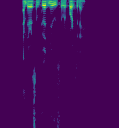
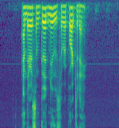
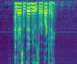
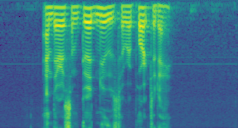
I’m sure it would be very helpful to have a large open diarization dataset; I haven’t looked very closely myself. Very strong +1 for having multiple languages if possible!
As for what kind of dataset would be “ideal”, honestly, I don’t really know yet. I suppose at least it would have to have labelled speakers and the timestamps for when each participant is talking. You’d have to make some decisions about how precise you wanted to be when it comes to speaker changes (latched speech) or how you treat overlapping speech. I think it would be very beneficial to have varying audio quality, too.
My little project is intentionally starting very minimal - a single podcast with only 3 known speakers. It will have to evolve to a very different system to generalise to an unknown number of unknown speakers, especially in a more challenging audio quality environment. From what browsing I’ve done of the literature, it must be a hard problem in the wild, as it seems nobody has done it very well!
One idea I’ve had that might be worth pursuing is whether you could treat part of it as a regression problem - trying to predict the timestamps of speaker boundaries, then using those boundaries to decide what clips to take, rather than just deciding up front “I’m going to use 3 second clips” or whatever. I’m not sure whether it really makes sense, though.
I feel like the more promising avenue would be an image segmentation approach. Just as in lesson 3 where you can label every pixel of a photo as “pedestrian”, “building”, “road” etc., I feel like you could label every spectrogram column (or bunch thereof) as “speaker A”, “speaker B” etc. This feels like it should be doable, but I haven’t gone through that lesson in detail for a while. Generating the data for that shouldn’t be too hard. Processing the data, on the other hand, could be interesting; creating & computing on 1-2hr audio clips could be a bit much…? On the other hand, you seem to only need 64 mels, and you could use a fairly large timestep for your SFTFs, to produce a 1x64x(not too many)px spectrogram… Only one way to find out I guess 
Honestly, personally I don’t think I’d be ready to try out any hypothetical dataset you’d create in the immediate term, so certainly don’t do it on my account; but I’m sure it would be a valuable asset to the community, as there aren’t very many speech datasets available in public anyway, let alone ones focused on diarisation (i.e. clips with multiple speakers, and timestamped labels).
 ) and in
) and in 
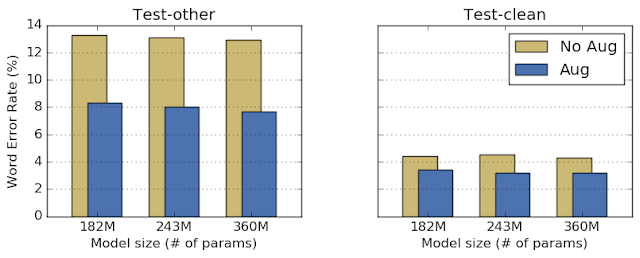 .
.