While you’re changing the API, perhaps these could be normalized?
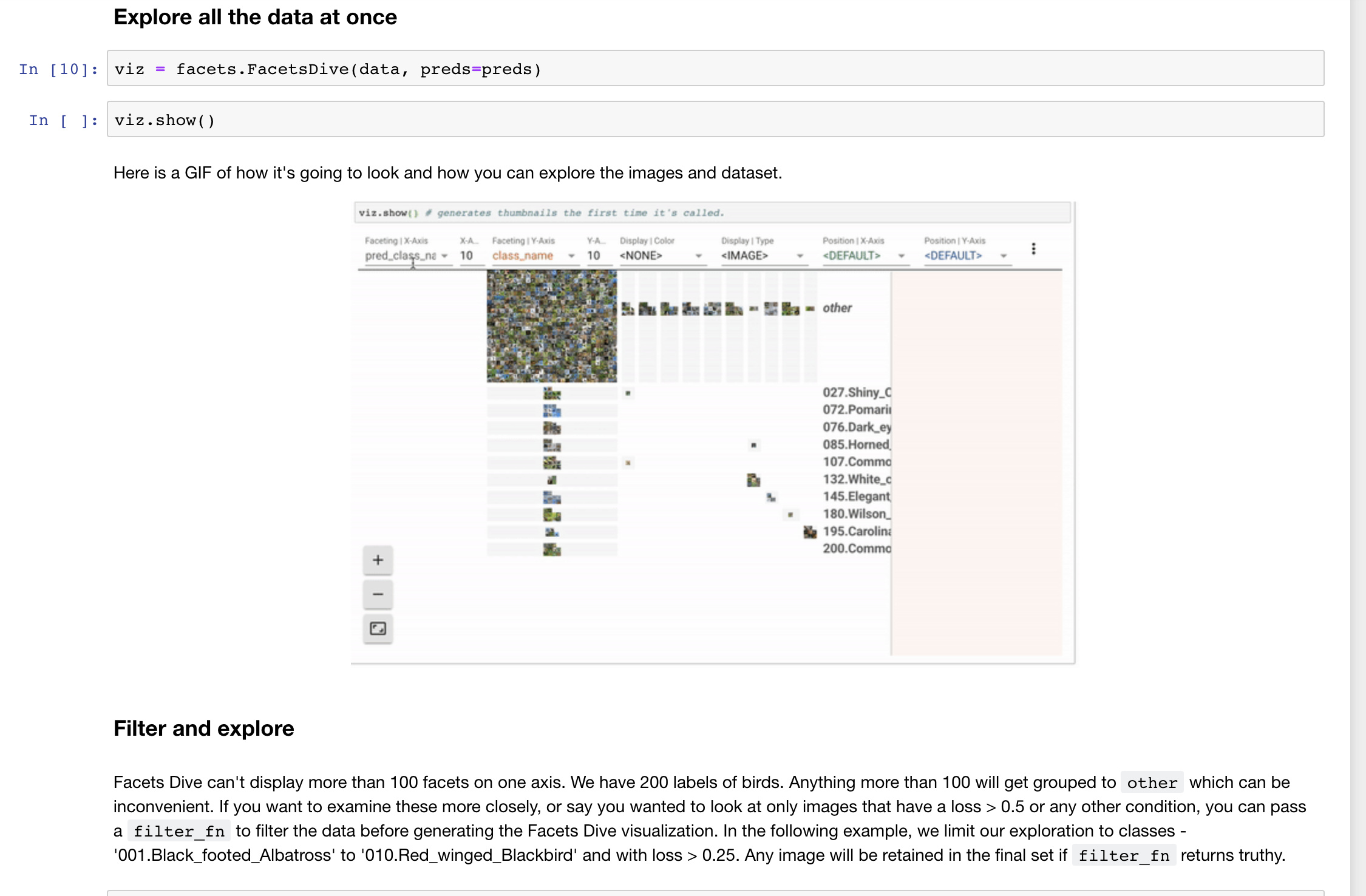
def language_model_learner(data:DataBunch, bptt:int=70, emb_sz:int=400, nh:int=1150, nl:int=3, pad_token:int=1,
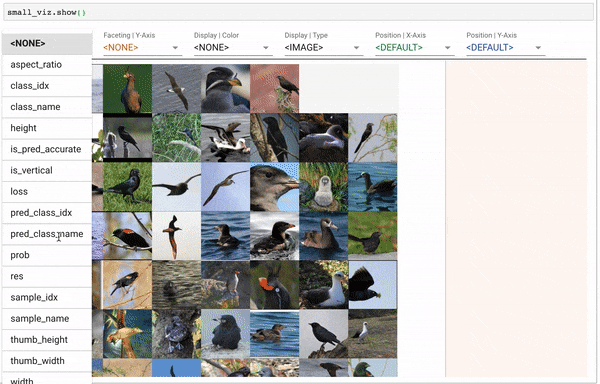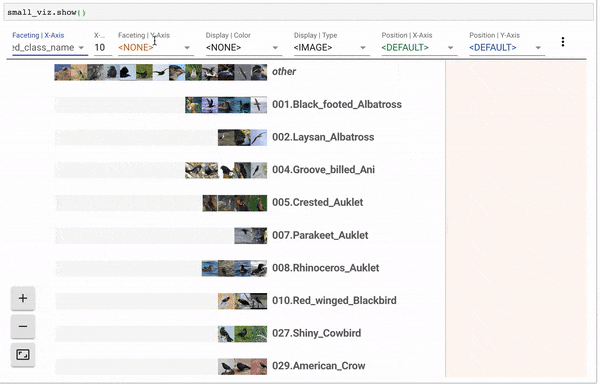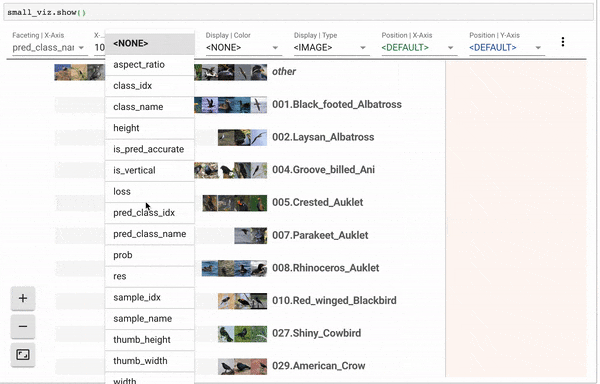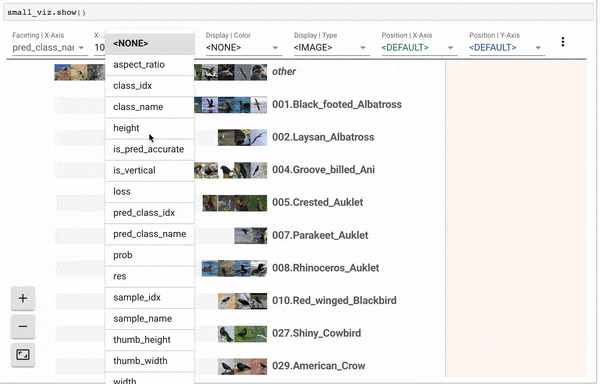
def text_classifier_learner(data:DataBunch, bptt:int=70, max_len:int=70*20, emb_sz:int=400, nh:int=1150, nl:int=3,
def get_tabular_learner(data:DataBunch, layers:Collection[int], emb_szs:Dict[str,int]=None, metrics=None,
def get_collab_learner(ratings:DataFrame, n_factors:int, pct_val:float=0.2, user_name:Optional[str]=None,
have get_ everywhere, or nowhere?
Also the first two could have their argument positions synced. text_classifier_learner injects max_len before other arguments - could probably go after, to stay similar.
and then we have:
def create_cnn(data:DataBunch, arch:Callable, cut:Union[int,Callable]=None, pretrained:bool=True,
it also returns a learner object, but the name is completely different. get_cnn_learner?
And this one has no action - get/create in the name:
def simple_cnn(actns:Collection[int], kernel_szs:Collection[int]=None,
and we use ‘get_’ in:
def get_embedding(ni:int,nf:int) -> nn.Module: