Awesome! I would not trust those initial default params as having been the result of good science  . Want to PR your new and better defaults?
. Want to PR your new and better defaults?
1 Like
Does this mean that we could now have SpecAugmentation as a part of fast.ai audio augmentations? 
5 Likes
Yeah there are a lot of problems with “squarification”, mainly that if you have audio over 1 second it starts to become infeasible because you have images that are much longer than they are wide so you have to compress the data (or you have to grow your number of mel bins to get more vertical, but then you can fit smaller batches on gpu and you have some empty mel bins as well). It works great for anything in the 0.5-1 second range but I don’t know if we can make it work.
It would be interesting to do a few tests and see how much square images actually help (above it was like 0.8% iirc, but that’s also a 20% relative improvement of the error rate), and also to see at what point horizontal compression becomes a problem. If we do both of those we should have enough info to decide what is the max length we should recommend squarifying.
1 Like
Hey, the reason I didn’t PR is that it’s a tradeoff. Those better defaults also take 4x as long, and when you are generating specs on the fly every epoch it adds up! I was having 8 min epochs running the full tensorflow speech commands (65,000 1 sec clips) compared to ~3 when I did the spectros as preprocessing. @baz and I are working on this though. If we can’t find a way to do it faster we might want to consider other defaults. I don’t have that much experience though, maybe 8 min epochs is acceptable for that dataset? Definitely worth discussing.
2 Likes
Oh nice, cool that you’re already implementing this @zachcaceres . I’d played around with it as well (just the masking, not the warping). I noticed in the paper they mask to the mean value of the melspec. I’m not sure if it makes much of a difference but could be something to try to see if it changes your results.
2 Likes
coming soon  the
the sparse_image_warp bit is not trivial to implement since there doesn’t seem to be analogous functionality in Pytorch.
1 Like
I feel like I’m spamming this thread, maybe we should make a separate thread over in /dev.
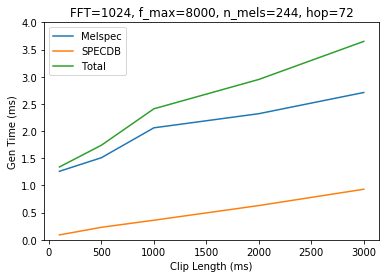
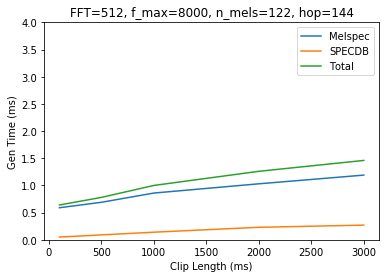
I’m running timing tests on spectrogram generation using various params, here are the results. Note that I am running 2 different SPECDB calls (power and magnitude), the “total time” listed in results only includes 1 run.
------------------------------
Params:
n_fft 1024
f_max 8000
n_mels 224
hop 72
- - - - - - - - - - - - - - -
------------------------------
Clip Length: 100.0 ms
Time Avg Melspec: 1.23 ms
Time Avg MagnitudeSPEC2DB: 0.07 ms
Time Avg PowerSPEC2DB: 0.06 ms
Time Total: 1.3 ms
------------------------------
------------------------------
Clip Length: 500.0 ms
Time Avg Melspec: 1.36 ms
Time Avg MagnitudeSPEC2DB: 0.16 ms
Time Avg PowerSPEC2DB: 0.14 ms
Time Total: 1.52 ms
------------------------------
------------------------------
Clip Length: 1000.0 ms
Time Avg Melspec: 1.69 ms
Time Avg MagnitudeSPEC2DB: 0.27 ms
Time Avg PowerSPEC2DB: 0.27 ms
Time Total: 1.96 ms
------------------------------
------------------------------
Clip Length: 2000.0 ms
Time Avg Melspec: 2.08 ms
Time Avg MagnitudeSPEC2DB: 0.53 ms
Time Avg PowerSPEC2DB: 0.52 ms
Time Total: 2.6 ms
------------------------------
------------------------------
Clip Length: 3000.0 ms
Time Avg Melspec: 2.36 ms
Time Avg MagnitudeSPEC2DB: 0.74 ms
Time Avg PowerSPEC2DB: 0.76 ms
Time Total: 3.1 ms
------------------------------
Resulting 1 second dbscale melspec:
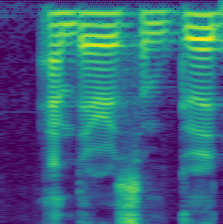
Notes: Generating the melspectrogram appears to be the bottleneck here. It also appears that the time for melspec generation scales in sublinear time. Maybe we could concat our audio together, generate really long spectrograms, and then chop them up?. SPEC2DB does appear to scale linearly. Looks like Magnitude and Power spectrogram are the same speed so I’ll omit ‘magnitude’ in future runs.
Also switching to just showing the spectrogram and a time graph now. Params are in the title of the graph. Y axis will remain fixed between 0 and 4ms for comparison. Here is the original data
Next round: Lowering number of mels and raising hop each by a factor of 2, for smaller faster image.
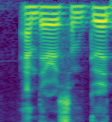
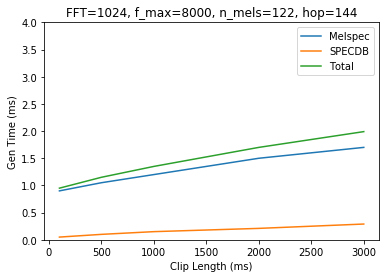
Notes: A pretty similar spectrogram in half the time. 122 by 112, we could easily squarify. Might be a good setting, especially for pretraining before upsampling to bigger. Since we are generating spectrograms on the fly there is no cost to doing this if we aren’t caching our spectrograms.
Next round: Let’s cut our number of ffts in half. With a denser image we might not need as many.
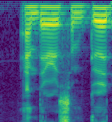
Notes: Not bad but there is some detail lost in the higher frequencies. Saved another 25% on time. This is now nearly 3x faster than our original.
If we take n_fft any lower we start having empty bins (below is n_fft:256)
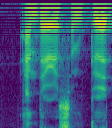
If we restore fft to 512 and double our hop to 288, we shave another ~25-30%, but at the expense of half the width of our image and no ability to squarify.
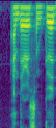
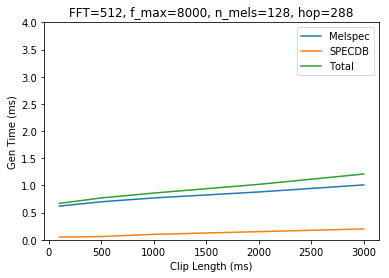
Let me know your thoughts on this.
5 Likes
Can’t wait! Thank you so much for working on it!
I am not an expert, but the window size is the trade-off between frequency versus time, for example, at 512 FFT window you will get better time than frequency resolution. At 1024 you will get better frequency than time resolution. So this trade-off has to be resolved based on what info is more important, I think (but you probably know all that already)
5 Likes
I did not know that! I am still just clicking buttons but learning a bit more each day! n_fft is definitely one of the params I have an incomplete understanding of. Gonna dig in more later, thanks for the help!
1 Like
Some example from my experiments.
- This is STFT 256 , hann window, zero overlap,
-
This is STFT 512, hann window, zero overlap same file
-
This is STFT 1024, hann window, zero overlap, same file (larger figure size though)
1 Like
I found a pc application and an android app for diarization. Did not test it yet but seems very interesting.
VoxSort Diarization is a means to improve recorded voice dialogues playback and management. Unique super fast and accurate speaker diarization technology used for the purposes. So, the software splits the sound file into segments (paragraphs) of speech produced by each participant of voice conversation. User friendly graphic representation then used to simplify navigation through the sound and playback it in a set of modes. No speech to text technologies is being implemented

2 Likes
I’ve created a notebook that can generate 3k spectrograms and save to file in 11secs using the GPU and torch audio transforms. One every 3ms.
2 Likes
Nice! Great as a preprocessing step.
While “porting” the audio module to the part 2 vernacular, I discovered we don’t need to define SPEC2DB. It’s already in torchaudio, just not documented. You can use it like
spec = transforms.SpectrogramToDB(top_db=self.top_db)(spec)
Here’s the full transform as currently written; note the semantics are a little different (eg they’re now classes rather than functions) but the steps are the same. I’ll definitely update the defaults per Robert’s investigations.
#export
class Spectrogrammer(Transform):
_order=90
def __init__(self, to_mel=True, to_db=True, n_fft=400, ws=None, hop=None,
f_min=0.0, f_max=None, pad=0, n_mels=128, top_db=None, normalize=False):
self.to_mel, self.to_db, self.n_fft, self.ws, self.hop, self.f_min, self.f_max, \
self.pad, self.n_mels, self.top_db, self.normalize = to_mel, to_db, n_fft, \
ws, hop, f_min, f_max, pad, n_mels, top_db, normalize
def __call__(self, ad):
sig,sr = ad
if self.to_mel:
spec = transforms.MelSpectrogram(sr, self.n_fft, self.ws, self.hop, self.f_min,
self.f_max, self.pad, self.n_mels)(sig)
else:
spec = transforms.Spectrogram(self.n_fft, self.ws, self.hop, self.pad,
normalize=self.normalize)(sig)
if self.to_db:
spec = transforms.SpectrogramToDB(top_db=self.top_db)(spec)
spec = spec.permute(0,2,1)
return spec
Note that they’re all pytorch ops, so if you feed it a CUDA tensor, it’ll do the processing on the GPU. We’ve implemented this as a separate transform applied immediately after load, but you could just as easily include it in the load step, or any other way.
2 Likes
Amazing this looks great. It was @MadeUpMasters who found the default parameters I just stole them
Fixed!
Hey, I’ve implemented SpecAugment and integrated it into the fastai-audio stuff, just for my own purposes/experiments. I am going to do some more experimentation to see which transforms are actually effective and which aren’t. In the course of doing this I discovered a bug I’m not sure how to fix, because I don’t have a deep enough understanding of how audio actually works. It looks like tfm_modulate_volume in the DataAugmentation notebook doesn’t actually do anything to the audio or the spectrograms.
It works exactly as I would have done it, by multiplying the signal by a constant. But if you set the gain really high, or loss really low, you’ll notice there is no difference in the audio, and no difference in the spectrogram. Here is a modulation down to 20% of the original.
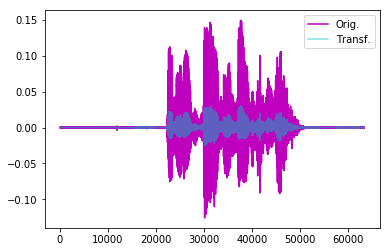
But the audio sounds identical, and these are the spectrograms of the original and the altered.
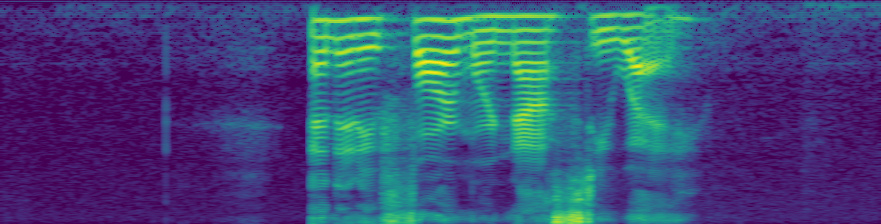
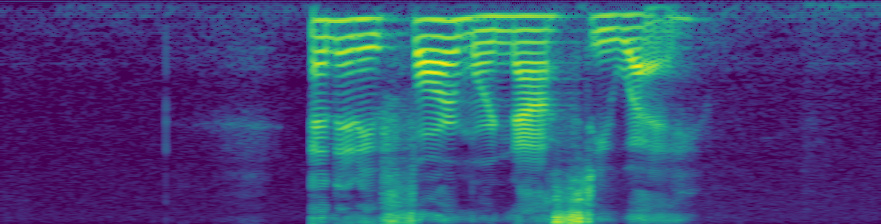
An interesting note is that if I add a constant instead of multiplying, that will have the effect of reducing the volume, which makes sense because by increasing the absolute values of the sample we are reducing the magnitude of the frequency at every step, but keeping the ratios the same (I think?) In my head it’s something like the deltas are being reduced while keeping delta-deltas the same, im not sure if that’s right.
Anyways I figured someone more experienced with audio could probably solve this faster than I can.
4 Likes
awesome!! how did you end up implementing time_warp from SpecAugment? That’s the bit I’ve been working on but it seemed to require porting a bunch of extra functionality from TF to get it exactly right.
I didn’t yet, I saw that you were implementing already for fastai audio and in the paper they state that time warping isnt a major factor in improving performance, so I took the low-hanging fruit
For now I just wanted to be able to train models with it, and also to test their assertion that this is the only audio augment that matters (when working with MFCC or melspec as inputs). So far it’s really cool, your model just doesn’t overfit, which is a big problem in ASR. I’m able to train longer/deeper, and my training and validation loss are a lot more correlated. Accuracy is going up as well.
Any ideas on what’s up with that modulate volume thing above? I’m going to do benchmarks for all the transforms on a speech dataset and noise dataset, but want to get them all tuned beforehand. Thanks!
4 Likes
ah ok, cool makes sense.
That’s awesome that it’s working so well! What are you classifying?
How are you integrating it? Are you doing the chain of augmentations for a single spectro, so as to generate one additional augmented spectro or creating multiple augmented versions or…?
We had some weird behavior with the tfm_modulate_volume and, if I recall, we could see the underlying data changed but when putting it through the Audio() listener component the change was undetectable. We chalked that up to the Audio() listener but it’s possible there’s something else going on even though you can see the data change.
Want to PR a new version or just remove it? Not sure that one matters much.
1 Like