BTW, you can already use the frequency and time cutout-style augmentations if you go to the SpecAugment repo. only time_warp is taking longer. The notebook is still a bit messy but you can copy the functions which will work well with the existing fastai audio stuff.
1 Like
Right now speech, but I’m setting up two smallish test sets, one for noise and one for speech to try to
find the best results I can get with various transforms and see which actually help.
I’ve been just augmenting the spectro after with all other transforms (except padding) turned off. So for each epoch I should be getting the same base spectro (regenerating them each time which is inefficient since I’m not using any of the pre transforms), and then getting a different end spectrogram because specAugment.
I thought that too but it can’t be the Audio() listener because it is happening on the spectrograms. I actually think that one (or maybe a more complex version that augments different parts of the clip to simulate various levels of volume at different points) may be worth keeping. I think it’s worth fixing and testing. For now I can simulate it by adding a constant to the tensor to lower volume, but I can’t wrap my head around how to increase the volume in that same way without altering pitch. There must be some good way to do it though, maybe @hwasiti knows?
1 Like
I use GCP that I set up following part 1 instructions, do I need to update fast.ai so it will have audio part or will it grab these functions automatically?
1 Like
Right now fastai hasn’t incorporated audio into the real library. So you’d have to use the separate fastai-audio repo (on my Github) that everyone has been contributing to. Hopefully in this next week can find out how it’s going to end up as a real library 
3 Likes
Not at a computer so can’t check, but have you looked at the values in the spectrograms? It would make sense that the pictures look the same if they were just increased by a constant.
I’m not very convinced that volume is a fundamentally meaningful thing to target for augmentation anyway. For a start, it doesn’t generally map to a “semantic” difference at least for speaker/voice classification - the same word is the same word no matter how loud you say it*. I would rather just not include this as an augmentation than worry about why it doesn’t seem to be working.
*Things might be different if you were targeting eg. emotion in speech or non-speech sounds - volume is certainly interesting in plenty of contexts, just not for speaker or word or phoneme classification.
2 Likes
Does anyone have any experience with the math behind adding spectrograms together? Now that we’re working on applying transformations directly to spectrograms, it might be useful to convert some of these transformations that are signal-based to being spectro-based. Let’s call spectrogram sg() for simplicity. I was wondering if sg(signal) + sg(white noise) = sg(signal + white_noise).
It doesn’t, but with some tweaking it can be close. If we do a sg with to_db_scale=False, and then add them together, before applying SPEC2DB, we get almost identical outputs, as seen below. That means we could almost certainly unpack the log math in SPEC2DB and find a way to sum for that transform, and then directly apply the transformation to the sg. In images below, all math is done on sg generated with to_db_scale = False, but for the image display I first passed the underlying sg to SPEC2DB because it’s a better comparison. The bottom two are very close but not the same.
(spectro_ex2.squeeze()-spectro_sum.squeeze()).abs().mean() is 0.014 for tensors with means of 0.35, so there’s about a 2.5% difference.
sg(original_clip)
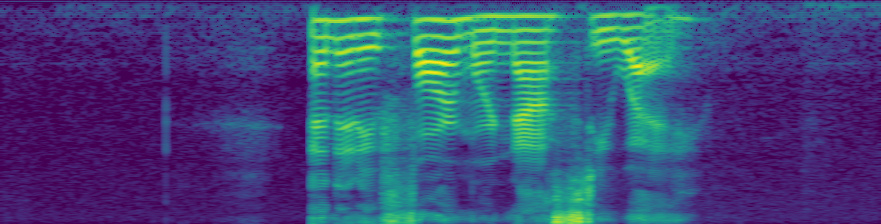
sg(white_noise)
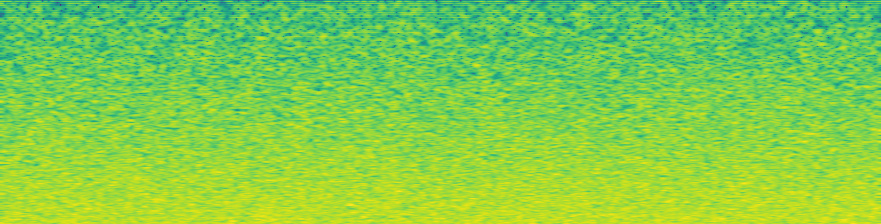
sg(sample + white_noise)
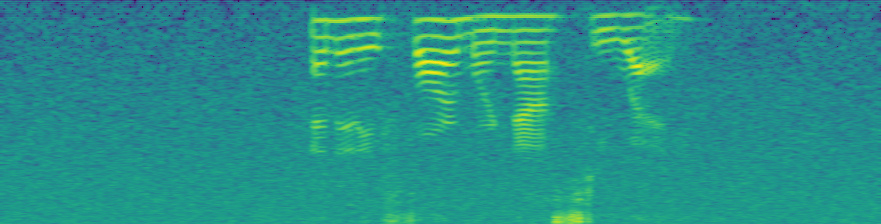
sg(sample) + sg(white_noise)
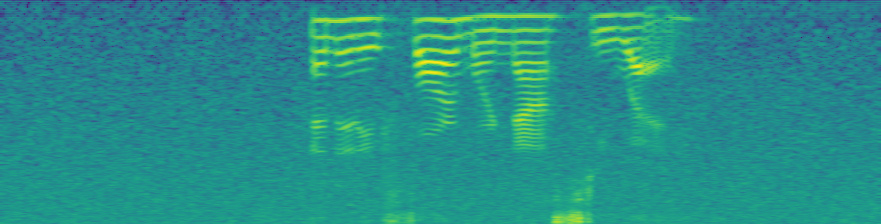
3 Likes
Isn’t this exactly what we are looking for with augmentations though? We seek a change that could possibly turn up in our test set, but that wouldn’t change the classification itself. For instance when he horizontally flip a cat, it’s still a cat. I’m not sure volume is going to be a great augment either though. One way to test it would be taking an already trained model (like I have for tensorflow speech), reducing the volume of some test set samples by various percents and seeing if accuracy falls.
1 Like
I think volume increase does affect the spectrogram, after all the color scale is a dB scale. Waveform does show the amplitude, but spectrogram reflects sound intensity too.
1 Like
I’ve been working with @MadeUpMasters on the transformations
and after combining shifting and adding @MadeUpMasters transformation to spec augment, we’ve trained a resnet18 to 99.7% accuracy in 4 epochs in just over a minute on the 10 English Speakers dataset.
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 1.187849 | 2.330175 | 0.291667 | 00:19 |
| 1 | 0.482742 | 0.099135 | 0.968750 | 00:19 |
| 2 | 0.225240 | 0.020389 | 0.994792 | 00:19 |
| 3 | 0.115538 | 0.013366 | 0.997396 | 00:19 |
In 9 epochs we’re able to get 100%:
| 5 | 0.111717 | 0.156179 | 0.957031 | 00:19 |
|---|---|---|---|---|
| 6 | 0.068287 | 0.014517 | 0.993490 | 00:19 |
| 7 | 0.044492 | 0.005885 | 0.998698 | 00:19 |
| 8 | 0.027103 | 0.002184 | 1.000000 | 00:19 |
| 9 | 0.015127 | 0.001858 | 1.000000 | 00:19 |
Please note actually that I have modified the fastai AudioData class to cache spectrograms in the file system so will not work unless you use the classes from this branch.
5 Likes
In this notebook you’ll find an experiment on a small version of the google free sound dataset made by @MadeUpMasters.
Without transforms he got roughly 93.5% after 15 epochs with resnet50.
With transforms we were able to get to 94% with resnet18 after only 4 epochs and 98% after 18 epochs.
3 Likes
For anyone interested in the freesound kaggle competition, I’ve created a notebook using the fastai.audio module to import the data. The dimensions of the generated sg are too large but its something to get started with.
1 Like
I think that equation is correct. Adding signals in the time domain is the same of adding them in the frequency domain. And you are right, db scale should be to_db_scale=False. Because for nonlinear y-scale like db adding signals should be done in that context. Linearize the db scale into linear (power operation) and add them, then convert to db again.
2 Likes
I spent the morning playing with stacking spectrograms to 3 channels. First I just copied the same spectrogram 3x and fed it to resnet50 instead of using @ste’s code to modify the first layer. This didn’t improve so @ste’s alteration works great!
Next I started looking at passing stacks of multiple different spectrograms (sgs). I made sgs with 3 different n_ffts per (thanks @kodzaks) and stacked them. I saw about a 1% accuracy improvement (25% reduction in error rate) over any individual n_fft choice, but I was unable to replicate on resnet18. Resnet18 seems to do poorly with high n_ffts relative to resnet50.
I also altered my SpecAugment code to handle multi-sg images (I decided to make it mask all 3 channels in the same way, otherwise it wouldn’t really be hiding enough data). Running a 3 channel sg with n_ffts of 250, 800, 1600 with SpecAugment on resnet50 produced the best results, giving 97.7% accuracy on a test set that was getting 95.8% accuracy from 1 channel w/o specaugment. 1 channel with specaugment yielded 96.6%.
SpecAugment really does a great job of keeping stuff from overfitting and allowing you to train longer.
6 Likes
Also I’m worried that without normalization all these grid search results are going to be skewed. I just implemented batch_stats() and normalize() for the AudioDataBunch (literally copy-pasted from the ImageDataBunch but it applies equally to multichannel spectrograms as well as raw audio). I’ll submit a PR in a bit.
I wasn’t sure how to structure it in a notebook so I put both methods in the AudioDataBunch class and then just put the helper functions (normalize_batch/channel_view) outside in a cell with #Export. Not sure if that’s best, please revise if not. Thanks
1 Like
Just for fun, in addition to OpenAI’s remarkable MuseNet (made by fast.ai alum @mcleavey!), which is way too sophisticated and mature for me, here’s a 24/7 stream of “neural network generated technical death metal” by the (meta-? post-? virtual-?) band Dadabots (and a paper of its implementation so it still seems a little sophisticated). 
I gotta say, as a bit of a technical death metal fan myself, this stuff is pretty good; they were clever to pick a genre which if anything is improved by being a little bit “unnatural” sounding. I used to listen to Eigenradio back in the day:
All those stations, playing all that music, all the time! There’s at least 40 different songs being played every week on most radio stations! Who has enough time in the day to listen to them all? That’s why we’ve set up banks of computers to do the listening for us. They know what you really want to hear. They’re trading variety for variance. Eigenradio plays only the most important frequencies, only the beats with the highest entropy. If you took a bunch of music and asked it, “Music, what are you, really?” you’d hear Eigenradio singing back at you. When you’re tuned in to Eigenradio, you always know that you’re hearing the latest, rawest, most statistically separable thing you can possibly put in your ear.
It resulted in mostly noise but with enough rhythm to be interesting & some definite motifs were evident. There was even an Eigenradio Christmas album — you can definitely hear the carols coming through the noise.
It was taken offline years ago, but I’m now finding out was made by Brian Whitman, who went on to be the CTO/cofounder of Echo Nest, then research @ Spotify… maybe mucking around with audio isn’t just for fun after all
@mcleavey, what do we have to do to add metal/industrial as “styles of” to MuseNet?
3 Likes
Haha, right now MuseNet is all midi (would love to expand to raw audio in the future, but not anywhere near that for now). If DeathMidi exists, I’ll add it to the dataset
4 Likes
@JennyCai and I finished implementing Spec Augment in Pytorch. Hope it proves useful if you haven’t already tried it.
8 Likes
Great! Can’t wait to try it!
1 Like
Has anyone tried using U-nets for audio reconstruction? There’s been some GANs work, but I was thinking about the super resolution from lesson 7 and using lossy audio instead.
1 Like
This is super cool. Thanks for sharing! I’m down to help on a technical death metal music project
1 Like