Hi Everyone,
Here I show you the screenshots what i have done
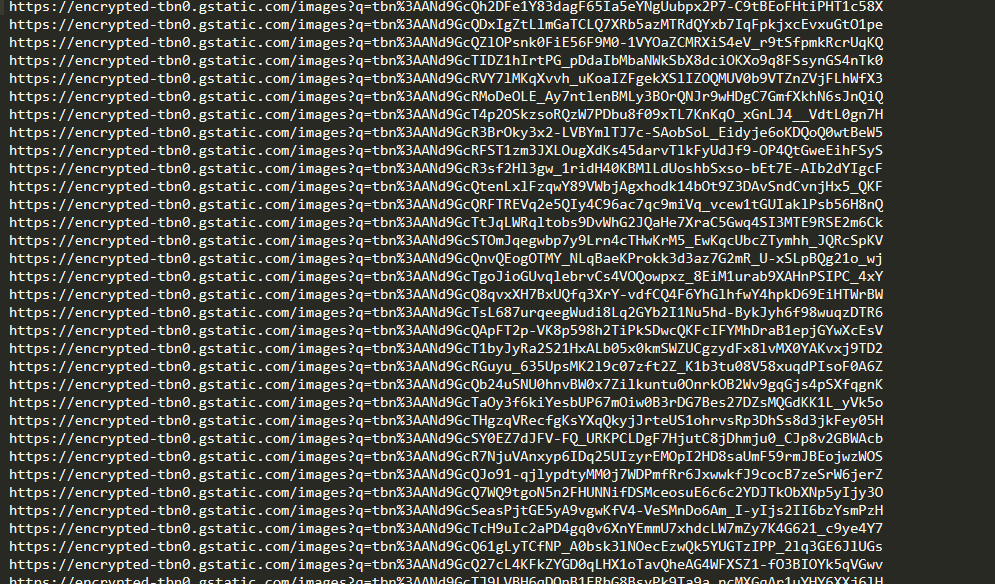
The problem is what i got https://encrypted-tbn0.gstatic.com/images?q=tbn%3AANd9GcQCSqUKhuFf0jtfMzQhSwUKdHfggYEa8wl3oI3t7aaUp3Qp6I1E
from the downloaded csv file
All links should be like this https://encrypted-tbn0.gstatic.com/**
So here i got encrypted links whenever i go to google looking for images
Please try to help me if as soon as possible