I have just updated the fast.ai library and found a bug when representing learner with data from single_from_classes .
It works perfect but just error in representation (maybe there is a bug in __ repr __ ?)
FYI, we now have a solution for those who don’t want all the fastai dependencies. It’s documented here.
2 Likes
In V1>basic_data->DataBunch()>def create(…
there is:
line 93 val_bs = (bs*3)//2
Is this intentional?
My 4GB GPU often went OOM after finishing training loop of an epoch at start of validation. I found this line was the culprit. In my local repo I have made val_bs=bs to overcome this.
Curious why it is the way it is
I have found this too, crashing at validation stage, which I hadn’t ever experienced with v0.7
Maybe it is because I am using fp16 quite often and perhaps validation may not (speculation).
You can see it discussed here Different batch_size for train and valid data loaders - #2 by sgugger
very interesting. I will leave it at val_bs=bs for the time being until I gather enough courage to bump it up in 10% increments.
Use https://github.com/stas00/ipyexperiments to speed up the bs tune up.
If you have any follow ups about this new tool, please use this thread to discuss it.
1 Like
@stas, Just tried it out ! You are a life-saver !!
1 Like
Heads up: we now have a tool to query gpu stats that fastai can support, it’s pynvml - and it’s now on both pypi and conda. So most likely it’ll soon be used by the fastai core modules (in particular tests) (and included in fastai dependencies). See the doc above for examples of use. It’s super fast!
1 Like
Unless I’m mistaken, there’s currently no method to label a bounding box with text. Would you be interested by something like this ?
There is, you just have to pass classes on top of your bounding boxes and labels.
Oh my bad then, sorry about that 
For some reason my update to the docs didn’t fully convert to HTML. You can see it here now.
I got an error in basic_train.py line 270 because it is not recognizing table=True,changing the code to remove this from the call, solves the problem.
Is it a bug?
Another potential bug:
When I create a DataBunch from a TensorDataset, as in lesson 5, and then try creating an ClassificationInterpretation, it breaks.
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_top_losses(9, figsize=(7,7))
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-33-f4ec02bb4041> in <module>()
1 interp = ClassificationInterpretation.from_learner(learn)
----> 2 interp.plot_top_losses(9, figsize=(7,7))
~/Code/fastai/fastai/vision/learner.py in plot_top_losses(self, k, largest, figsize)
96 "Show images in `top_losses` along with their prediction, actual, loss, and probability of predicted class."
97 tl_val,tl_idx = self.top_losses(k,largest)
---> 98 classes = self.data.classes
99 rows = math.ceil(math.sqrt(k))
100 fig,axes = plt.subplots(rows,rows,figsize=figsize)
~/Code/fastai/fastai/basic_data.py in __getattr__(self, k)
99 return cls(*dls, path=path, device=device, tfms=tfms, collate_fn=collate_fn)
100
--> 101 def __getattr__(self,k:int)->Any: return getattr(self.train_dl, k)
102 def dl(self, ds_type:DatasetType=DatasetType.Valid)->DeviceDataLoader:
103 "Returns appropriate `Dataset` for validation, training, or test (`ds_type`)."
~/Code/fastai/fastai/basic_data.py in __getattr__(self, k)
22
23 def __len__(self)->int: return len(self.dl)
---> 24 def __getattr__(self,k:str)->Any: return getattr(self.dl, k)
25
26 @property
~/Code/fastai/fastai/basic_data.py in DataLoader___getattr__(dl, k)
6 __all__ = ['DataBunch', 'DeviceDataLoader', 'DatasetType']
7
----> 8 def DataLoader___getattr__(dl, k:str)->Any: return getattr(dl.dataset, k)
9 DataLoader.__getattr__ = DataLoader___getattr__
10
AttributeError: 'TensorDataset' object has no attribute 'classes'That conversation has already been had on another topic, if you’re not using fastai to create your dataset, don’t expect all fastai functionalities to work on it. Here the problem is that your TensorDataset doesn’t have the classes attribute that ClassificationInterpretation requires.
After experimenting a bit, and going back and forth, we finally settled on adding a MAJ token: each word that begins with a capital is lower cased (as before) but we add xxmaj in front of it to tell the model. It appears to help a little bit.
There is a new pretrained model to match that change: you’ll find it in URLs.WT103_1
The text example notebook has been updated to use it (and went from 79% to 84.5% accuracy in the process!)
Sorry, I didn’t see the question in another topic before posting here.
A lot of stuff aimed at unifying the API accross applications just merged:
- every type of items now has a
reconstructmethod that does the opposite of.data: taking the tensor data and creating the object back. -
show_batchhas been internally modified to actually grab a batch then showing it. -
show_resultsnow works across applications. - introducing
data.export()that will save the internal information (classes, vocab in text, processors in tabular etc) need for inference in a file named ‘export.pkl’. You can then create anempty_dataobject by usingDataBunch.load_empty(path)(wherepathpoints to where this ‘export.pkl’ file is). This also works across applications.
Breaking change:
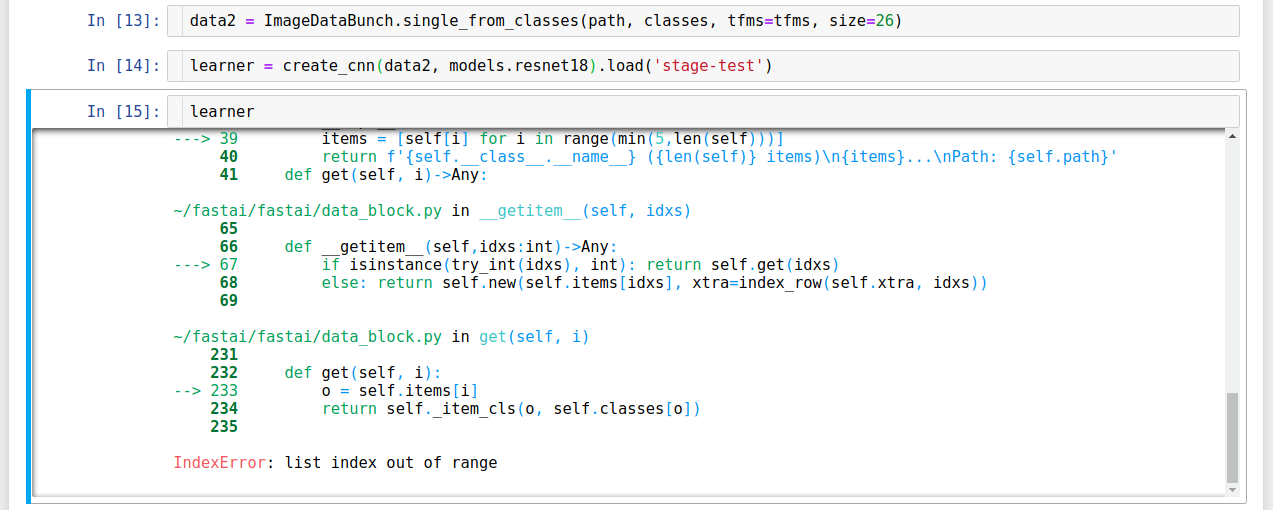
As a result ImageDataBunch.single_from_classes has been removed as the previous method is more general.
4 Likes
Awesome! Sylvain can you point me to the scripts you are using to create the pre-trained model, I’d like to see if I can get some improvements using BiLM training and qrnn.
A post was merged into an existing topic: Fastai v1 install issues thread