Are Luke Melas parameters’ correct?
Regarding Luke Melas EfficientNets, I was comparing it with the paper and it seems to me that either I am missing something (apologies in advance) or the parameters he is using are not the same. This is his code which you will find in utils.py:
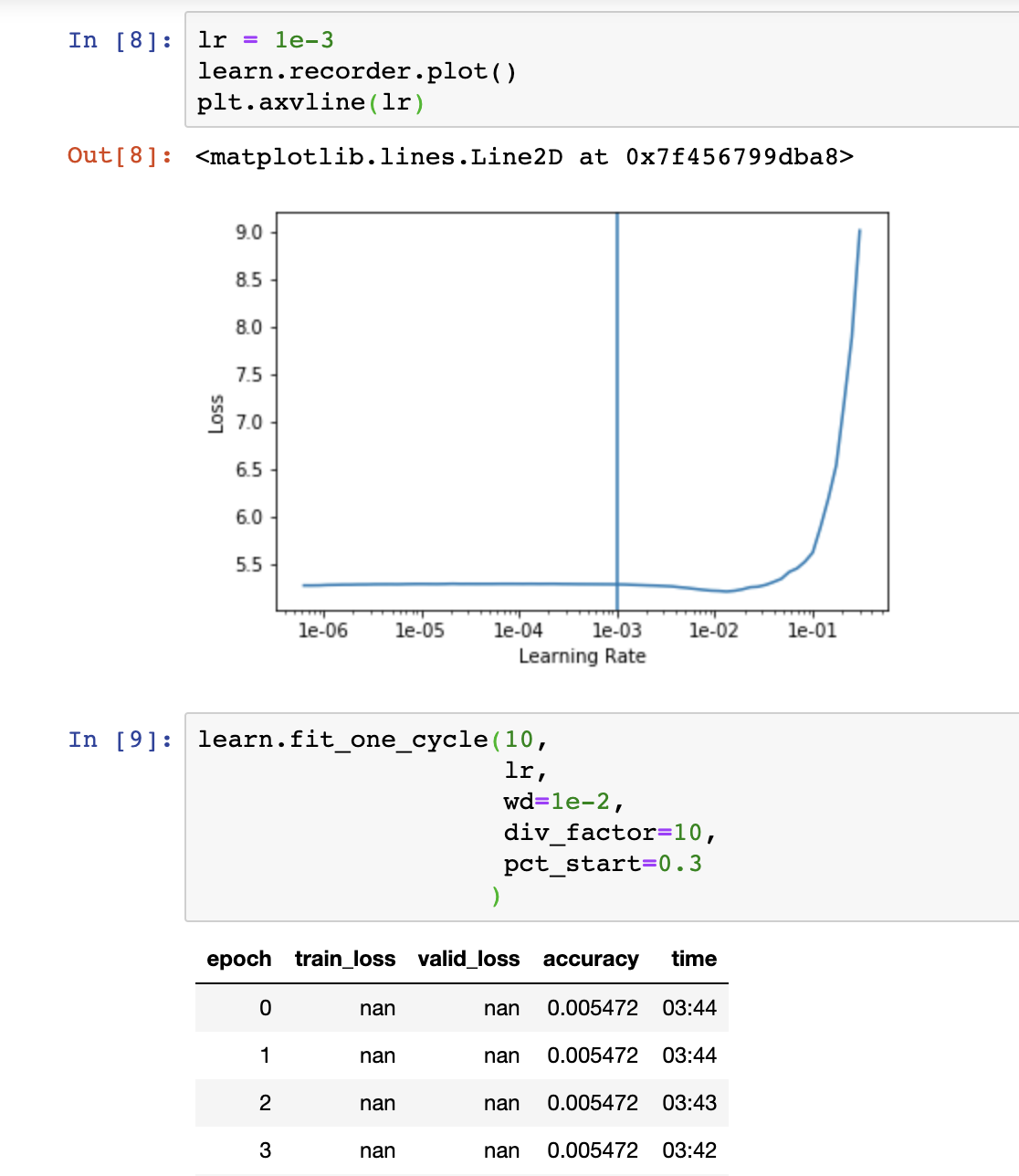
def efficientnet_params(model_name):
""" Map EfficientNet model name to parameter coefficients. """
params_dict = {
# Coefficients: width,depth,res,dropout
'efficientnet-b0': (1.0, 1.0, 224, 0.2),
'efficientnet-b1': (1.0, 1.1, 240, 0.2),
'efficientnet-b2': (1.1, 1.2, 260, 0.3),
'efficientnet-b3': (1.2, 1.4, 300, 0.3),
'efficientnet-b4': (1.4, 1.8, 380, 0.4),
'efficientnet-b5': (1.6, 2.2, 456, 0.4),
'efficientnet-b6': (1.8, 2.6, 528, 0.5),
'efficientnet-b7': (2.0, 3.1, 600, 0.5),
}
return params_dict[model_name]
Now, when I go to the original paper, the authors say the following:

the equation to which they refer is the one:
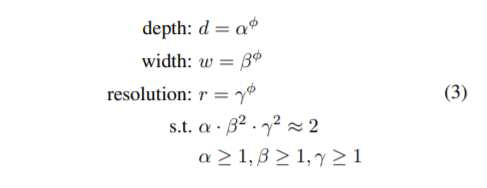
So basically if for instance alpha = 1.2 and depth = alpha ** phi, how do I get to Luke Melas table? I did not find a way to understand the numbers of his scaling. Did somebody review it?
There is one sentence of the paper that confuses me though
we first fix phi=1 (…). We find best values for efficientNetB0 are alpha = 1.2, beta = 1.1, gamma = 1.15."
If I interpret this sentence correctly, w=1.0 d=1.0 and r=224 would correspond to EfficientNetB0 and these new parameters are for phi = 1, hence EfficientNetB1… again, different in Lukas table.