Hi everyone,
I just came across this audio extension for fastai and I was amazed. I’m trying to write a naive app to classify between 2 data sources. The model trains well, thanks to the notebook provided on GitHub.
I’m trying to load a single wav file and get predictions but I’m doing something wrong here.
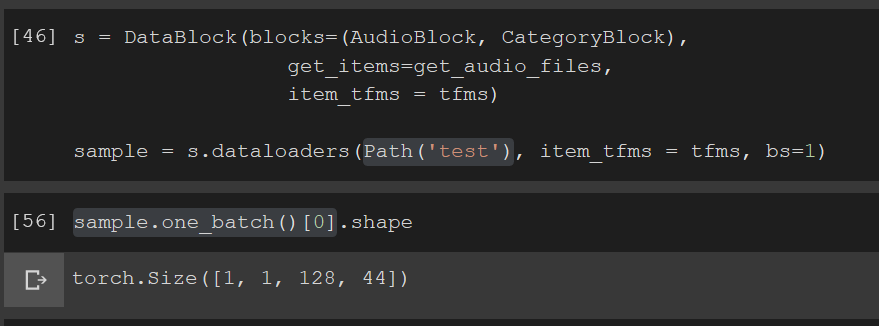
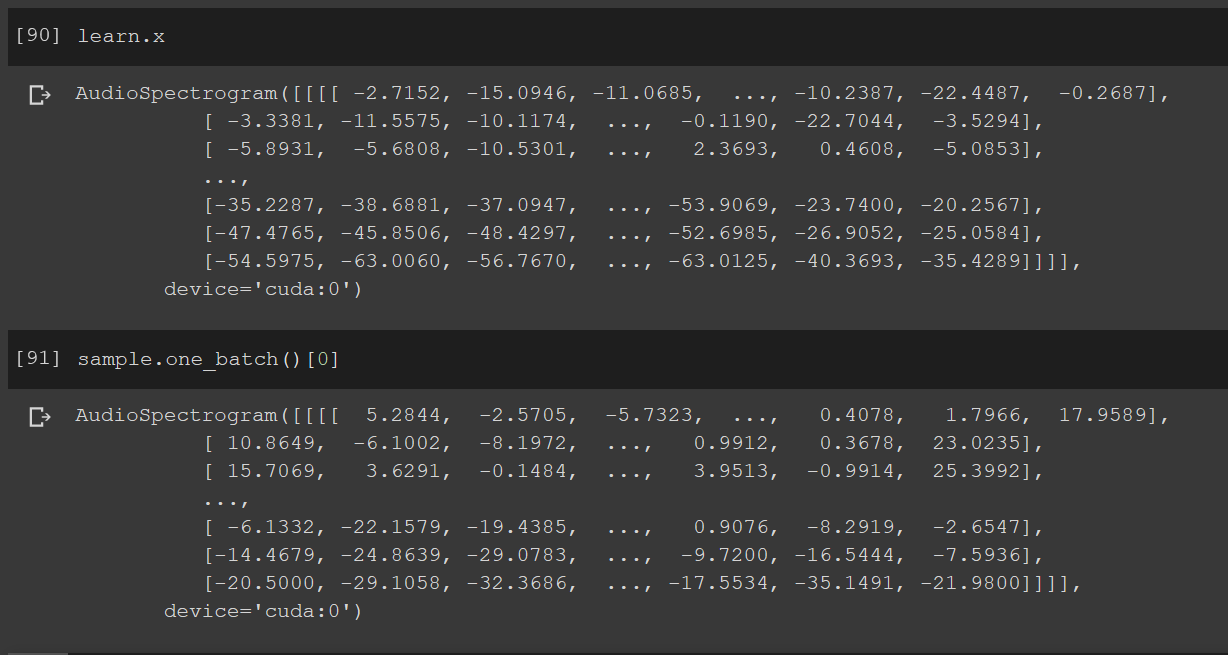
I created this single file batch to get predictions and the types for learner.x and my single input are the same
But I’m getting the below error
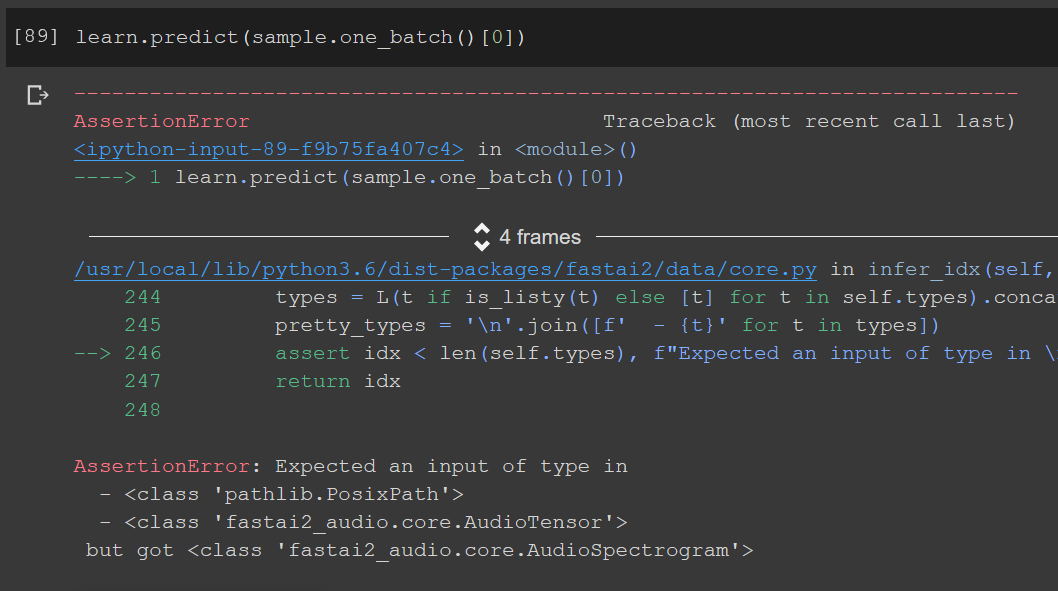
I don’t understand why the learner is looking for an AudioTensor file and when I simply pass the path to test file it can’t process it. I’m sure I’m missing a key understanding of Data Block API here, please help.
Following up, I was able to collect my sample as an AudioTensor but the predict method still doesn’t work.
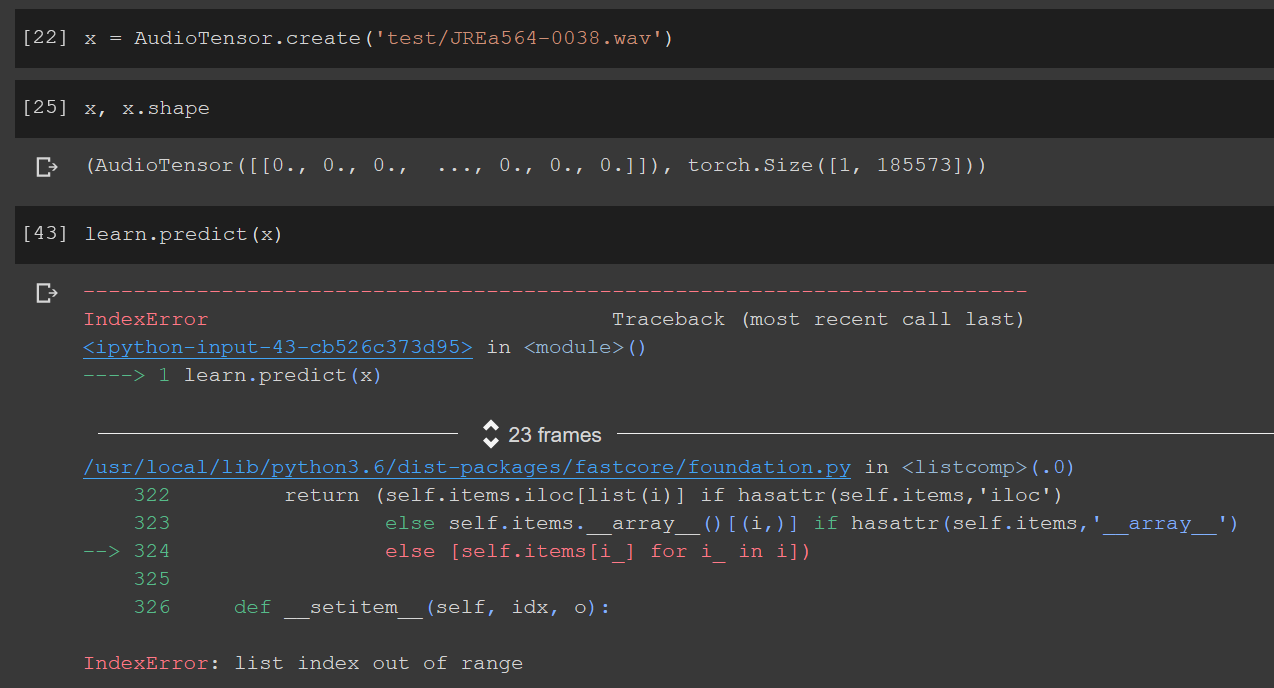
@muellerzr Maybe you can help, I picked the AudioTensor creation part from your video tutorial. My apologies, I usually don’t at-mention at all but I’m fighting this for the last 6 hours and going crazy. And I just found a similar thread and I’m not sure if it’s a fastaiv2 issue.