Thanks for starting this Kevin, it will be good to have a thread to discuss issues/features/design choices. Repo is currently here: Github Unofficial Fastai Audio. We are accepting contributors of all skill levels if anyone is interested in helping out.
The goal is to make audio ML as easy and seamless as possible for everybody. Fastai vision is a perfect example of this, you definitely don’t need to know the nuances of computer vision to use it. We hope to do the same with audio, abstracting away as much as possible while leaving doors open for people to dig deeper if they do have/want that audio domain knowledge.
A secondary goal is getting it merged into fastai. We are starting to refactor to make it compatible w fastai v2, and also to meet the documentation/design/testing specs that fastai v2 supports.
I managed to do an early edit and release to help people jumping in for fast.ai audio: Here’s my interview with @MadeUpMasters all about the unofficial fast.ai audio library, self-study in ML.
Hi @MadeUpMasters and @init_27
I’ve just learnt a lot by listening to the Podcast. I think the best advice came for me when Robert you mention that we sometimes fall into the “infinite learning” loop of jumping from one course to another.
I believe this is the loop I am in too and haven’t built anything substantial yet.
I’ll be going through fastai_audio and find ways to contribute. Cheers
Awesome! PM me if you’d like to be added to our telegram chat either for Audio ML or for working on the library. You can join the chat without working on the library as well, just to see what’s going on.
Currently we are working on reviewing/merging a PR by @KevinB and @hiromi that adds handling for multichannel audio (we previously downmixed it to mono), and refactors some things. Once that is stable and in we are turning full focus to v2, moving everything to notebook development, docs and testing.
Once our environment is set up we are going to focus on refactoring for compatibility with fastai v2, hopefully contributing what we can to the main fastai v2 codebase in the process.
The daily v2 chat with Jeremy was really helpful and if you are interested in helping us with audio I’d recommend tuning in daily or watching the recordings if you can’t make it.
So just thinking of a few things we will need. get_audio_files should be pretty easy because we already have that in from_folder. we’ll want to bring over audio_extensions as well and should be able to use get_files the same that we do today. Instead of building AudioItem, I think we will want to create a typeclass (might not be using the correct word there) and all of the transforms to go from filepath to spectrogram. Probably will also want a filepath to signal or something similar to that for people that want to work on raw audio signals. I’m sure there is a ton that I’m missing here, but that’s my current thought.
I started working on a prototype of fastai audio V2 on my own fork here. Audio notebooks start at 70.
The biggest change so far is that the old AudioItem is broken into two items now: a new AudioItem that holds only the signal and the sampling rate, and a AudioSpectrogram that contains the Spectrogram created from the audio signal, with the transform Audio2Spec that maps between the two.
Transforms have been migrated and are working on TorchAudio 0.3.0. At the end of notebook 71_audio_transforms there is an example of using the new transforms end-to-end to go from Path objects to Spectograms with data augmentation working.
Other members of the audio community are going to do their own implementations, as we are not certain on what the lower level api’s should be.
After watching the first walk-thru, I created this PR mostly to get us started and to have the notebook number figured out (sorry, I started with 60 as that was the next available). But code-wise, it looks like we were on the same page
In order to create a fastai v2 version in the fastai_audio repo, you probably want to be able to pip install fastai v2. Which means we need a setup.py file! I’m happy to add that soon (we can call the pip project fastai2 for now).
Is there an advantage to putting this in the fastai_audio repo versus a fork of fastai_dev? I am just thinking that with all of the improvements being made to fastai_dev, it would be better to be as close to that as possible so we can just pull upstream.
Once we have setup.py, we should be able to do pip install -e . from cloned fastai v2 repo and get the same effect.
What we won’t have right away are all the notebook tools - stripping out the output, mechanism to export, local imports, __all__ generation, @docs, etc.
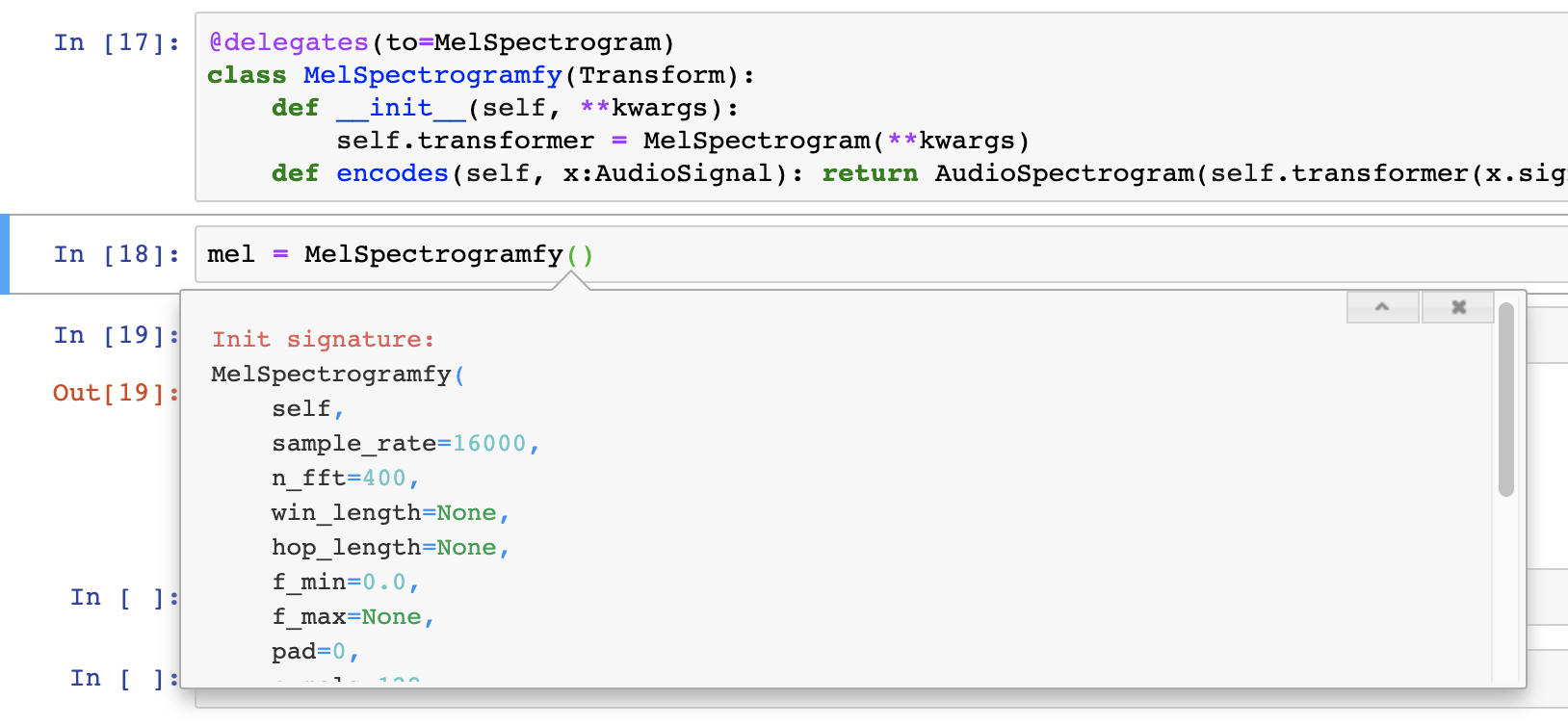
I didn’t want to subclass MelSpectrogram but I wanted the tab completion to still work. I then noticed the to argument in @delegates, and it works like a charm:
I am hosting some small datasets to be used for development. I assume that these will eventually be hosted on the files.fast.ai but for now you can access them here:
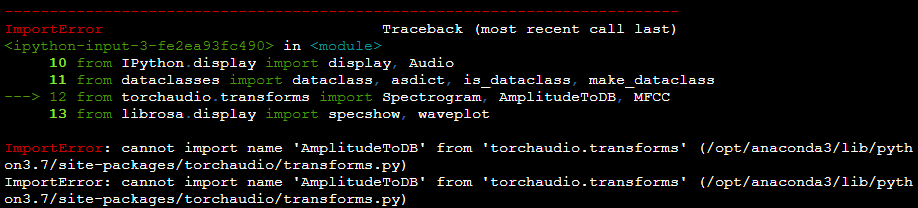
We’ve started to add testing and I ran into this issue when running the tests (for audio nbs 70/71 only) automatically from the command line using the command provided in the readme. The notebook runs fine on it’s own, any idea why it can’t import properly?
Are there any good resources besides the readme for testing? Maybe a code walkthrough that discussed it? Or is it as simple as just adding tests from 00_test throughout nbs? Thanks!
For testing I can’t think of anything to add other than to just add tests to your notebooks… But let me know if anything is unclear as you do it, and we can start adding any testing docs that are needed based on your feedback and questions.