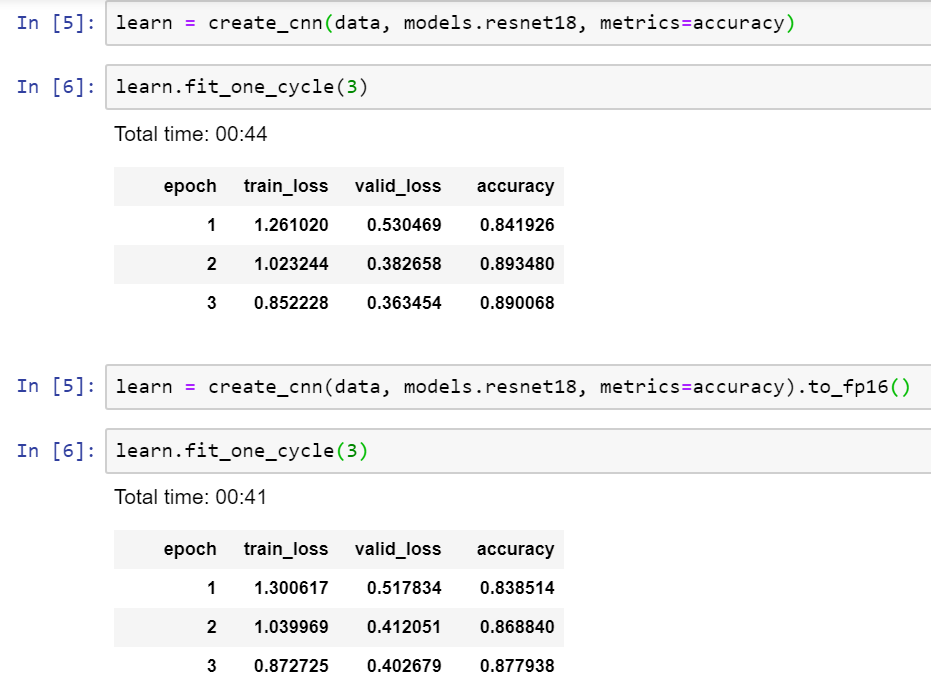
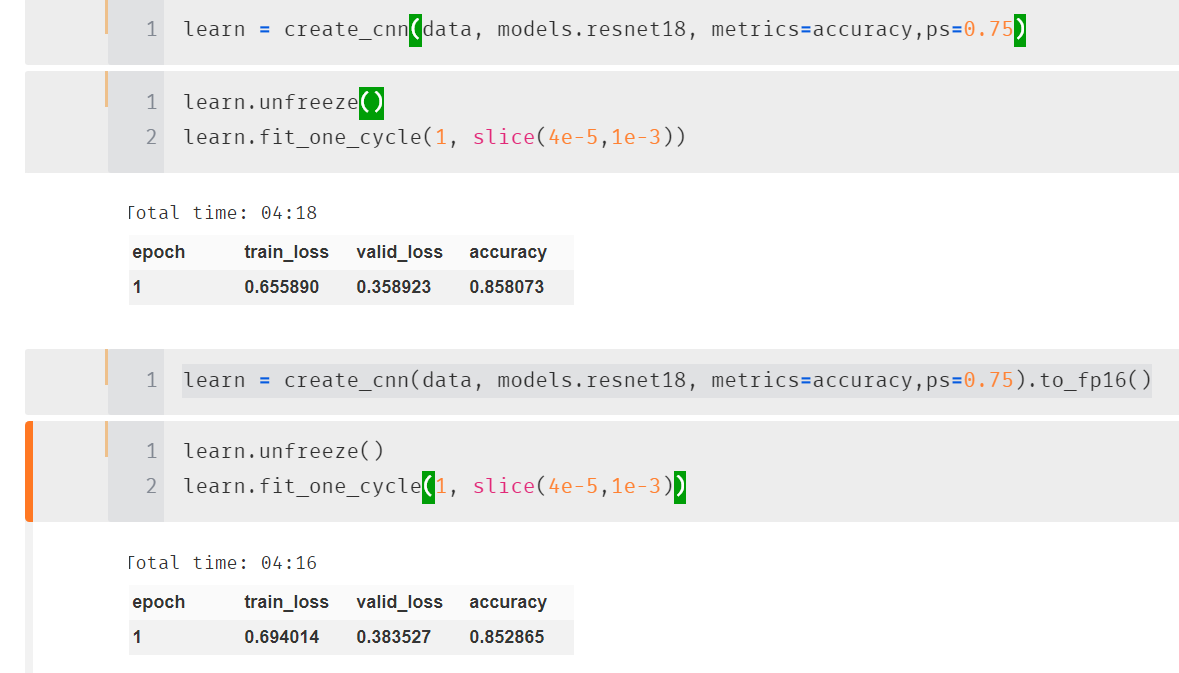
I had the opportunity to train Cifar-10 and Cifar-100 in Computer Vision, using the whole range of ResNet 18 to 151, with an RTX 2060 and a GTX 1080Ti on the same PC.
The key point being the use of the RTX “Tensor Cores” with .to_fp16(), to switch from FP32 to FP16 (or Mixed-Precision-Training / MPT).
(making sure I post on the right thread this time)
Wow, thanks for doing this Eric! I’m sure there are plenty of things the 1080ti does faster, but it’s encouraging to see the 2060 pulling its own like a champ on Cifar.
I vote yes for the dual 2060 machine, simply because I just built one myself No SLI capability, but I like the idea of being able to run simultaneous jobs and/or experiments. Gonna do some testing later this week, hoping for the same outstanding results!
Finally got the datasets from course.fast.ai like a normal person and WOW. I am very impressed! While my setup is a little slower (i5-8400, only 16GB RAM) I was able to get within a few seconds of your results on Cifar-10, Resnet 50, 2xBS. Didn’t have the patience to try the full 100/152/2x run but one epoch looked promising.
Simultaneous dual card performance isn’t bad at all. Thermals aren’t wonderful (the top card hit mid-80’s C on my one-epoch 152 run) but the slowdown was less than 5%. Will probably be a little worse over more epochs. Overall, this is very exciting. Thanks again for sharing your discovery!
Did you use RTX 2060 and GTX 1080 TI in the adjacent slots or did you compare them independently? I am planning to add a RTX 2070 to the second slot with the first one being a GTX 1080 TI. I was wondering if I’d run into any problems?
I would also ask both Eric and Sritanu, what is the slot spacing of your motherboards. Mine is what I’d call “3-slot” spacing. Each 2060 card takes up 2 slots, then there is a single empty slot between the two cards. That’s why I didn’t get the smaller triple-slot 2060 cards - they would have been literally right next to each other, with no spacing in between.
I’m guessing that extra slot makes a big difference. I believe Tim Dettmers tried some sort of 4x card setup - dual-slot cards and motherboard, no spacing in between - and the thermals were awful. Of course, that was with 2080ti’s, not quite the same here.
EDIT: In Eric’s post he mentions the motherboard, it’s an MSI X370 Krait. This has roughly the same video card slot layout as mine (GB Z370XP SLI), which has 3-slot spacing (i.e., one card slot, then 2 empty slots, then another card slot). There’s also a third card slot, but only 2 slots below the second one, and only 4 PCIE lanes.
Got it, that also has triple slot spacing. Couple of points -
Speed: on that board, the second card will only have 4 PCIE lanes. Not sure what the slowdown would be there, Tim Dettmers said 16 to 8 wasn’t bad but I don’t remember any comments on 4.
Temperature: I hit 85C on the top card, 75C on the bottom, at one epoch on Cifar 100/Resnet 152. My top card slowed down about 5%, but I would expect more than that on a full 30 epoch run.
Let’s wait for Eric to comment since he has a more comparable situation to yours (1080ti+2060 rather than dual 2060’s).
My 1080Ti is a blower version, so it expels the heat directly out of the case through a vent below the DisplayPort/HDMI connectors. It’s noisier than a regular gpu with large fans, because of the wind tunnel effect.
As I tried to explain in my article, I tested both cards in the non-display slot (port “1” iirc) while the other was handling dual-monitors in port “0”. You can see it being checked at the start of every Jupyter notebooks in my GitHub repo.
I also did a quick comparison running the Cifar-10 test with the 1080Ti in port “0”, as shown in the “Bonus” charts at the end of the article.
Basically I lost 5 to 10% of computing power (on a 1080Ti) if it’s handling my dual-display as well. Might be more for a smaller GPU.
According to the manufacturer specs, the MB PCIe’s can handle x16 for a single GPU, or two x8 for dual GPUs. I’m not sure dropping from x16 to x8 has a great impact on performance. But since I tested the cards into the same setup, this should render the impact neutral hopefully.
@crayoneater I think you would experience a large performance hit due to the x4 PCIe lanes.
Can you double check the lanes your card is getting by grepping it from the terminal (use lscpci and grep to collect the GPU portion)
I think the thermals are slightly nasty-I might be wrong, please excuse me if I am-what I know is-you need to ensure that you get stable temperatures over long duration of training loops.
Another suggestion: If you want to use both the cards together, you might want to increase your RAM as I’m not very sure if 16GB would be able to handle both the cards in //. The workaround for this can be allocating more SWAP space.
Hi Sanyam, thanks for the inputs My board is an SLI board so the cards run at x8/x8. For “x4” I was referring to the extra card slot Sritanu’s Z370A board, which does not appear to be an SLI model.
Longterm I do worry about the temperatures. I’ll try experimenting with fan speed settings, extra fans, possibly a different case or additional cooler system. So far I have not had an issue with RAM, and a 16GB swap file. I am wondering if FP16 allows you to get around the usual “RAM >= 2x VRAM” recommendation?
I had done some tests and it wasn’t as dramatic a speed increase, if any, than when using FP16 on the 2060. But that might be due to some bottlenecks on my PC too.
Did you check the difference in memory occupation both on the 2060 and on the 1080ti?
Now, I have some considerations about Pascal vs. Volta/Turing in FP16, but it will be better to split them in two: memory and speed.
Speed
First of all, please note that a Pascal card should have 1/32 fp16 performance with respect to fp32. This doesn’t happen, and I’d be curious to know why.
That said, let’s talk about what actually happens. Interestingly enough, different people find very different results.
You found a slowdown of ~5-15%.
I found a slight speedup (see below)
Other people found a substantial speedup: https://hackernoon.com/rtx-2080ti-vs-gtx-1080ti-fastai-mixed-precision-training-comparisons-on-cifar-100-761d8f615d7f
Again, I’d be very glad to know why that does happen.
Memory.
One advantages of volta/turing is that you can almost double your memory thanks to fp16, so a 2060 appears to be on par with a 1080ti even when it comes to memory.
But this remains valid even for Pascal: memory occupation is almost halved on my 1080ti as I train in fp16.
I ran numerous benchmarks in the past, but as I did read your article, I decided to run some additional ones just to have fresh result with fastai 1.0.45 and nvidia apex, which I installed both upon my machine at job (tesla V100), and at home (1080ti).
Mind that I ran the tests upon different datasets since I was in a hurry, but what counts in the end is the net difference between fp16 and fp32 on both cards.
Note that you don’t need SLI or NVlink to train in parallel. And even in x8/x8 gen3 setup, you should enjoy good performances. Try and use your two cards with DataParallel.
I don’t have the RTX 2060 anymore to run additional tests.
Back then, I tried to run:
Cifar-10 in three setups (1080Ti as a main card handling dual-display as well, 1080Ti on 100% training/no display overload, 2060 on 100% training),
Cifar-100 in two setups (1080Ti and 2060 on 100% training, no display).
Overall, each notebook ran all ResNet models for 30 epochs, that’s what I recorded as “Time to complete 30 epochs”, and running all 5 notebooks took about 90 hours over 5-6 days in multiple sessions.
FWIW, my PC is using an AMD Ryzen 1700X CPU, while @init_27 and @Ekami have Intel I7-7700/8700K CPU.
Could that explain the difference in performance in FP32/FP16 with the 1080Ti ?
On KaggleNoobs Slack, there were some rather technical discussions on AMD vs Intel. Check the threads where @laurae (who runs the “LauraePedia” channel) intervenes, he has an amazing knowledge on hardware low-level libraries.
BTW, how do you check for “GPU Memory Occupation” while training ?
I wanted to check it but didn’t know the command
@balnazzar Someone from Nvidia has recently reached out to me informing that I had used un-optimised libraries, they’ve pushed out even more optimizations which means that the speedup will be even more now (I’ll report my experiments soon).
I think not. Definitely. An eight-cores Zen has plenty of power to fill whatever GPU.
For the record, I have a xeon E5-2680v2 on the machine with the 1080ti (10C/20T).
I’ll check the Kaggle thread you seggested, however.
watch nvidia-smi will do, however I suggest gpustat (pip install gpustat), which is much more compact. Example:
Thanks, that would be awasome. Would you anticipate something?
Apart from that, what really surprised me was the substantial speedup (~15%) recorded even on the Pascal card. I recorded some 8%, but the point is that Pascal should slow down by 32 times when using fp16!
And still, it is clear that Pascal were working in fp16, since the memory occupation was almost halved.
If you are into hardcore understanding of CPU/GPU mechanics, you should deffo join https://kagglenoobs.slack.com/ and look for the channel “Lauraedia”, it’s seriously serious
Can be a bit blunt if you don’t master the subject (like me), so you are warned
@balnazzar I think RTX would have even further speed improvs. Not sure about the GTX cards.
Would you be interested in running another set of benchmarks that the Nvidia peeps have suggested to me?
My orignal experiments were with Tuatini, but it would be rude to bother him again (The orignal test iteself took too long).
I just have a 2080ti card so can’t do comparisions.
 No SLI capability, but I like the idea of being able to run simultaneous jobs and/or experiments. Gonna do some testing later this week, hoping for the same outstanding results!
No SLI capability, but I like the idea of being able to run simultaneous jobs and/or experiments. Gonna do some testing later this week, hoping for the same outstanding results!