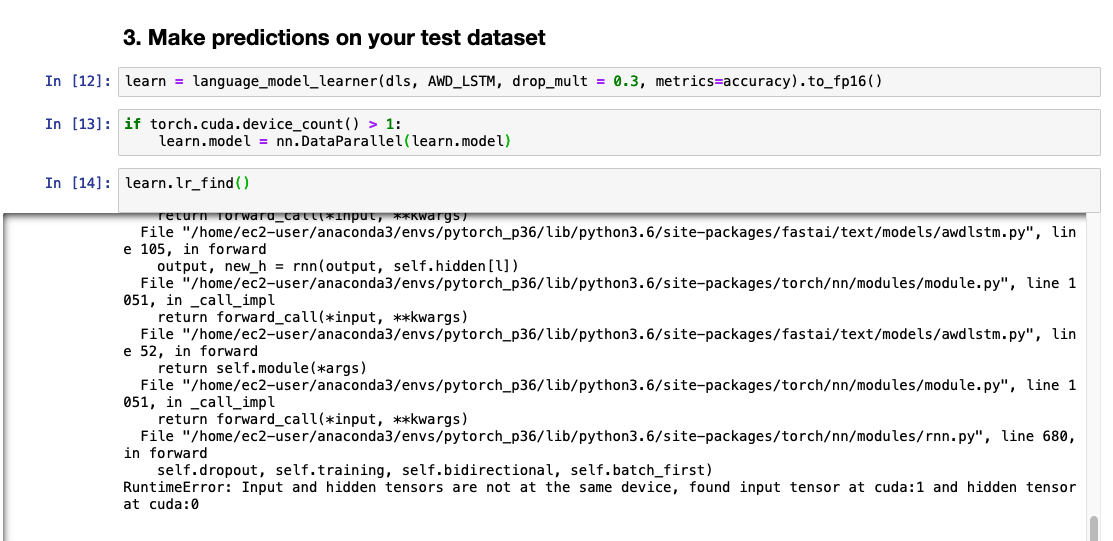
I still have problems with nn.DataParallel(learn.model).
RuntimeError: Input and hidden tensors are not at the same device, found input tensor at cuda:1 and hidden tensor at cuda:0
Which doesn’t make sense because I am trying to run it across 8 GPUs.
I have come to two possibilities.
- My data loader is mismatching with the learner and I need to fix devices. pierreguillou’s example don’t seem to work for me.
- Its just impossible right now. Fastai v2 text - #431 by chess