Ementa (20/11/2019 - UnB - Brasília)
[ 20mn ] O que aconteceu online desde a aula precedente
[ 20mn ] Lista dos projetos
[ 15mn ] Organização da conferência de dezembro (data, horário, lugar, responsável geral, responsável da logística, responsável da comunicação, mentor dos projetos = Pierre)
[ 10mn ] Pontos-chave da turma anterior
[ 30mn ] lição 5 (veja “Videos timeline”)
Notebooks:
Excel spreadsheets:
[ 1h25mn ] Oficinas práticas
Imagens (Pierre)
NLP (Thiago)
[ 0mn ] Fotos da aula
Videos timeline
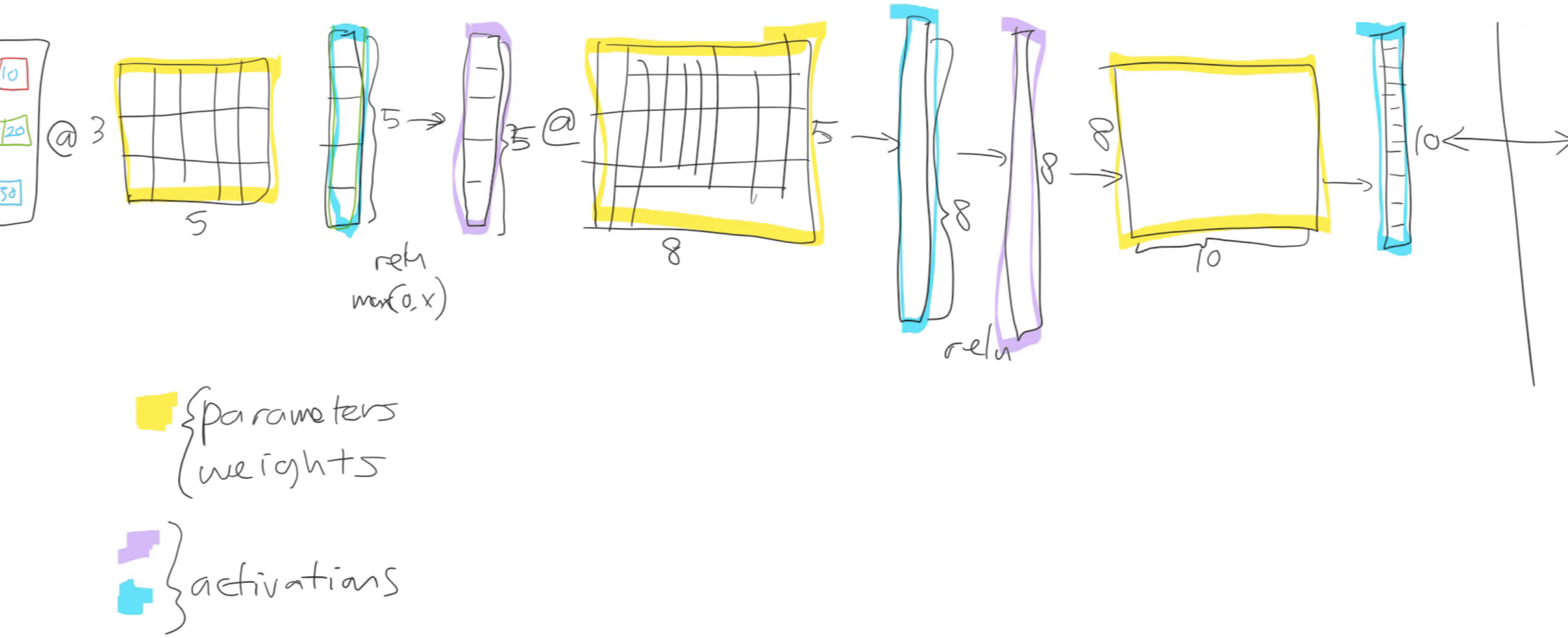
Review of last week + parameters or weights/activations + backpropagation [3:32 ]
Fine tuning [8:45 ]
Freezing layers + Unfreezing and Using Discriminative Learning Rates [13:00 ]
Affine Function (matrix multiplication, linear function) [20:24 ]
Embedding [22:51 ]
Embedding once over + latent factors/features [27:57 ]
Bias [33:08 ]
Jeremy’s tricks for getting better results [43:18 ]
Interpreting bias [49:29 ]
Interpreting Weights + pca [54:27 ]
collab_learner + nn.Module + forward() [1:00:43 ]
Embeddings are amazing [1:07:03 ]
Regularization: Weight Decay [1:12:09 ]
Going back to Lesson2 SGD notebook [1:19:16 ]
MNIST SGD [1:23:59 ]
MNIST neural network [1:40:33 ]
Adam [1:43:56 ]
Momentum [1:48:40 ]
RMSProp [1:53:30 ]
Adam [1:55:44 ]
Fit one cycle [2:00:02 ]
Back to Tabular + Cross-Entropy Loss function + Regularization (weight decay, BatchNorm, dropout, Data Augmentation) [2:03:15 ]
Recursos
Exercícios até a próxima aula
Publique em seu blog sua compreensão do que é:
Embeddings
Affine function (matrix multiplication, linear function) and Bias
Transfer Learning and fine-tuning (freeze, unfreeze, Discriminative Learning rate)
Adaptative Learning rate (momentum, RMSProp, Adam, learn.fit_one_cycle())
Regularization (weight decay)
Loss function (MSE, CrossEntropyLoss())
Execute novamente seus primeiros notebooks sobre classificação de imagens com esses novos truques e tente melhorar o conteúdo de seus modelos (atualize as postagens relacionadas)
1 Like