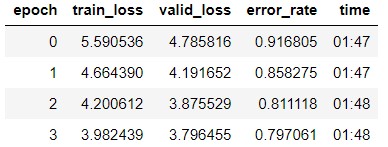
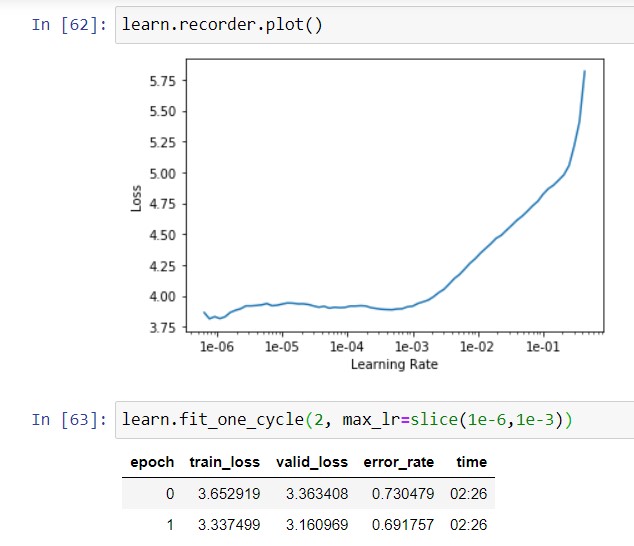
I guess I need to continue training but before I continue I’m trying to use ImageCleaner(ds, idxs, imgpath) to clean up images but for this case this widget is useless since I cannot possibly know for certain which image belongs to which class (car model).
I would just like to delete images that are most confused from whole dataset. How do I do that?
Many of these data sets have been hand curated (checked by humans), using services such as https://www.mturk.com/ where people pay others to check and label their data. Some people and organizations have actually spent years cleaning and checking their datasets.
Cleaning data is even a problem for companies such as google.
A search on the internet for something like ‘data cleansing’ may help.
Also if you read the posts in the thread below you will see some ideas you may be able to adapt to clean your data.
I certainly didn’t mean to offend anybodies work. I think fastai in general is exactly what DL community needs and confusion matrix and image cleaner are tools that are extremely useful. I used them daily.
I was just referring to specific case in which I cannot use them.
Thank you for your replay, you sure gave me a lot of useful info. Notebook you send me seems like exactly what I need. I’ll try to implement it in my case. It might be less resource demanding than what I planned to do…
What I wanted to do; since i have 400 folders with car models images where some of the images are actually not recognizable as cars altogether (parts of machine, or car interior) I was thinking on applying image detection algorithm per folder(class) which will define bounding box when it detects car than I would cut that image and paste it to another folder where I would collect only cars that where detected in images. That way cropping would also be applied to object itself.
That seemed like 1. step and than obviously some of detected images might be too small after that kind of processing - I would need to remove them as well.
After that I would try to retrain model again.
Does this seem like scenario that might be useful?
When I’m done and if all works ok I will post a blog with Jupyter notebook as well.
Hi EnHakore hope your still having a wonderful day and have an even better weekend.
I have had so much help from others such as @muellerzr and the rest of forum I feel its the right thing to do. I am still a novice but try to answer questions from my own limited experience.
My thinking was to train a model with say 50-100 clean images in a class then make some test sets with the remaining data, pass these through the model and see what percentage of bad images it finds.
Also in one of Jeremy’s video’s he shows an app that you load data into and it shows you images classified visually as clusters, which you can then create classes from. (can’t remember which video).
Any method that can decrease the amount of pre-processing we have to do is a massive help to everyone. Also I think this is one of the issues Unsupervised Learning is trying to solve in that it costs time and money to label data, so a network that can learn with unlabeled data is ideal. Even if it doesn’t work it’s worth writing a blog or notebook. I have just started on my first blog about AI using this approach Redirect (not sure when I will finish it yet) this is a challenge for me as I am not really into any social media type activity (lol).