@mgloria@jeremy If you want a discussion, I’d raise an issue in the Google TPU repository https://github.com/tensorflow/tpu instead of Luke’s… that’s where the EfficientNet reference impl that Luke, myself, and others adhered to for our EfficientNet impl. I doubt anyone tried to muddle through that scaling impl from the paper. Someone often responds to issues there, incl questions about papers for the models within a few days to a week.
All that being said, it does seem to roughly make sense if you throw in some generous rounding to .1 decimal place on width/depth factor and round (or floor/ceil?) res to nearest res % 16 == 0 … as the models get larger it seems to diverge a bit with some likely hand nudging…
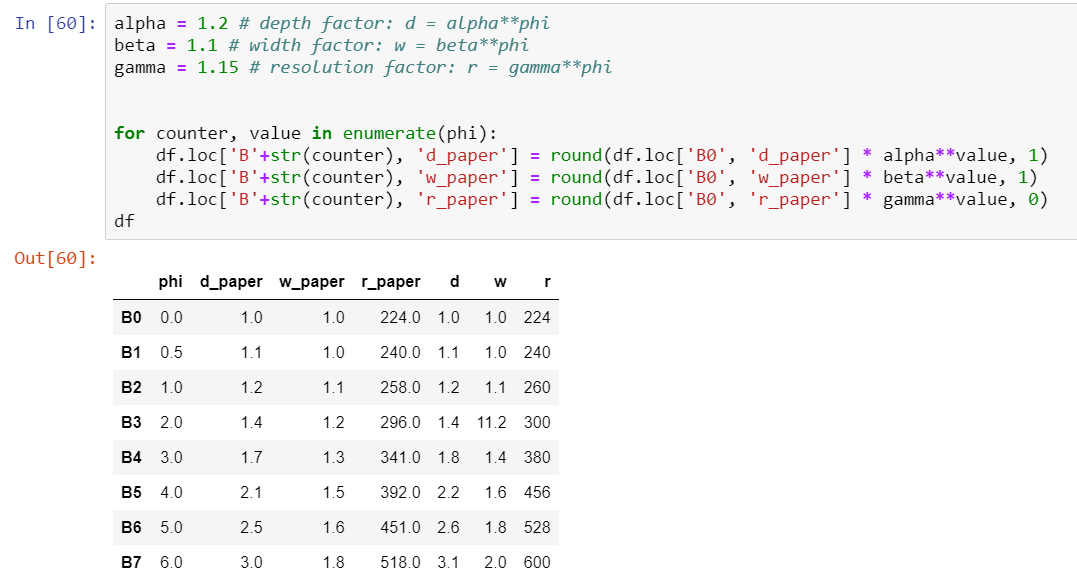
Working through a few, the compound scaling factor (phi) for B1 is approx .5, B2=1, B3=2, etc.
1.0 (B0 depth) * 1.2^2 = 1.44
1.0 (B0 width) * 1.1^2 = 1.21,
224 (B0 res) * 1.15^2 = 296
thanks a lot @rwightman for your reply. It was my first time trying going through paper and code so I find it very interesting to have this discussion.
What you say makes sense, I repeated all the calculations and these are the results:
I was surprised to see that in some cases, specially for the resolution, the difference is not just some minor rounding.
Tell me (a newbie), why the rounding constraint res % 16 == 0?
I added some info also regarding the computational cost which may also help others. If I understood the paper correctly:
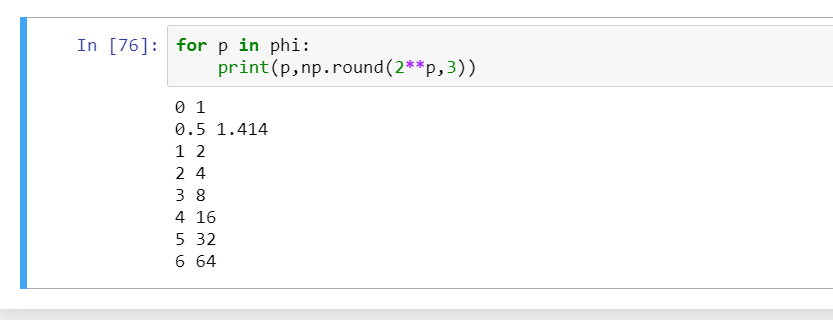
alpha * beta^2 * gamma^2 =~ 2 (equation 3).
So any new phi, will increase the original number of FLOPS by 2**phi.
As most computer hardware is built from bits, organized into 8-bit bytes, organized into WORDS (int16), DWORDS (int32), etc, you’ll often encounter constraints related to various power of 2 numbers. Sometimes it’s just fetishism of sorts, developers learn to like the binary roundness of such numbers. In many cases there are real performance reasons, especially when you start talking about parallization, loop unrolling, buffer alignment, optimal mapping to hardware resources (often existing in multiples of such numbers). The non power of 2 remainder would often have to be handled with another pass, or a special block of code that will take more time or underutilize the hardware.
In this case there are heavily optimized (faster, less memory) variations of convolution operations that work if your tensors adhere to certain constraints, some dimensions like batch, width, height being divisible by 8 (or possibly higher pow2 numbers is often a criteria).
Another week and another set of EfficientNet weights released (AdvProp) with a B8 model specification… Google team has been busy!
The new weights were trained with an adversarial training technique, using adversarial examples as training data augmentation (https://arxiv.org/abs/1911.09665). It’s pretty neat, they leverage separate BN layers for normal and adversarial examples, to prevent adversarial examples messing up the BN and reducing the model performance on normal examples. Something I’ve encountered when fiddlign with adversarial training in the past… or pushing other data aug techniques too far.
Just discovered your geffnet library I’d love to experiment with your EfficientNet implementations in fast.ai (v2).
Is this possible yet? Too early for jumping into v2 with external stuff?
Would you have a notebook somewhere where I can get a grasp of how things work?
@cwerner I can’t speak for him but I’ve been playing with v2 since the dev first started and you certainly can my repo has a ton of tutorial notebooks on how to do various tasks. This one shows custom models (along with optimizers and activation functions)
It’s 2020…
in case someone is looking to use efficient nets straight out of the box with FastAI V2
here it is Plant Pathology Kaggle
It’s nice to see fast ai whup some of the TPU based scores too… [granted GPU based training take much more time]
I am sure there can be improvements to this…
among other things, the oversamplingCallback wasn’t particularly effective…
Does anyone know how much epoch of efficientnet(b0) training you need to rush top5 90%, 91%, 92%, and 93% on imagenet?
In TF code they train for 350 epochs. I can reach 90% in 50 epochs but do I really need 350epochs to reach 93% ?
Well, I think the bottleneck here are the inverted residual blocks. I don’t know for sure, but a few days back I trained a Tiny YOLOv2, only it had all the Conv2D’s replaced with depthwise and 1x1 convolutions. It had some 1M odd parameters, compared to the normal Tiny YOLOv2 which has over 4M parameters. But still it took roughly double the time to train.
Hi All,
I was wondering if it is possible to use EfficientNet like this
learn = cnn_learner(dls, efficientnet, metrics=accuracy) # resnet 34 or 18, also 50 works better
because I am having this.
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in
----> 1 learn = cnn_learner(dls, efficientnet, metrics=accuracy) # resnet 34 or 18, also 50 works better
TypeError: forward() got an unexpected keyword argument 'pretrained'
I follow exactly according to @muellerzr’s tutorial. It seems that the newest version of fastai has this issue. (The tutorial fastai version: 2.0.14, my version: 2.2.2)
PS: i looked through the model and there’s no pretrained parameters at anywhere too.
def create_timm_body(arch:str, pretrained=True, cut=None):
model = create_model(arch, pretrained=pretrained)
if cut is None:
ll = list(enumerate(model.children()))
cut = next(i for i,o in reversed(ll) if has_pool_type(o))
if isinstance(cut, int): return nn.Sequential(*list(model.children())[:cut])
elif callable(cut): return cut(model)
else: raise NamedError("cut must be either integer or function")
^ The function from wwf tutorial.
from timm import create_model
body = create_timm_body('efficientnet_b0', pretrained=True)
model = nn.Sequential(body, create_head(1280, 10))
apply_init(model[1], nn.init.kaiming_normal_)
learn = cnn_learner(data, model, metrics=[error_rate,accuracy,F1Score(average='micro'),Precision(average='micro'),Recall(average='micro')],cbs=[WandbCallback(log_dataset=True, log_model=True),SaveModelCallback()])


 my repo has a ton of tutorial notebooks on how to do various tasks. This one shows custom models (along with optimizers and activation functions)
my repo has a ton of tutorial notebooks on how to do various tasks. This one shows custom models (along with optimizers and activation functions)