Well done on all the work here folks, just after watching @muellerzr’s run through, this lib looks super useful!
I am hoping to use it in kaggle’s deepfake comp as some of the videos also have fake audio. Just wondering if anyone has any suggestions on the easiest way to extract audio from mp4 files? And is there a preferential format I should save them to?
ffmpeg is a great tool to manipulate video and audio via the command line on linux, the usage may look scary at first but it’s very powerful. To extract the audio from only one video:
If you search on the internet you’ll find some posts listing all of the different ways you can use ffmpeg like this one. To process multiple files, it’s just a matter of using a bash loop:
for vid in *.mp4; do ffmpeg -i "$vid" -vn -acodec pcm_s16le -ac 1 -ar 16000 "${vid%.mp4}.wav"; done
About the format, .wav with this coded is a common choice for audio data. The only parameters that you should change are the channels to 2 if you want to use stereo audio, and the sampling rate. For pure voice audio, 8 khz (-ar 8000) should be enough, but if you have other sources of sound besides voice you may want to use 16 khz (-ar 16000) or even 44.1 khz (-ar 441000). Those rates are directly related to the highest frequency present in your audio and the Nyquist theorem.
Amazing, appreciate it! Its only voice, although maybe I’ll us 16 khz because the goal is identify fake/manipulated voice, so maybe some crazy artefacts show up beyond the expected 8 khz…thanks again!
I thought I’d introduce myself after lurking for enough time! My background is in acoustic consultancy/engineering and I’m currently making a career change towards ML. I’m currently doing the Udacity ML Engineer Nanodegree and will (hopefully) be going to Georgia Tech to start the OMSCS ML specialization later in the year.
First of all, I absolutely love the work you all have done - machine listening is such a fascinating area, so I would love to contribute however I can. I also have my own personal project working on bird sound recognition for an area next to a national park in Colombia, near where I’m lucky enough to live (Bogotá), so will have a play around with V2 and feedback in due course. I used V1 late last year and it worked pretty well with mel-spectrograms on a dataset of xeno-canto recordings of 134 bird species ranging from excellent to pretty dodgy quality, so I’m excited to see how V2 can do.
I would like to use the library for my Udacity Capstone project, would you recommend I stick with V1 for now or go ahead with V2?
Hi all, I’m having some trouble running my code on the google tpu using a colab notebook. I thought you might have some more experience in this field and I’m trying to ask here.
I’m trying to run a pytorch script which is using torchaudio on a google TPU. To do this I’m using pytorch xla following this notebook, more specifically I’m using this code cell to load the xla:
!pip install torchaudio
import os
assert os.environ['COLAB_TPU_ADDR'], 'Make sure to select TPU from Edit > Notebook settings > Hardware accelerator'
VERSION = "20200220" #@param ["20200220","nightly", "xrt==1.15.0"]
!curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
!python pytorch-xla-env-setup.py --version $VERSION
import torch
import torchaudio
import torch_xla
however this is incompatible with the version of torchaudio that I need as: ERROR: torchaudio 0.4.0 has requirement torch==1.4.0, but you'll have torch 1.5.0a0+e95282a which is incompatible.
I couldn’t find anywhere how to load torch 1.4.0 using pytorch xla.
I tried to use the nightly version of torch audio but that gives the error as follows:
I just came across this audio extension for fastai and I was amazed. I’m trying to write a naive app to classify between 2 data sources. The model trains well, thanks to the notebook provided on GitHub.
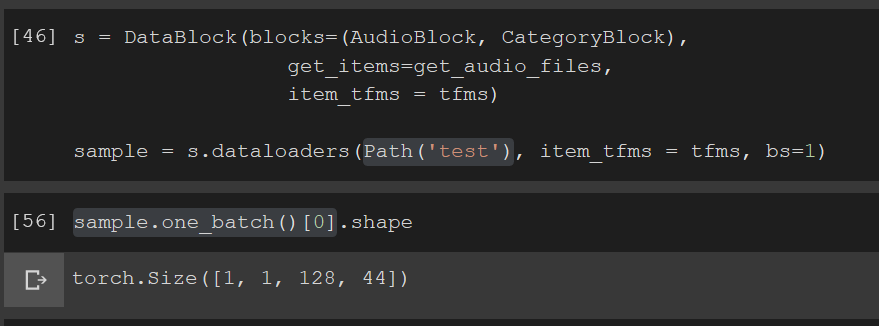
I’m trying to load a single wav file and get predictions but I’m doing something wrong here.
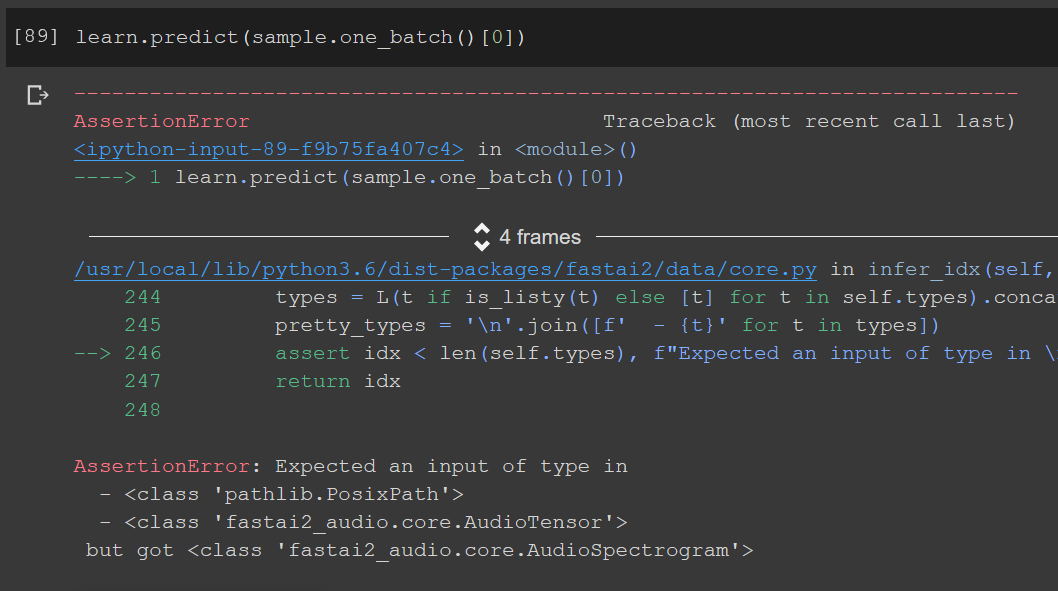
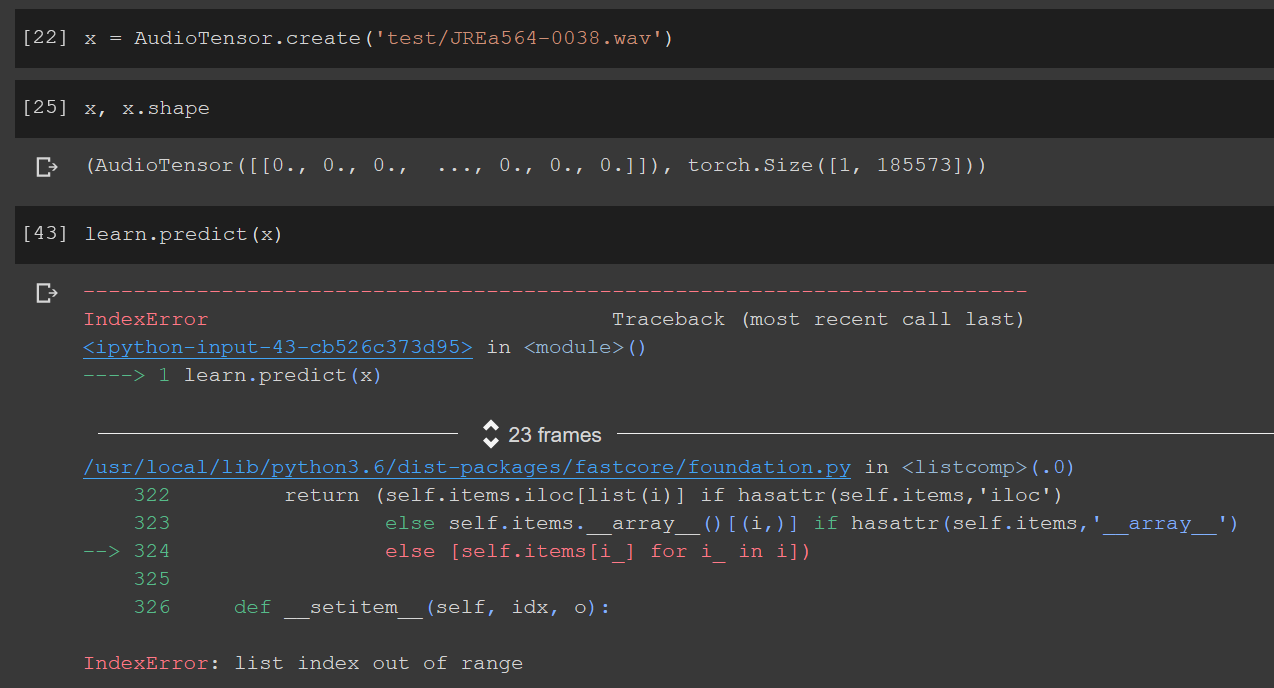
I don’t understand why the learner is looking for an AudioTensor file and when I simply pass the path to test file it can’t process it. I’m sure I’m missing a key understanding of Data Block API here, please help.
@muellerzr Maybe you can help, I picked the AudioTensor creation part from your video tutorial. My apologies, I usually don’t at-mention at all but I’m fighting this for the last 6 hours and going crazy. And I just found a similar thread and I’m not sure if it’s a fastaiv2 issue.
Thanks again. In case you want a reproducible check for the audio library, the notebook has all the components. I’ll keep looking on the audio side now.
Update: I checked last 8 commits for fastcore and the error is not related. Will look back further, I think Slyvian will know how to fix this.
Predict does not work because your loss does not have an activation and a decodes method. The first one should do the softmax, the second should do the argmax (look at CrossEntropyFlat() in fastai2 for inspiration)
Thanks! I should have observed that when torch.nn.CrossEntropy failed and then it worked with CrossEntropyLossFlat. Your reply was very helpful and saved a lot of time. I wrote a similar extension as FocalLossFlat by adding activation and decode method and that part works. Although I have some new attribute errors with the AudioSpectogram, I think I should be able to fix them
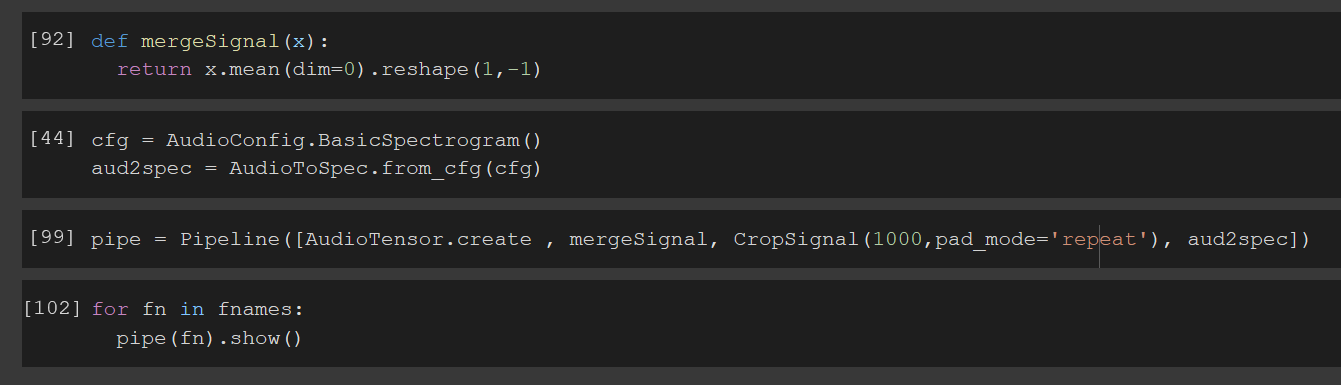
Is there a way to process audio files of different duration?
The transforms API helps me get Spectrograms for every file but the dimensions are all over the place. Using CropSignal doesn’t help as well all.
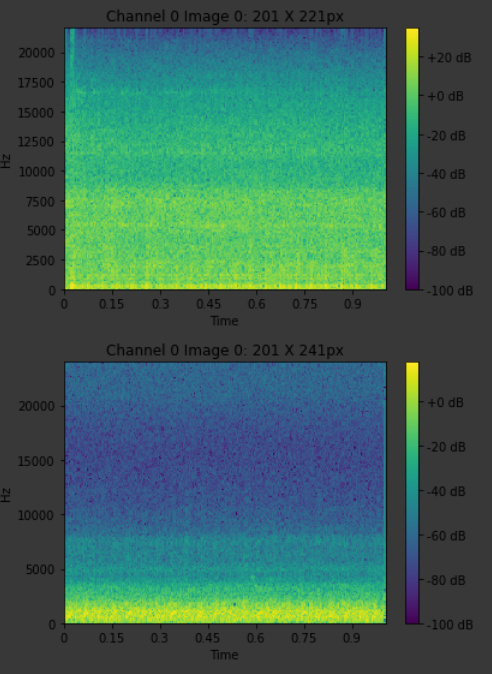
Here is the output and for some reason, it plots the graphs twice
Update: There are double graphs because some .wav files are composed of 2 signals and AudioTensor reads them separately. An easy fix is to average the tensor across dim=0 and pass that method to pipeline
Here is the output with CropSignal and repeat padding
But CropSignal(X) creates the signal and then pads with zero until X millisecs, right?
Am I completely missing something? Apologies in advance as I’m super new to the audio deep learning.
Update: After reading the source code for AudioTensor and CropSignal I found out that the shapes of my spectograms are different because each file has a different sampling rate. CropSignal is doing it’s job perfectly.
Update2: torchaudio.load does not allow us to change the sampling rate or at least it’s not one of the parameters in the load method. My hack for that is as below (I’ll try to write a multi-threaded version for this later)
%%shell
#!/bin/bash
mkdir temp
TMPDIR=temp
for fn in $(find . -name "*.wav"); do
TMPFILE=$TMPDIR/$(basename $fn)
sox $fn $TMPFILE rate 16000
mv $TMPFILE $fn
done
I’m sorry for the delayed response Pranjal, I haven’t been working on fastai audio the past 2 weeks as I have been focusing my efforts on covid19 tracking/risk assessment tools.
-Nice work with mergeSignal, we have a similar built in transform, DownmixToMono that will take n channels and avg down to 1.
-CropSignal indeed does crop pad to the desired length
-Your issue is most likely due to varying sample rates in your datasets, try using Resample in your pipeline before CropSignal
About the last part, we have on our todo list a plan to warn users about multiple sample rates as this is a tricky problem to detect in current version, sorry we didn’t get it out sooner and please let me know if that was indeed the issue.
That was precisely the issue and I wish I had read about DownmixToMono and Resample. Although, I did read Resample in the augment file but got confused by the name and I thought it was about re-sampling tensors in a loaded batch, should have read the code.
I already mentioned the bash script I used but to make things more python-ish, I wrote the below method as a part of my pipeline. Adding below in case some needs the same
def convert_file(infile: Path, bitrate: int = 16000) -> None:
"""Convert one file to the bitrate provided in the arguments.
This file does not return anything but raises exception if sox file fails.
:param infile: Input file path to convert.
:param bitrate: The desired bitrate.
:raises: OSError, SubprocessError
"""
infile = Path(infile)
tempfile = infile.parent / '.temp.wav'
# Call sox to convert the file.
subprocess.run(['sox', str(infile), str(tempfile), 'rate', str(bitrate)],
check=True, stdout=subprocess.PIPE, stdin=subprocess.PIPE)
# Remove the tempfile and replace the infile with the modified bitrate.
subprocess.run(['mv', str(tempfile), str(infile)],
check=True, stdout=subprocess.PIPE, stdin=subprocess.PIPE)
def convert_all(input_dir: str, bitrate: int = 16000) -> None:
"""Converts all .wav files directly inside the folder to the desired bitrate.
:param input_dir: Input directory with wav files to convert.
:param bitrate: The desired bitrate.
"""
for infile in Path(input_dir).glob('**/*.wav'):
convert_file(infile, bitrate)
I’m happy to hear that you were busy helping mitigate the covid19 problem . I’ll finish few things on my end and then jump-in to contribute to this library in my capacity. I must tell you that I only started working with audio data 4 days ago and found out about this library. So I’m limited in my ability to understand the details of signal processing methods.
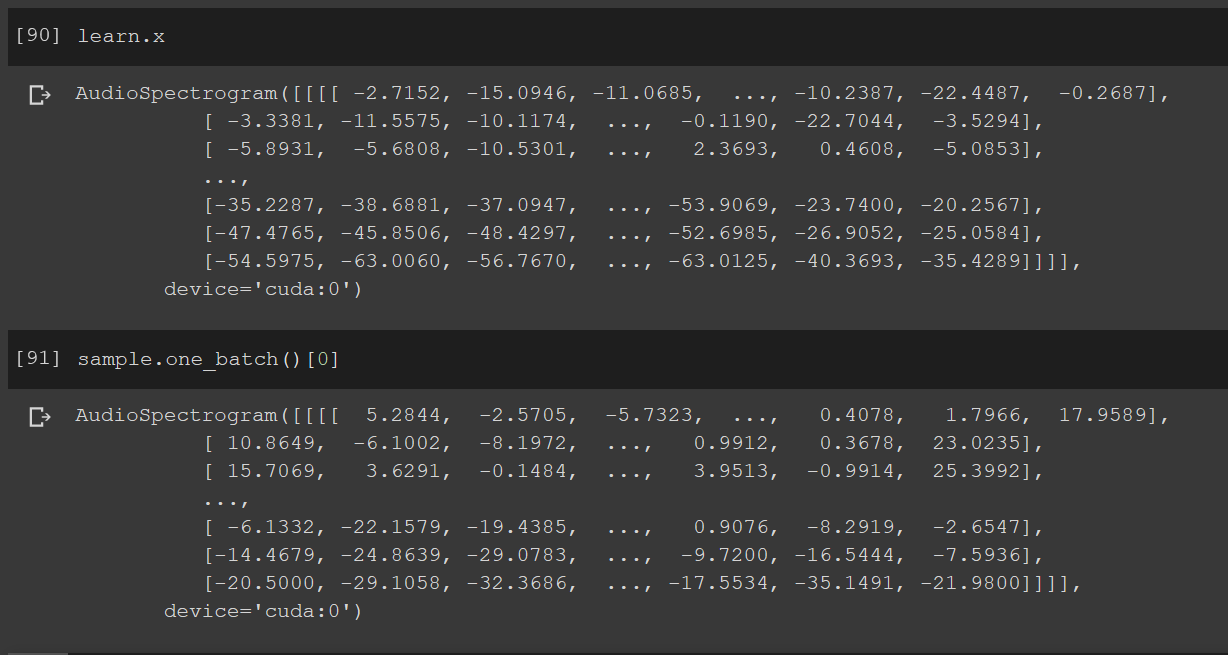
 I’ll look into it tonight (as it seems like a fastai issue on a whole)
I’ll look into it tonight (as it seems like a fastai issue on a whole)