Yes, of course! I do have pascal/volta, but don’t have turing. Together, we can do significant comparisons.
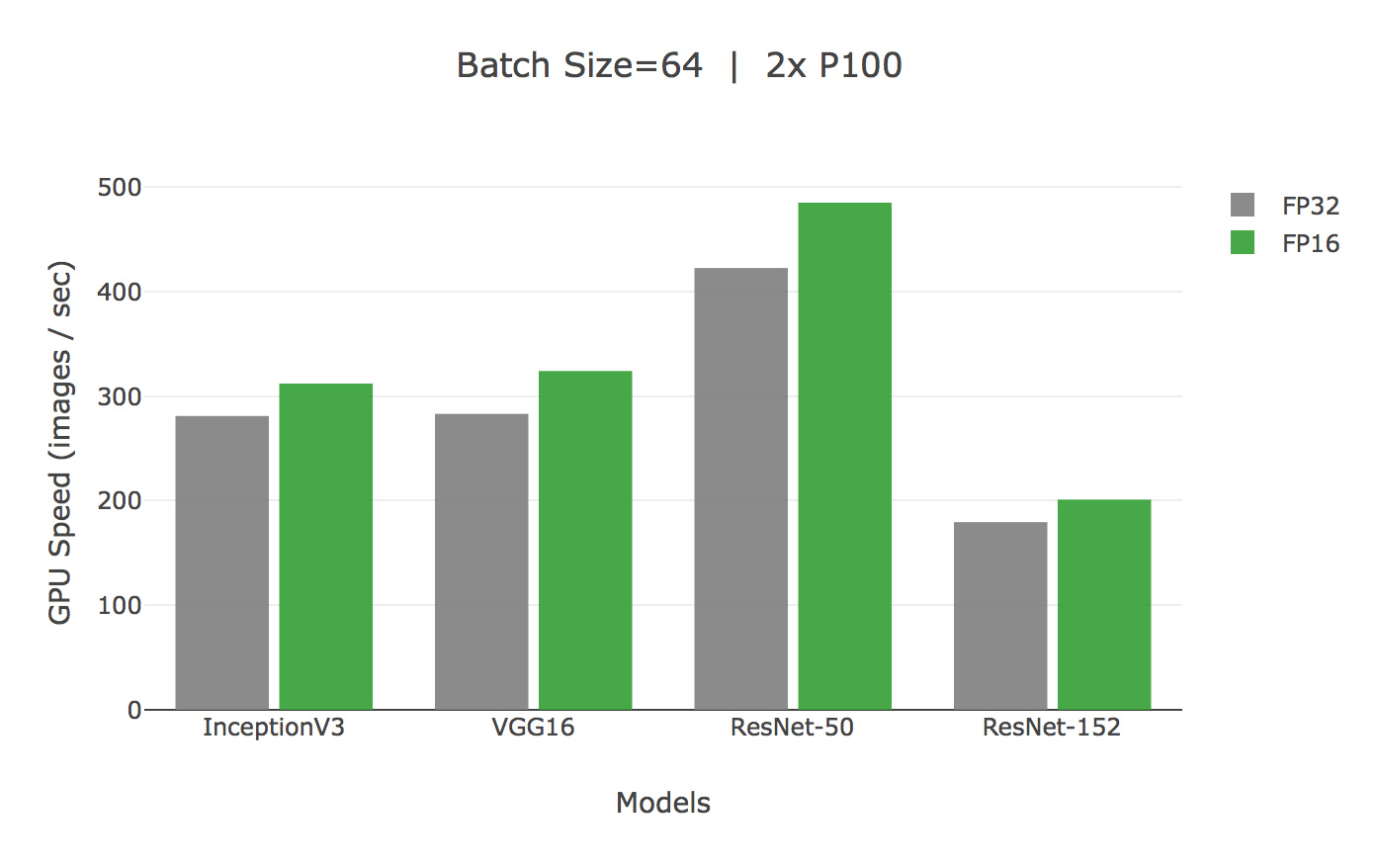
Another thing…: Another set of benchmarks from 2017 seems to confirm what you found for pascal: the speedup in fp16 is not dramatic, but it’s still there.
Other than memory and timings, pay attention to the losses: if one has to do more epochs, the speedup deriving from fp16 is of little use.
Note for @stas: yours is an awesome tool, but it does not seem to work with the teslas. Maybe teh ones I use (dgx station) are a bit different from the ones usually found in cloud instances?
And thank you for your kind words, @balnazzar - I’m glad you find it useful. I think it is still a bit clunky and evolving so any feedback for improvement is welcome.
I got three of them (blower version), which replaced my previous two 1080ti since Pascal shows issues of convergence when you use it in FP16.
Essentially, they are equivalent to the 2070 (non-super), at a lower price point and TDP. Thus, the 2060S got an amazing price/performance ratio, the best among the cards with 8Gb.
I paid ~1000EU for the three of them (but sold the 1080ti at the same price). With a TDP of 175W, they don’t tax the power supply so much, contrarily to the more power-hungry siblings.
Note that in any task which can be parallelized with DataParallel, you got 24Gb of vram (= titan rtx) for just 1000EU/$, which, together with 16-bit training, allow you to train even big transformers (except for the few biggest). If you motherboard allows you to stack four of them together, that’s even better.
NVLink: the NVLink for the nvidia consumer segment essentially is a toy, much different from the NVLink you would find on titan/quadro/tesla. Forget it, you’ll be fine with the pcie bus, as long as you get at least 8 lanes per card.
That’s good news. I’m considering two non-blower versions with a 2.7 slot width (XC ultra) due to the higher demand and resale of the non-blower cards. I’ve got the airflow and EVGA thinks it’d be a good setup.