can anyone help me out resolving this issue…?
The above code is refrenced from https://medium.com/@alden_6876/getting-document-encodings-from-fastais-ulmfit-language-model-a3f9271f9ecd . i made small changes to it and ran the above function but it takes too much time to run this . is there any other alternative to get the encodings from the encoder
Dear Anish_sri,
unfortunately, I cannot really provide any help to your question here, because I do not understand the set-up you are currently running. Could you provide a bit more information about the functions you are calling in order to process the input?
You quote the link
I am trying to get it to work with fast.ai V2, but I am currently stuck.
I am not certain which updates you made in order to get it running with fast.ai V2. Could you post these here?
My current set up is the following:
learn = language_model_learner(
dls_lm, AWD_LSTM, drop_mult=0.3,
metrics=[accuracy, Perplexity()]).to_fp16()
learn = learn.load('learn_finetuned')
inp_x = 'this is a test'
tkn = dls_lm.tokenizer
tkn(inp_x)
num = Numericalize(vocab = dls_lm.vocab)
nums = num(inp_x); nums
def sentence_encoding(encoder, sentence):
awd_lstm = encoder.model[0]
awd_lstm.reset()
with torch.no_grad():
out = awd_lstm.eval()(sentence)
return out[0][0].max(0).values.detach().numpy
encoded_sentence = sentence_encoding(learn, nums)
However, when I run these inputs, I get the following error message:
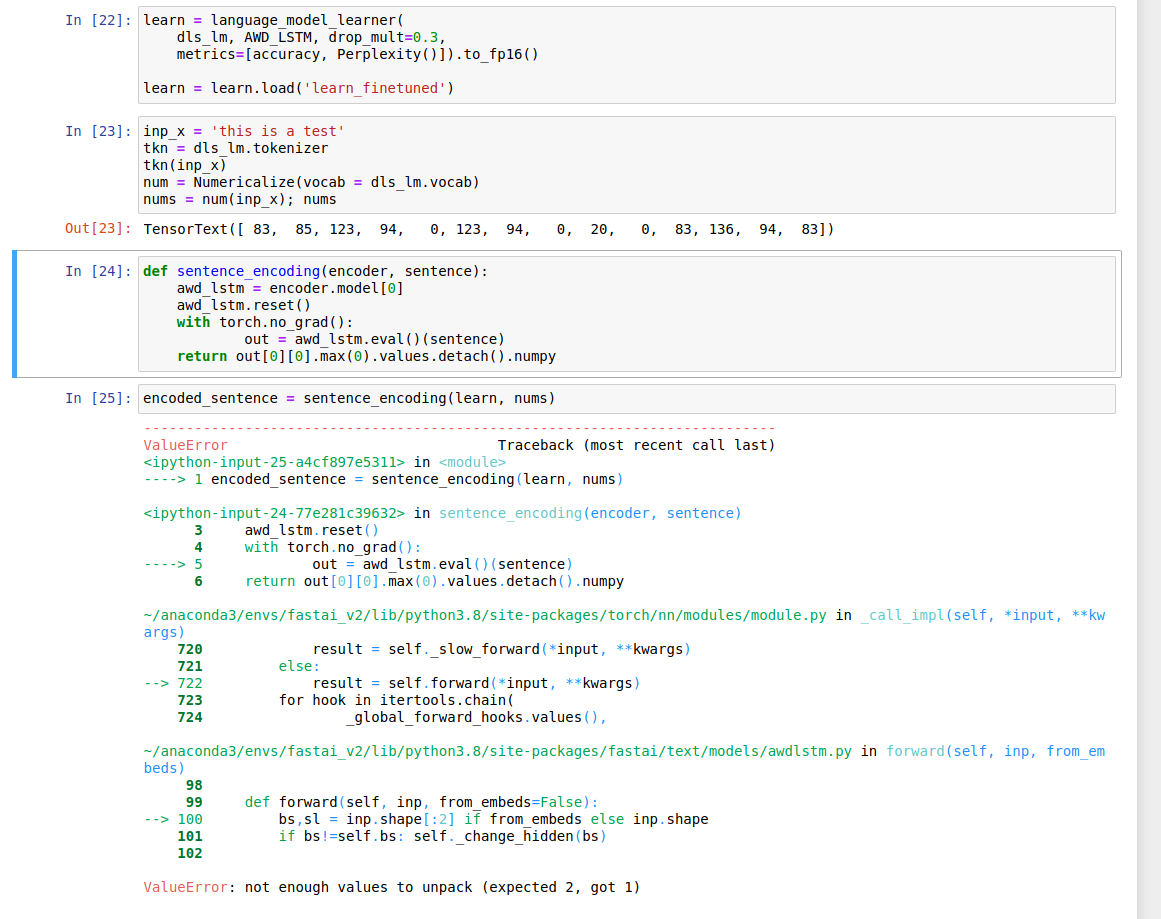
Maybe we can work on this together? As I am currently stuck at an earlier part I cannot really contribute to your problem right now, sorry. But once I get to the same level as you I think we can go from there. (My current line of thinking is to put the model on the cpu and then parallelize getting the embeddings, but I cannot test that yet, due to the error.)
Any input will be highly appreciated.
hey @stumpen I think i also faced the same issue whilw testing for a document, but what i found is the input for the model . the model is accepting a certain format . the input format should be in form of
TensorText([[83,85,87,…]]) . try the nums output to detach first and try to convert the nums output into desired format which i have mentioned.
Hello, @Anish_sri @stumpen . Not sure if it’s still actual for you, but I made a notebook demonstrating batch generation of sentence encodings. One can run it on colab and check results.
Here is some code I used for generation:
def get_sentence_encodings(learn, dl=None, method='max'):
if dl is None:
dl = learn.dls.valid
learn.model.to(dl.device)
learn.model.eval()
sentence_encoder = learn.model[0]
bptt = getattr(sentence_encoder, 'bptt')
encodings = []
y = []
pool = _pooler[method]
pbar = progress_bar(dl)
for b in pbar:
xb = b[0]
with torch.no_grad():
enc, mask = sentence_encoder(xb)
encodings.append(pool(enc, mask, bptt))
if len(b)==2: y.append(b[1])
if y:
return torch.cat(encodings), torch.cat(y)
else:
return torch.cat(encodings), None
and some helper code:
def masked_max_pool(output, mask, bptt):
return output.masked_fill(mask[:,:,None], -float('inf')).max(dim=1)[0]
def last_hdn_pool(output, mask, bptt):
last_lens = mask[:,-bptt:].long().sum(dim=1)
return output[torch.arange(0, output.size(0)),-last_lens-1]
def masked_avg_pool(output, mask, bptt):
lens = output.shape[1] - mask.long().sum(dim=1)
avg_pool = output.masked_fill(mask[:, :, None], 0).sum(dim=1)
avg_pool.div_(lens.type(avg_pool.dtype)[:,None])
return avg_pool
_pooler = {
'concat': masked_concat_pool,
'max': masked_max_pool,
'last': last_hdn_pool,
'avg': masked_avg_pool,
}
Also it seems to be a recurring question about sentence encodings. How do you use those? Do these encodings come up useful? I guess, it would be interested to compare encodings from AWD_LSTM and from some transformer based models.
I’m interested in any feedback on approach I used and further discussion of the topic
@arampacha Hello arampacho , Thanks for helping me in getting the sentence encodings for a text sample but with your proposed approach also it is taking time for 15k records is around 26 mins with each sample having a sequence length of 40 . But previously it was around 2.5 hrs for 15k records.
Is there any faster process for getting the encodings faster . As we are using these encodings as a input to a neural network where some other classification task is being carried out .
Hi, @Anish_sri, are you using GPU? Try optimizing batch size, the large batchsize, the faster it should work. In my example it took ~1min for 50k sentences with mean length around 10 tokens, so you also should be able to go faster. Also, do you need those those encodings computed separately? Cause if you use SentenceEncoder as part of your model, like it’s done in standard fastai text classifier, it should be faster in total
@arampacha Okay i will try to implement by taking more batch size and i needed those encodings seperately because i cannot integrate sentence encoder directly to keras functional api so for that reason i am computing seperately. Thanks for the help
Dear @arampacha,
Thank you very much for sharing your insights: Unfortunately, they did not seem to work for me. I probably have missed something, but this is the error message I got:
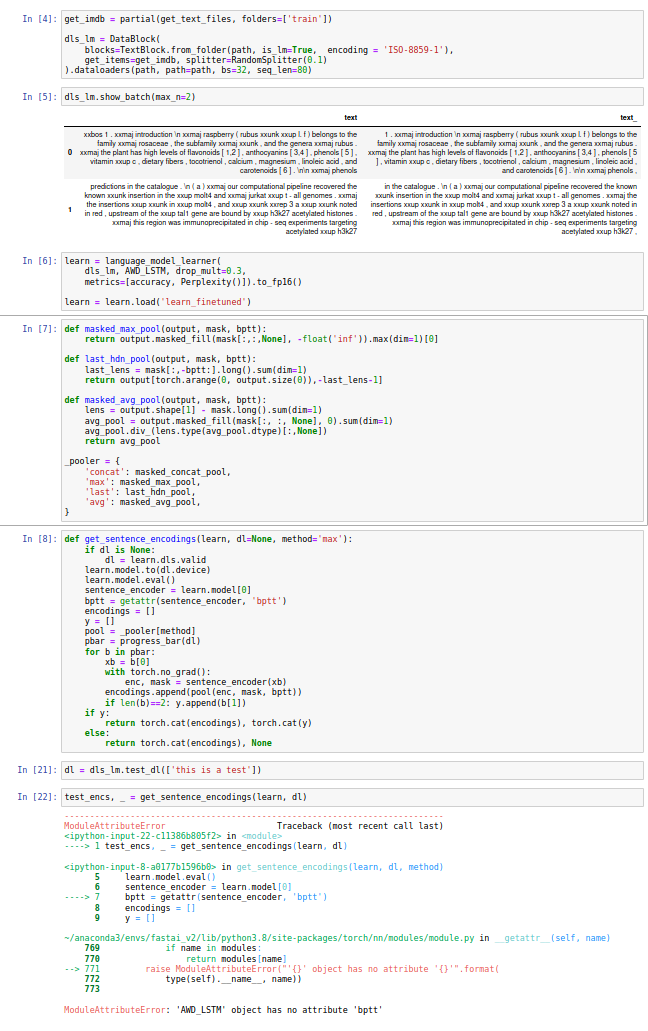
One thing I noticed is that your encoder seems to operate after building the classifier model. For the application (big word here, more like a tinkering side project) I have in mind, there is no classification step.
Ultimately, I would like to do the following: I have a text corpus with multiple sentences in it. I want to get the encodings of every sentence and then compare them to a “test sentence” to check their similarity. I have seen that Idea float around in several places, but was never able to implement it, because I could not get the encodings…
Hello @stumpen! Sorry for the delayed response. The error is caused by the fact that bptt attribute is added by SentenceEncoder class which is used by text classifier but not by language model. Quick workaround here would be to save your encoder after language modeling step and load it to dummy text classifier learner, which you can use to get sentence encodings.
This should work but is not an elegant solution. I will see how can I modify the notebook to work with language model learner.
Note that training with language modeling objective might not result in very good sentence embedding as is. Take a look at SBERT which is specifically pretrained for sentence representation.
1 Like