voice recognition dataset
14 Likes
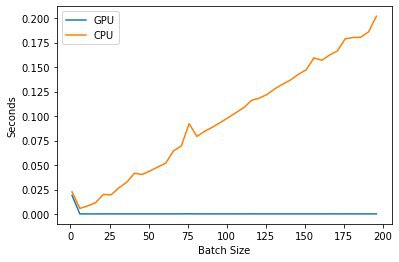
Transforming from Signal to Spectrogram is much faster as show in the graph below. When I baked it into the v2 api, I got strange results with CPU epochs trippling. More details of this can be found here.
GPU vs CPU Audio To Spectrogram
I crop the signals before allowing the gpu and cpu convert them to spectrograms.
Spec Augment
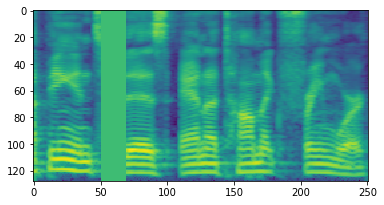
In the post above you can see the methods I have created for specaugment. The vectorised one is slower for some reason.
Shift / Roll
I haven’t tried these yet but but now that I’ve done Spec Augment I think that they are probably vectorisable
Questions
- As @MadeUpMasters has said, where should the transforms be going and as they are random, should they be extending the class RandTransform.
- Generally where would you see the GPU Batch Transforms being placed.
- @MadeUpMasters has created pre-setup audio configurations for different classifcation problems. How can we further improve the lives of beginners when approaching audio classification?
- Many of the pre-processing transforms (Cropping, Removing Silence, Resampling) are not randomised and could be preserved. Considering that they took a long time before we decided to cache them in fastai_audio v1 . This was quite messy in implementation with the old API but I believe that it coudl be much cleaner with the new API. What are you thoughts on this?
- We’ve mainly focused on classification and therefore Spectogram generation as that seems to be the SOTA approach but there is a huge potential for using RNN’s for ASR etc. In your mind what is the scope of the fastai audio module, how many audio problems should we tackle?
1 Like
I’ve managed to improve method 2 to <700us which is faster than the for loop
@torch.jit.script
@torch.no_grad()
def spec_augment(sgs:Tensor, size:int=20):
bsg = sgs.data
device = sgs.device
bs, _, x, y = bsg.shape
max_y = y-size-1
rsize = torch.tensor(x*bs)
m = torch.arange(y,device=device).repeat(rsize).view(bs, -1)
rs = torch.randint(0, max_y,(bs,1), device=device)
gpumask = ((m < rs) | (m > (rs+size))).view(bs, 1, x, -1)
return bsg*gpumask
646 µs ± 4.37 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
3 Likes
Thanks @MadeUpMasters, would love to give it a try. I will get back to you if I find anything! 
2 Likes
Thanks @MadeUpMasters, it looks awesome!
I am not active in the v2 chat or dev repo and can’t give any deep feedback about the technical part (except it’s much better than my bicycles and I start throwing mine away and replacing them with your code ). I think I have a few thoughts about other stuff that can be useful not only for me when working with audio:
- Support for other types of noise that based on actual audio samples (from audio noise datasets or urban noises datasets). Example of a dataset is something like - https://urbansounddataset.weebly.com
Plus some logic/tranformers to mix such noise on different levels
- Support for perceptual audio loss functions. Loses that bases on PESQ/POLQA give huge improvement for task-related with speech quality evaluation and can be a huge advantage for the fastai if it will be supported out of the box.
A few interesting works in this area:
http://sigmat.ugr.es/PMSQE/
At the moment I don’t think I am ready to share any code or to do any useful PRs related to those problems (maybe in the future, who knows…). Therefore, for now only ideas, but I hope they maybe useful somehow. And thanks again, your work is awesome and I already start adopting it for my experiments!
3 Likes
Thank you for looking over it for us, I really appreciate it.
This is coming, we’ve mostly messed around with voice in v2, but in the v1 library we did a lot of urban sounds stuff including getting a new SOTA on the ESC-50 Dataset, something that @KevinB and @hiromi have successfully replicated in v2. v2 will have preset defaults for the various audio problems (voice rec, ASR, scene classification, music…etc) so that people with no audio experience can have great defaults.
This is quite cool (and advanced!), thanks for sharing, I wasn’t aware of audio perceptual loss, just image feature loss from part 1 of the course. I read the papers and these are implemented quite differently from feature loss in fastai. The approach is to train a model to approximate PESQ since PESQ isnt differentiable, and models are, then use PESQ as the critic for a second model which is trying to generate or denoise audio.
I don’t see any reason we couldn’t implement this (train the critic and make it available as a loss function), but since we haven’t ventured into any generative audio stuff yet, it will probably be some time before adding it.
Thanks again for the feedback and feel free to reach out with more as your experiments progress. Cheers.
2 Likes
Hi!
Seems I found a small issue:
@patch_to(cls=AudioItem)
def from_raw_data(cls, data, sr):
data = tensor(data)
if data.dim() == 1:
data = data.view(1,-1)
return cls((data, sr, Path('raw')))
AudioItem.from_raw_data = classmethod(AudioItem.from_raw_data)
freq = 440
sr = 16000
item = AudioItem.from_raw_data(data = librosa.tone(frequency=freq, sr=sr, length=2000), sr = sr)
a2s = AudioToSpec.from_cfg(AudioConfig.Voice())
a2s(item).show()
Gives:
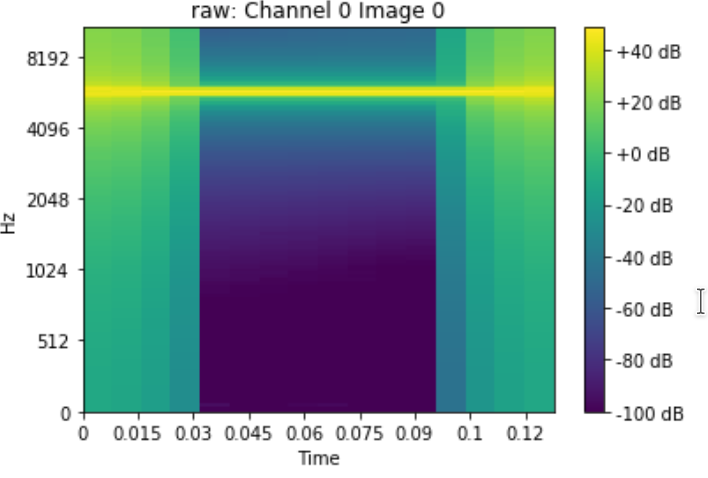
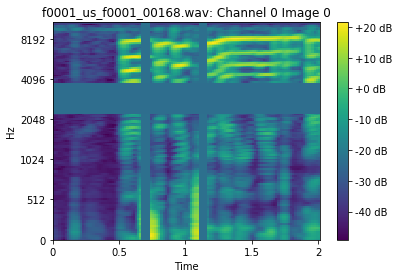
Looks like it shows results upside-down or at least left Hz bar is not consistent with the picture.
With kind regards,
Vadim.
1 Like
Could I please ask if the work on v2 is still taking place? It doesn’t seem to be happening in the fastai_audio repo? BTW the tutorials in the repo are top notch, they were very helpful to me and are really well written! Thank you for putting them together.
2 Likes
Work on v2 is still taking place, the latest update was posted here: Fastai v2 audio
Really excited to hear you found the tutorials useful! I plan to go back at some point and add a lot more as I’ve learned more about signal processing, as well as experimented with a lot of new things like training on raw audio, audio embeddings…etc. What I have so far barely scratches the surface.
3 Likes
Thank you very much for the update! ![]()
Would love to read this.
My plan is this:
- continue to learn about fastai v2
- study the materials you share above
- use fastai audio in the freesound starter pack (I first want to train on spectograms using the setup I already have, but the next step IMO would be fastai audio, I am using fastai v2)
I am not sure how things will go but maybe there will be a chance for me to do something useful for the project. It could be as little as test driving the functionality you create or maybe helping in some way with fastai v2 integration. Anyhow, just a thought at this point in time, look forward to getting up to speed with the v2 port ![]()
1 Like
Awesome, a great place for audio resources (and asking questions) is the Deep Learning with Audio Thread. Please let me know if you find anything helpful that isnt listed there and I can get it added.
1 Like
An update on v2 audio, it is mostly functional, we just need some pieces of the high-level API put on top, and to fix a few places we feel like we could be doing things better/faster/more v2-like but aren’t sure exactly how to get there. I’m going to make a series of posts about each issue, so if you have ideas/questions or want to participate in the discussion, even if you know nothing about audio, please jump in. Also any feedback on making the posts more useful/readable is appreciated.
Issue 1: Getting transforms to use TypeDispatch, RandTransform, and be GPU-friendly
We have a lot of transforms for AudioSignals and AudioSpectrograms that were originally made as simple independent functions. Many transforms for signals are the same as those for spectrograms, just with an extra dimension. For instance, we may want to cut out a section of the data, for AudioSignals this is “cutout”, for AudioSpectrograms it “time masking”, but they’re the same idea just on 2D (channels x samples) and 3D (channels x height x width) tensors respectively. Given the functionality of v2, we would like to refactor many of these to use RandTransform, TypeDispatching and be easily transferable to GPU.
I am having trouble figuring out exactly how to design a transform that works on signals and spectrograms, individual items and batches, implements RandTransform, and is fast. If I get one, I should be able to copy the pattern to the others. I tried looking in 09_data_augment but it wasn’t that clear to me how to make it work for my code.
Here is my best attempt so far. It’s for shifting the data horizontally (roll adds wraparound) It works properly, but is much slower than my original transforms, 557µs for a single item and 2.35ms for a batch of 32 signals (CPU), compared to 54µs for a single item previously.
Questions @jeremy @baz:
- Is it more or less correctly implemented, and how can I improve it with respect to…
- TypeDispatch - Making it work for both signal/spectrogram simultaneously?
- GPU - Making it work on both batches and individual items?
- RandTransform - Am I using it properly here?
- Any ideas on how to make it faster? Code of the original transform included at bottom.
Code:
class SignalShifter(RandTransform):
def __init__(self, p=0.5, max_pct=0.2, max_time=None, direction=0, roll=False):
if direction not in [-1, 0, 1]: raise ValueError("Direction must be -1(left) 0(bidirectional) or 1(right)")
store_attr(self, "max_pct,max_time,direction,roll")
super().__init__(p=p, as_item=True)
def before_call(self, b, split_idx):
super().before_call(b, split_idx)
self.shift_factor = random.uniform(-1, 1)
if self.direction != 0: self.shift_factor = self.direction*abs(self.shift_factor)
def encodes(self, ai:AudioItem):
if self.max_time is None: s = self.shift_factor*self.max_pct*ai.nsamples
else: s = self.shift_factor*self.max_time*ai.sr
ai.sig[:] = shift_signal(ai.sig, int(s), self.roll)
return ai
def encodes(self, sg:AudioSpectrogram):
if self.max_time is None: s = self.shift_factor*self.max_pct*sg.width
else: s = self.shift_factor*self.max_time*sg.sr
return shift_signal(sg, int(s), self.roll)
def _shift(sig, s):
samples = sig.shape[-1]
if s == 0: return torch.clone(sig)
elif s < 0: return torch.cat([sig[...,-1*s:], torch.zeros_like(sig)[...,s:]], dim=-1)
else : return torch.cat([torch.zeros_like(sig)[...,:s], sig[...,:samples-s]], dim=-1
def shift_signal(t:torch.Tensor, shift, roll):
#refactor 2nd half of this statement to just take and roll the final axis
if roll: t[:] = torch.from_numpy(np.roll(t.numpy(), shift, axis=-1))
else : t[:] = _shift(t[:], shift)
return t
Here’s the original code that works only on a signal:
def _shift(sig, s):
channels, samples = sig.shape[-2:]
if s == 0: return torch.clone(sig)
elif s < 0: return torch.cat([sig[...,-1*s:], torch.zeros_like(sig)[...,s:]], dim=-1)
else : return torch.cat([torch.zeros_like(sig)[...,:s], sig[...,:samples-s]], dim=-1)
#export
def ShiftSignal(max_pct=0.2, max_time=None, roll=False):
def _inner(ai: AudioItem)->AudioItem:
s = int(random.uniform(-1, 1)*max_pct*ai.nsamples if max_time is None else random.uniform(-1, 1)*max_time*ai.sr)
sig = torch.from_numpy(np.roll(ai.sig.numpy(), s, axis=1)) if roll else _shift(ai.sig, s)
return AudioItem((sig, ai.sr, ai.path))
return _inner
2 Likes
Issue 2: Should transforms mutate in place, or return altered copies?
Am I correct in noticing that the RandTransforms inside 09_vision_augment are not cloning the Image data but are mutating it in place? Is this just because in the Pipeline stuff is constantly being created and destroyed each batch? Any reason we shouldn’t follow this pattern for audio? @jeremy @baz
Example v2 vision transform for reference:
1 Like
Yes, there is no need to retain a copy of the original batch. On the contrary, the goal is to save GPU memory as much as possible.
1 Like