Reposting an update from our fastai v2 Audio thread in case anyone here is interested in helping out. We’ve reached a point where we think we have a good working version, but before building on top of it further we feel we could use some feedback in case our implementation has major flaws. If anyone wants to play around with it, especially looking at the low-level implementation details and providing any feedback, @baz and I would appreciate it greatly. Thank you.
Repo: https://github.com/rbracco/fastai_dev/tree/audio_development
NBViewer Notebook Links:
What we could really use feedback on before proceeding:
- The low-level implementation of AudioItem, AudioSpectrogram, AudioToSpec/AudioToMFCC and how we chose to wrap torchaudio and extract default + user-supplied values to be stored in spectrogram.
- How to best GPUify everything. We think using SignalCropping to get a fixed length is the only thing we need to do on the CPU, and all signal augments, conversion to spectrogram, and spectrogram augments can be done on GPU. @baz, could you please post your latest GPU nb and questions here to get feedback?
- Where we should be using RandTransform for our augments.
Known bugs:
-AudioToSpec used to tab-complete with all potential arguments, but stopped recently, we’re trying to trace it.
-Spectrogram display with colorbar + axes doesnt work for multichannel audio, or delta+accelerate (anything that is more than one image)
-Show_batch is currently broken, we know how to fix it but it breaks spectrogram display. There’s a detailed note in the nb.
Quick showcase of some high-level features:
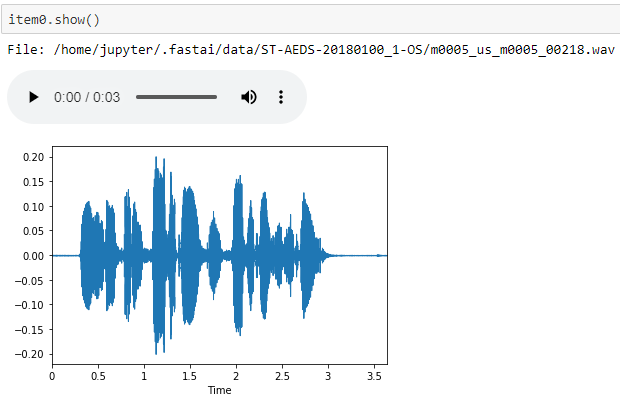
AudioItems display with audio player and waveplot:
Spectrograms store the settings used to generate them in order to show themselves better
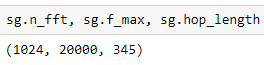
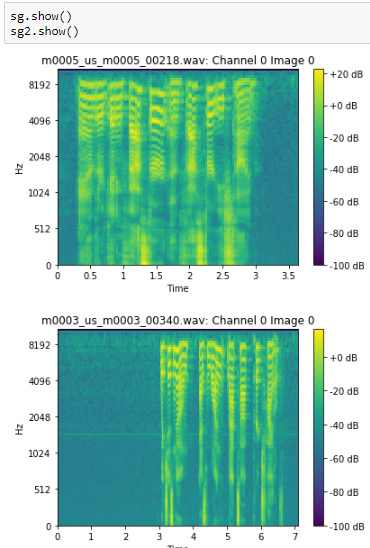
Spectrograms display with decibel colorbar (if db_scaled), time axis, frequency axis. Thanks TomB for suggesting this
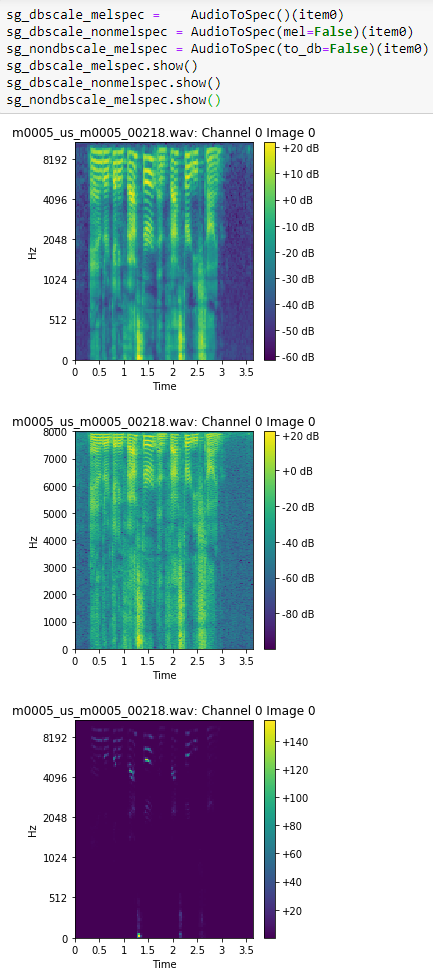
Create regular or mel spectrograms, to_db or non_db easily from same function.
Warnings for missing/extra arguments. If you pass a keyword argument that won’t be applied to the type of spectrogram you’re generating (in this case non-mel spectrogram), you’ll get a warning.

AudioConfig class with optimized settings users can apply to their audio subdomain, e.g. AudioConfig.Voice, which will set the defaults to be good values for voice applications.
Easy MFCC generation, photo is a bad example as it currently stretches to plot, actual data is only 40px tall.
Features in NB71 audio_augment:
- Preprocessing
- Silence Removal: Trim Silence (remove silence at start and end) or remove all silence.
- Efficient Resampling
- Signal Transforms (all fast)
- Signal Cropping/Padding
- Signal Shifting
- Easily add or generate different colors of noise
e.greal_noisy = AddNoise(noise_level=1, color=NoiseColor.Pink)(audio_orig) - Augment volume (louder or quieter)
- Signal cutout (dropping whole sections of the signal) and signal dropping (dropping a % of the samples, sounds like a bad analog signal, code for this is adapted from ste and zcaceres, thank you!)
- Downmixing from multichannel to Mono
- Spectrogram Transforms
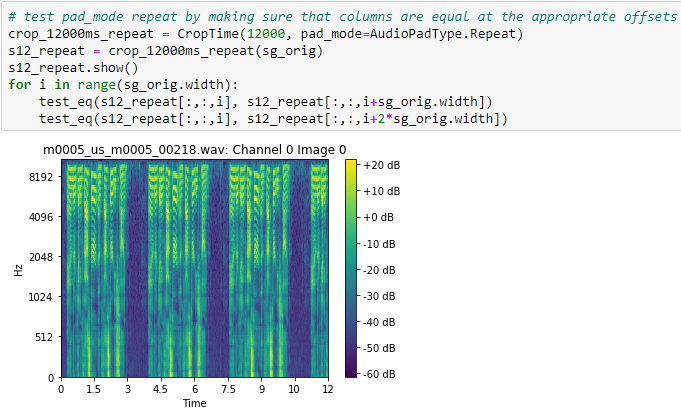
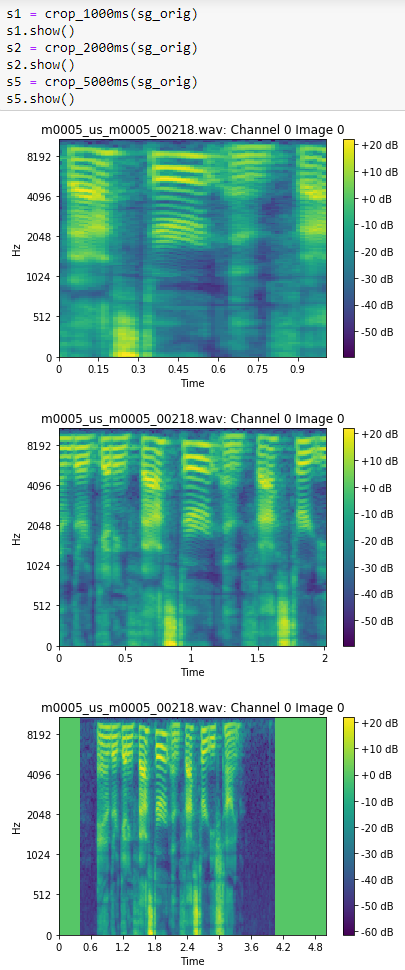
- Time Cropping with zero and repeat padding
- Frequency Masking and Spec Masking (Spec Augment)
- Spectrogram Shifting/Rolling
- Append delta and accelerate (1st and 2nd derivatives of sg)
- Time Cropping with zero and repeat padding
Results from 72_audio_tutorial:
-99.8% accuracy on 10 speaker voice recognition dataset
-95.3% accuracy on 250 speaker voice recognition dataset