Hey fellows, I thought that it might be interesting to do a word frequency analysis on the self-introductions posted so far. I only processed the raw data in a very rough manner. Here is the result.
The point here is to extract all the nouns from our posts. I thought about parsing each sentence into grammatical structures first and then get the nouns, but that would actually take a long time on my poor little computer. So instead, I just filtered all the words through a noun collection and kept only ones that are longer than 3 letters. As you can see, there are still many words left behind that should have been filtered out, like ‘have’, ‘like’, 'here", etc. Supposedly they also have noun forms.
How could we apply deep learning and NLP technology here to better achieve our goal? Any idea from people who have taken the class before? Sounds super exciting to me.
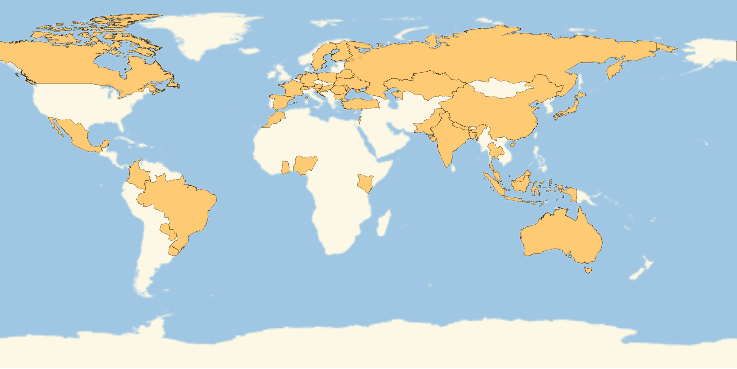
Wow! I am so impressed! We covered every continent except Antarctica. However, this is surely an underestimation, as some people did not mention their country, and the program seems only included countries whose names have only one word. Somehow, USA and UK are not included here.
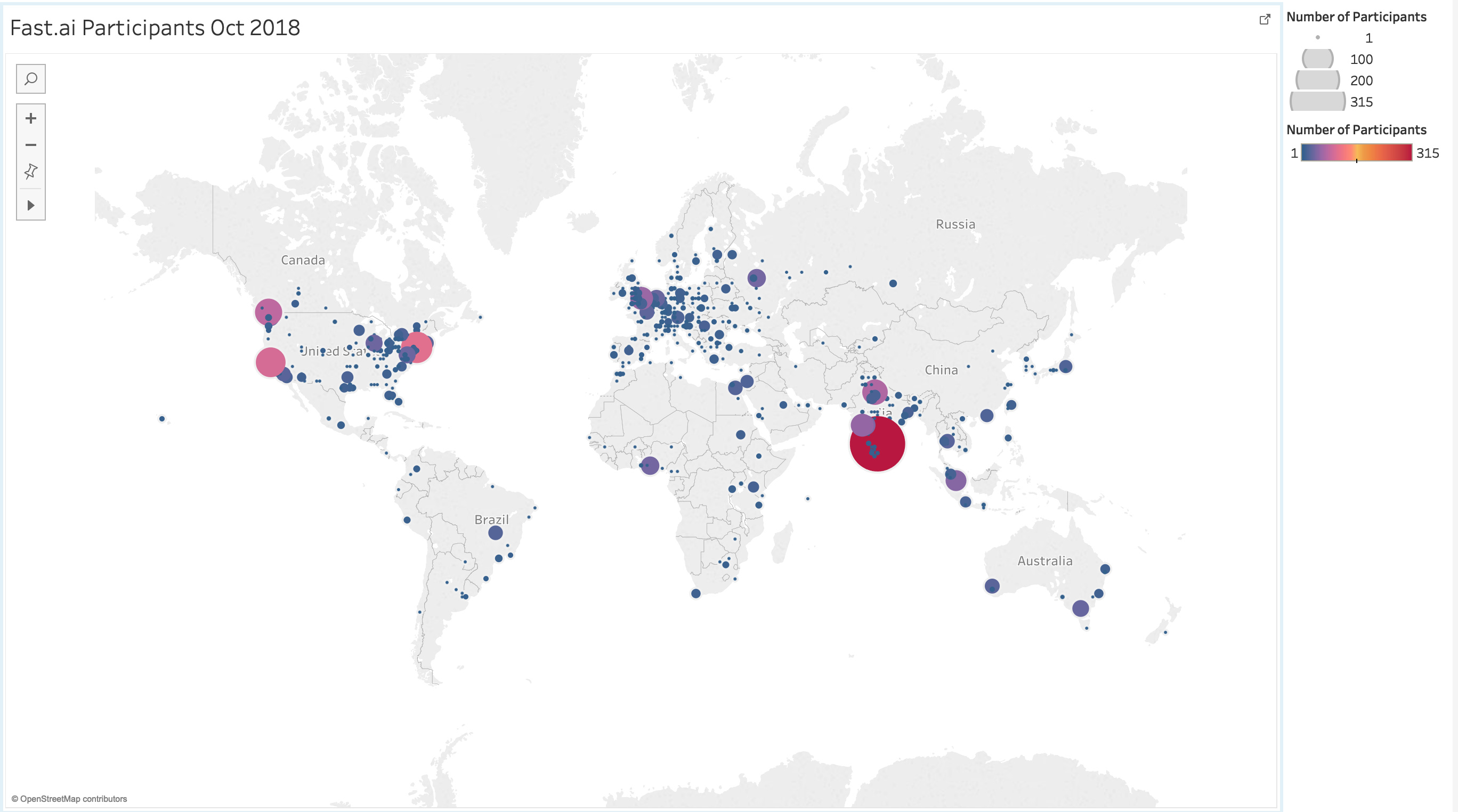
I’m going to guess that tiny little dot on Tasmania means I am presumably the only one here doing the course lol… Really interesting to see, so thanks for sharing.
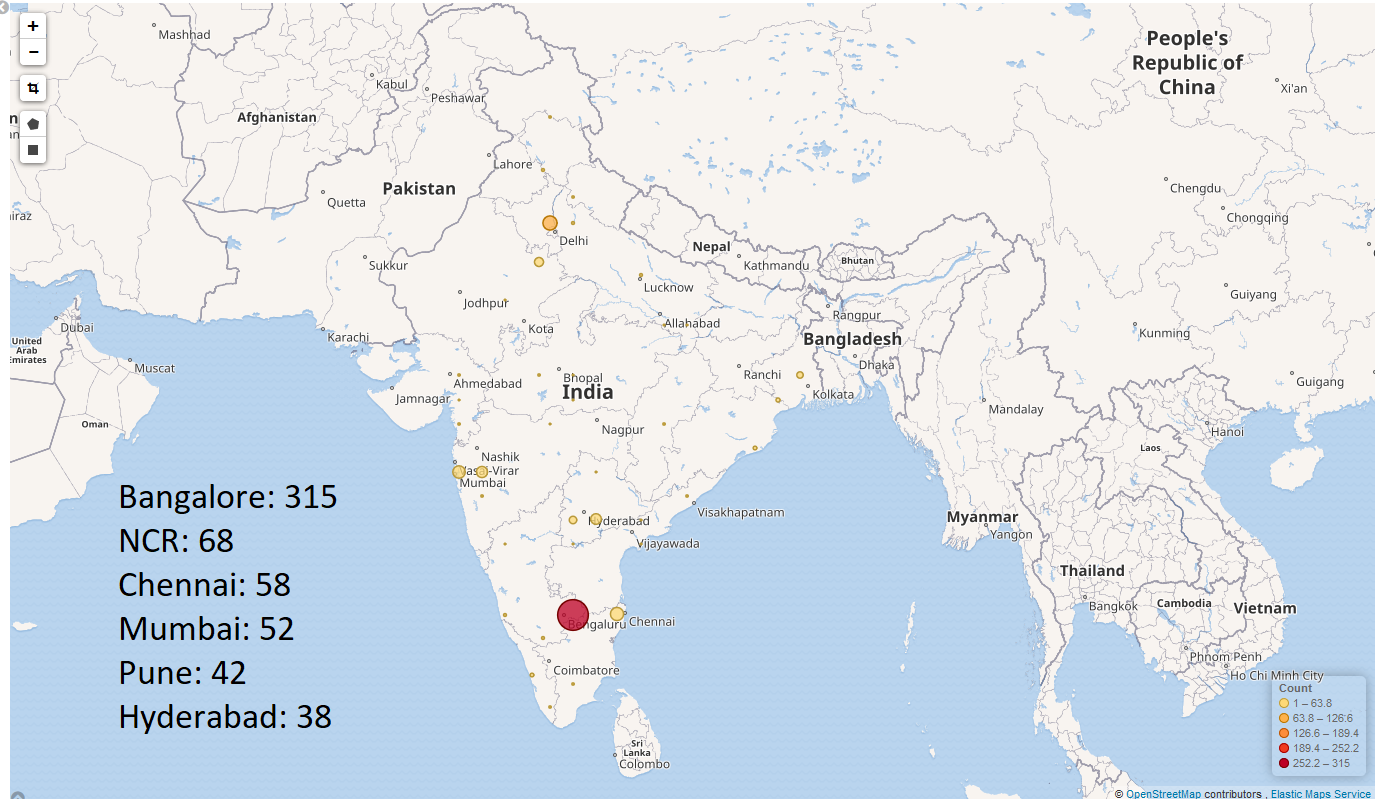
Hi Jeremy, would you mind elaborating a bit on the source of the geographic data? Are they from locating IP address? If that is the case, then I can understand why there are so few data points from China, cause they are all using VPN.
Hey Alison, the map looks awesome. Would you mind sharing the Tableau workout with the class? I would love to learn how to make a map as good as this one.