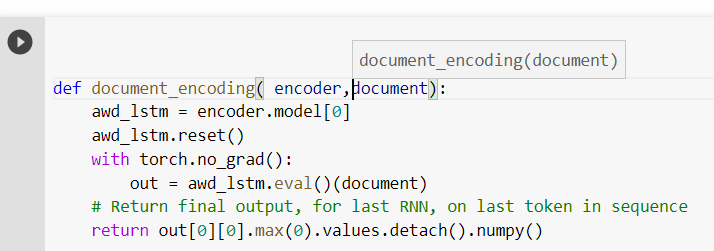
Hello everyone, I want to get encodings of a text description with pretrained ulm fit encoder. the above picture get’s the output of encodings but it takes too much time like around(3min ) for 500 records and the average sequence length of all the descriptions is around 30 . I have around 2,57,000 records. is there any faster process to do it…? I am giving input as Tensor text to the function…?
A sample input to the function looks like in this format.