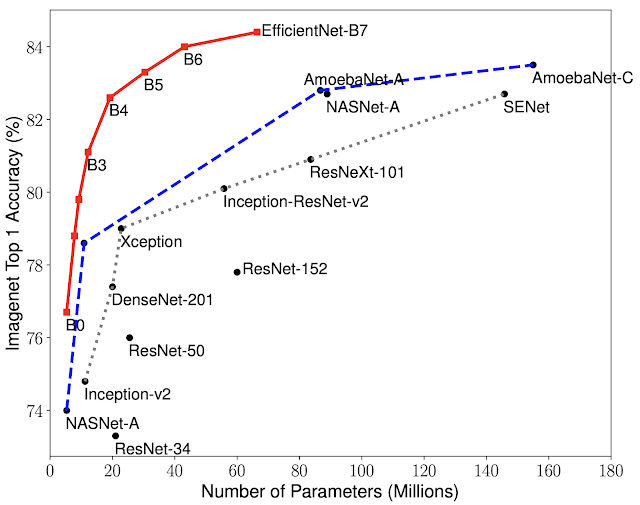
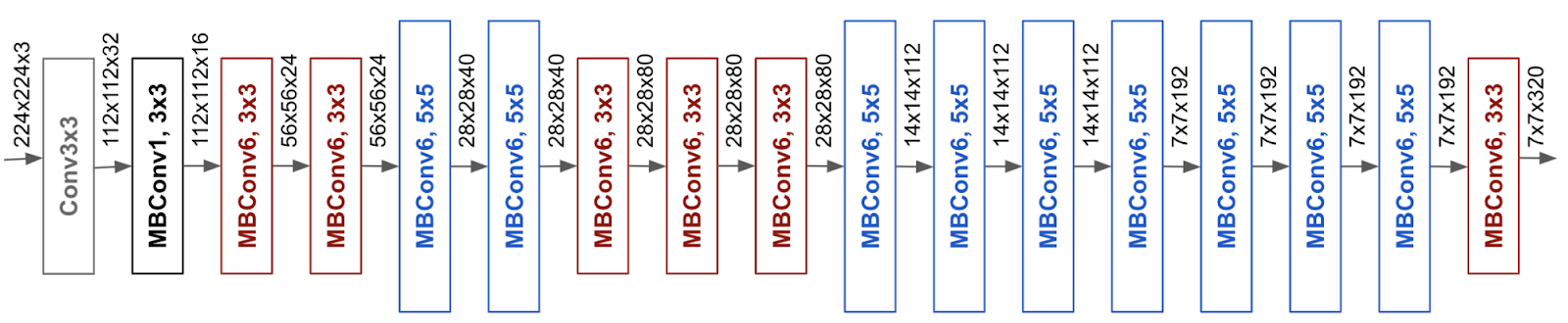
This new paper from Google seems really interesting in terms of performance vs # of parameters for CNNs. They achieve that by basically balancing the width, depth and size of the input image of the CNN while scaling it.
The performance difference seems so big that this would seem something interesting to integrate in fastai eventually.
Jeremy focus a lot on super-convergence in his courses (with good reason) and this seems totally inline with this philosophy of faster training, better performance.
And one more by IBM research https://arxiv.org/pdf/1905.09788.pdf which uses Multi-Sample Dropout for better and faster generalization with no increase in computation.
Of course it’s in TensorFlow but looks like it’s very possible to readily move it over to PyTorch and put into something similar to how the XResNet model is built (templatized).
I’d really like to get this up and running so we can test it out vs XResNet/ResNet on ImageNette.
Thanks for the link. I started coding it - they do add a width parameter to widen it as it goes deeper.
I’m pretty excited to try and get this up and running, ideally within the FastAI framework.
Yes, exactly what I want to leverage (XResNet). There’s a couple things in the TF code I don’t understand so I’m tracking those down but otherwise I think we can get this running soon.
Let me know if you review in more detail as the more input/help the better imo
I posted a short article on the paper on Medium to try and provide a summary of their findings (super summary = scale your architecture in 3d - depth and width and resolution, only going one dimension quickly saturates out).
Thanks for the links!
I’ve just been doing a line by line translation into PyTorch. Most of it is just changing params and PyTorch calls, so it’s not really conceptually hard but a bit tedious.
My plan is to convert it directly, verify and then try and try and match it to like how XResNet was done.
Start with x: (N,C,H,W)
Do average pooling, 1 value per channel: (N,C) or (N,C,1)
Squeeze with a conv 1*1: (N,C’) (with bias it seems)
ReLU
Unsqueeze: (N,C)
Sigmoid
Then multiply result by original x (broadcasting 1 value per channel)
def se_block(in_block, ch, ratio=16):
x = GlobalAveragePooling2D()(in_block)
x = Dense(ch//ratio, activation=‘relu’)(x)
x = Dense(ch, activation=‘sigmoid’)(x)
return multiply()([in_block, x])
and the TF code from the ExciteNet:
def _call_se(self, input_tensor):
“”“Call Squeeze and Excitation layer.
Args:
input_tensor: Tensor, a single input tensor for Squeeze/Excitation layer.
Returns:
A output tensor, which should have the same shape as input.
“””
se_tensor = tf.reduce_mean(input_tensor, self._spatial_dims, keepdims=True)
se_tensor = self._se_expand(act_fn(self._se_reduce(se_tensor))) #tf.logging.info(‘Built Squeeze and Excitation with tensor shape: %s’ %
# (se_tensor.shape))
return F.sigmoid(se_tensor) * input_tensor
I’m going to try and extricate the EfficientNet out so we have a pure ENet codebase but looks like he’s already solved the TF issues that I wasn’t sure of how to translate inito PyTorch…so this makes it 10x easier now.
@Seb , here’s his implementation on the SqueezeExcite portion for reference:
class SqueezeExcite(nn.Module):
def __init__(self, in_chs, reduce_chs=None, act_fn=F.relu, gate_fn=torch.sigmoid):
super(SqueezeExcite, self).__init__()
self.act_fn = act_fn
self.gate_fn = gate_fn
reduced_chs = reduce_chs or in_chs
self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
def forward(self, x):
# NOTE adaptiveavgpool can be used here, but seems to cause issues with NVIDIA AMP performance
x_se = x.view(x.size(0), x.size(1), -1).mean(-1).view(x.size(0), x.size(1), 1, 1)
x_se = self.conv_reduce(x_se)
x_se = self.act_fn(x_se)
x_se = self.conv_expand(x_se)
x = self.gate_fn(x_se) * x
return x