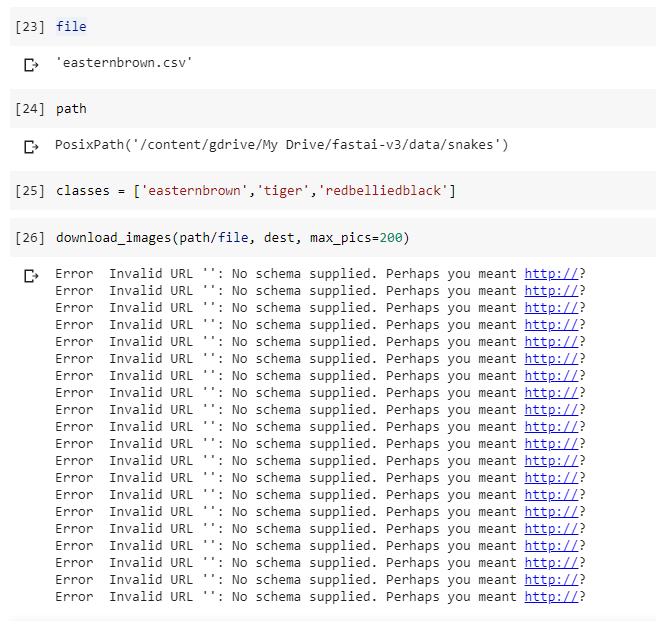
I waited and checked the folder and the images downloaded. I’m not clear why the error appears. An academic pursuit for when I’m a bit more experienced!
I want to point out that you usually can’t use images downloaded from Google Images because the copyright holder needs to give consent.
It’s probably fine if you’re just doing this for a personal study project, but you need to be careful about publishing a model that you trained on images that you do not have copyrights to, or are not given consent to use. (This is why large datasets such as ImageNet use only images from Flickr that have a Creative Commons license, and even that is not entirely uncontroversial.)
Note: I am not a lawyer. And I don’t think there is any legal consensus (yet) that a model trained on copyrighted images is a derivative work and therefore infringes on the copyright. But it’s smarter (and nicer) to only use images you have permission to use.
It 's because you have some some lines with empty strings in your CSV file. It only shows the error for these urls, it doesn’t prevent downloading images with valid url. I fixed this issue by filtering empty string urls in a given file with this PR to the fastai repo.
Created this Google Colab for downloading from Google Images easily. Create your csv with links and drag drop to folder panel in the left and then run.