I’ve developed some extensions to the fastai2 library that I find useful for a variety of purposes. This is now pip installable via pip install fastai2_extensions.
Repo: https://github.com/Synopsis/fastai2_extensions
There’s 3 main components to the library:
1. Interpretation
1.1 Label Confidence & Label Accuracy Plots
I’ve extended ClassificationInterpretation to gain some more insights regarding the model. For example:
learn = cnn_learner(...)
learn.fit(...)
interp = ClassificationInterpretationEx.from_learner(learn)
interp.plot_accuracy()
interp.plot_label_confidence()
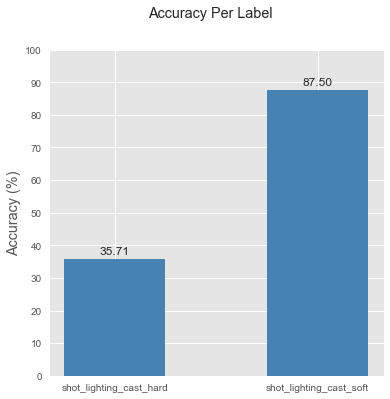
This doesn’t show any new information compared to the confusion matrix, but seeing the size of the bars helps me understand better which categories my model’s failing at.
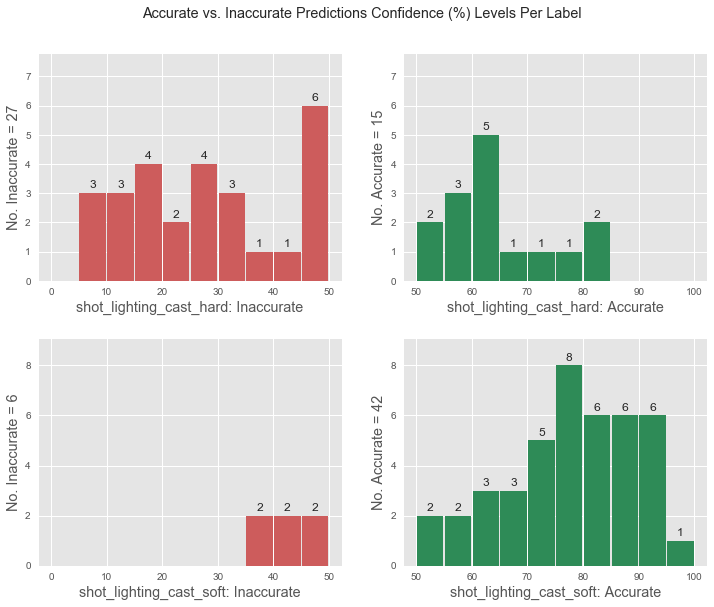
It’s interesting to see with how much confidence your model classifies each category. While there is some literature suggesting that models are sometimes (negatively) overconfident, I think there’s merit in a model that has low accuracy for a label, but classifies everything it gets right with >90% accuracy. This is especially helpful if you have noisy data, and are training a model to get a feel for the dataset. A model that’s confident, but not accurate, shows that there’s some clear
As of now, these have only been tested with Softmax classifiers and will probably break when trying on Multi-label Sigmoid models. However, extending it shouldn’t be too hard.
1.2 Exploring Multiple Models’ Agreement (With Confidence Levels)
This builds on 1.1 and is made for scenarios where you’ve trained more than 1 model on a dataset and would like to explore how much the models agree with each other. The function compare_venn outputs venn diagrams for model agreement if you input 2-3 models, but you can also input 10 (or 100) models and get the filenames of all files that are common to these models.
interp1 = ClassificationInterpretationEx.from_learner(learn1)
interp2 = ClassificationInterpretationEx.from_learner(learn2)
interp1.compute_label_confidence()
interp2.compute_label_confidence()
fig,common_labels = compare_venn(
conf_level=(80,100), interps=[interp1,interp2], #interp:ClassificationInterpretationEx
mode='accurate', # or 'inaccurate' for misclassified images
return_common=True, return_fig=True, # return list of filenames
# that both models agree on
)
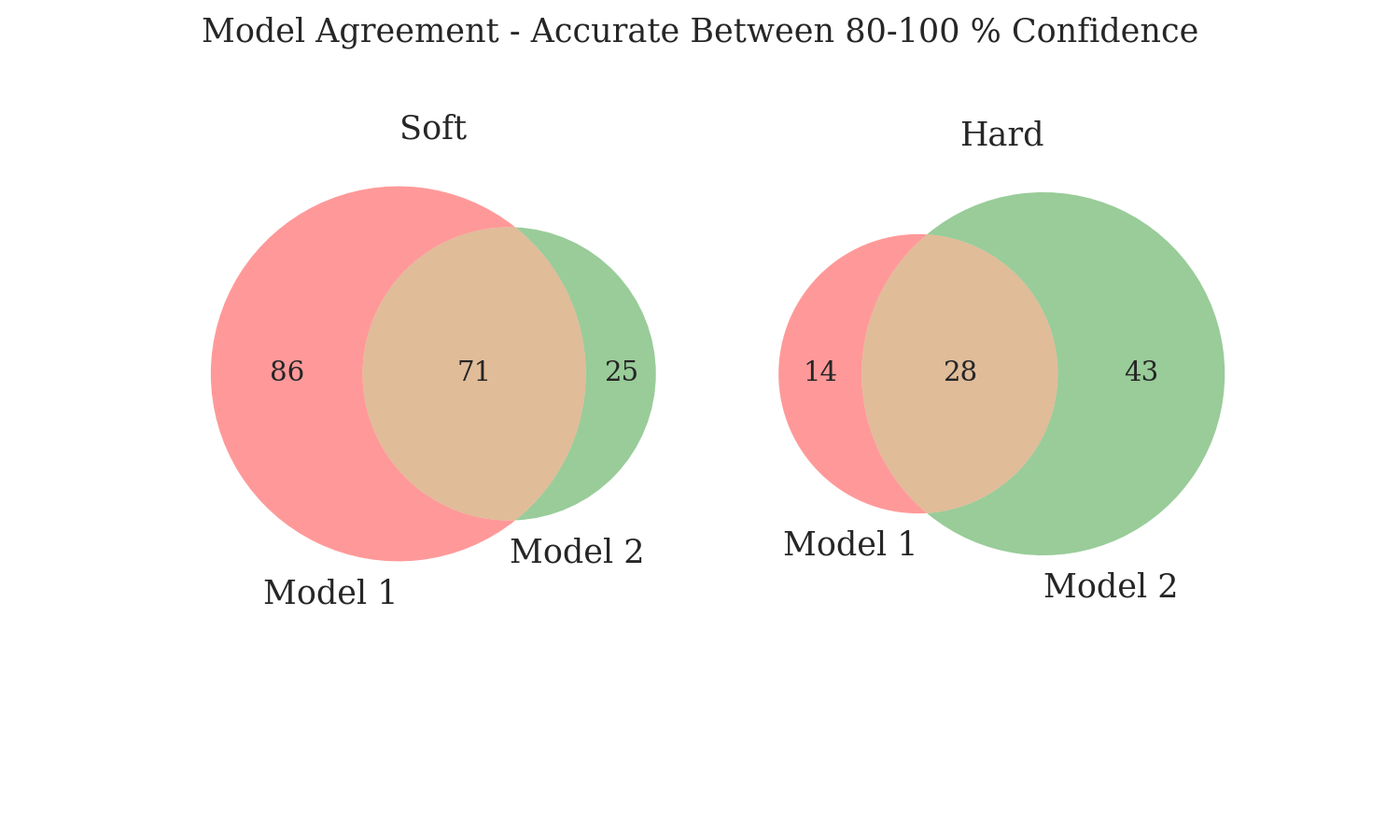
This can also come in handy in cleaning noisy datasets, and exploring whether or not there’s a clear signal in your
1.3 GradCAM
Nothing new here, but all the functionality wrapped into a convenient class, and some plotting utilities to better visualise these heatmaps. Code was mostly borrowed from fastbook.
For example:
gcam = GradCam(learn=learn, fname=path_to_img, labels=None) #plots highest prediction
gcam.plot(full_size=True, plot_original=True, figsize=(12,6))

You can also pass in a list of labels, and max_ncols to the GradCam,plot function to keep things neat and visualise heatmaps for all your classes. More info on the docs.
2. Inference – Exporting Models
As discussed on many other forum posts (links to be added), I’ve collated code snippets from all over to build some wrappers to export models to other frameworks.
The ONNX wrapper is most stable, and the CoreML and TF wrappers are a bit fiddly. It takes care of ensuring that the ONNX model can be used for batch processing (not on by default), lets you easily add an acctivation function, removes fluff, adds input and output names which make for a neat visualisation in an app like Netron.
Here’s the function signature:
torch_to_onnx(learn.model,
activation = nn.Softmax(-1),
save_path = Path.home()/'Desktop',
model_fname = 'onnx-model',
input_shape = (1,3,224,224),
input_name = 'input_image',
output_names = 'output')
3. Data Augmentation
I’ve implemented the ability to use PIL.ImageFilters as a data augmentation in the standard fastai pipeline. AFAIK, these are lossless transformations, thus a great choice. I haven’t yet tested to see how this makes an impact on model performance, but untuitively, I don’t see why it wouldn’t.
The library also has some convenience functions to read in a LUT file (commonly found with .cube extensions). LUTs are widely used in the post-processing world in both videos and images in color processing pipelines.
Here’s what a PIL.ImageFilter.Color3DLUT transformation looks like:

Code Example:
dblock = DataBlock(
blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
#####################################################################
get_x = Pipeline([PILImage.create, ApplyPILFilter(filters, p=1.)]),
#####################################################################
get_y = parent_label,
splitter = RandomSplitter(seed=42, valid_pct=0.),
item_tfms = [Resize(size=224, method=ResizeMethod.Squish, pad_mode=PadMode.Zeros)],
batch_tfms = [Normalize.from_stats(*imagenet_stats)]
)
where filters can be just one or a list of filters. If it is a list, then a random one if selected and applied when the image is read from disk.
I’ve added sources in the docs, and will do the same in this post as well (finding them takes a while).
I’d love to get some feedback and would be thrilled if we can grow this into a community project 