How I built a system that runs Fast.Ai for $99 ish:
A month or so ago I ordered a couple of NVIDIA Jetson Nano Development Kits for $99 each. They advertised that the SBC had 4GB of RAM, an ARM CoreA-57 processor, and best of all, runs CUDA 10.0. Not only that, they said it runs Pytorch 1.0. Wow, I thought this could run Fast.Ai. So I ordered the systems from SparkFun Sparkfun and waited (because they were on back order and hadn’t shipped yet), until last Thursday when they arrived. The system boots from a micro SD card, so I bought a few 64GB class 10 cards for about $15 each, it supports USB 3.0 and Gigabit Ethernet.
I download and flashed the image according to these instructions , plugged the card in and booted the GUI of what looks like the Ubuntu 18.04 desktop. Since the board only has 4GB of RAM for use by both the processor and CUDA, I knew a swap drive was needed. I created one of 8GB (see below). Since I’m using this box for fast.ai, I can SSH in and save myself all the RAM used for the GUI (about 400MB), so I got rid of the GUI using another script I wrote (which also deletes some memory hog programs I wasn’t using.
I then naively tried to follow the instructions of the fast.ai website and these forums to create fast.ai. No such luck.
The Good, the Bad and the Ugly:
Unlike conda (Anacona 3.X) installing packages using pip (and in this case pip3) is no fun. The pip install regime uses python’s setup tools, which is imperfect at best. When you specify dependencies (packages your package needs to run) (and fastai and pytorch have a lot of them), It looks here and there on your machine, then gives up and tries to download and build the necessary packages from pypy (the python website). You can guess how well that’s going to work in an environment where you’re running on brand new hardware. The good news is that NVIDIA provides a pip wheel (a kind of almost pre-built package) for pytorch 1.0 (I’m not including the URL on purpose, keep reading for more good news). The bad news is that the fast.ai dependencies completely ignore that package (and yes, I tried changing the version dependencies in fast.ai setup.py). So for the next two solid days, I found apt packages that the machine would install to fulfill the dependencies, and figured out how to build the dependencies that didn’t have apt packages. The ugly news is that that when you install fast.ai using pip you must first install all this stuff and then use pip fast.ai –no-dependencies. This means that when fast.ai changes it will be up to you to find and fix broken packages. But even though I didn’t install virtualenv (a virtual environment like conda) because I was in a hurry to see if could get this working, I’ve built and tested an install script (see below) that does this all for you automatically (but it does take a couple of hours to run).
Setting up Jupyter Notebook:
After installing fast.ai, I wanted to test its performance using the same fastai course V3 part 2 notebooks I’m running on my big linux box (Core I-9, 64GB RAM, two NVIDIA GTX-1080s). But first I had install jupyter. That also proved to be an interesting install, but again after I was done I wrote an install script so you won’t have to do things like; change the default listening IP to 0.0.0.0 from locahost, setup a password, etc.) and now I was almost ready to how well the notebooks ran.
Memory isn’t everything, but it’s definitely something:
Back in the old days (of say 2010), 4GB was a lot of memory. And If you’re not using the GPU on this board, it is enough to get your notebooks running well (the 8 GB of swap file helps quite a bit). But if you’re using CUDA, it doesn’t run on the swap disk, so you need each and every byte of that 4GB. To get that, it’s time to jettison the GUI and run via a remote console using SSH. So with a few more steps (see below), I was able to get the total memory for linux and jupyter notebooks down to around 500MB, leaving around 3.5GB for CUDA.
And now the Results:
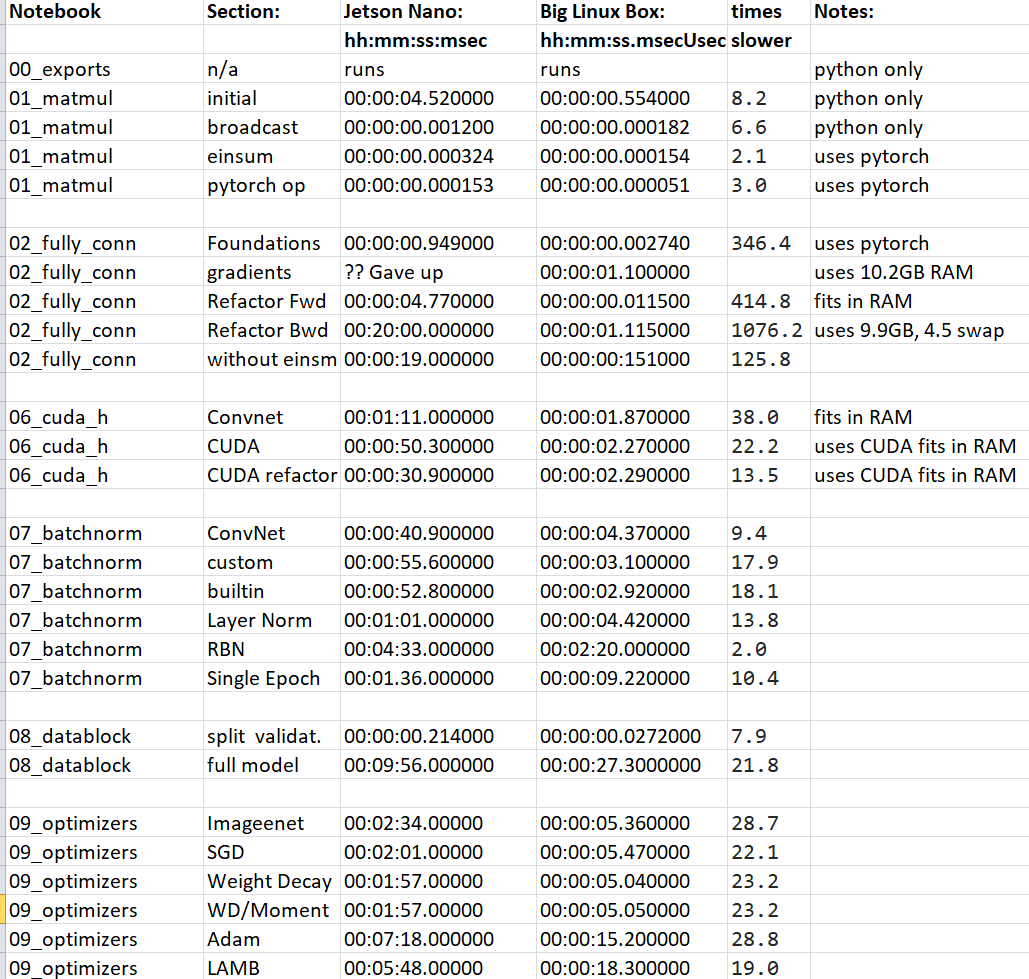
Notebook: Section Jetson Time Big linux box time: Notes:
00_exports N/A Runs Runs uses only python
01_matmul initial 4.52 sec 554ms python only
01_matmul broadcasting 1.2ms 182us python only
01_matmul Einsum 324us 154us uses pytorch
01_matmul pytorch op 153us 50.7us uses pytorch
02_fully_conn Foundations 949ms 2.74ms uses pytorch
02_fully_conn Gradients ?? gave up 1.1sec uses (10.2GB), 5.7GB of swap space (takes forever)
02_fully_conn Refactor fwd 4.77sec 11.5ms fits in RAM
02_fully_conn Refactor bwd 20mins 1.115 sec uses (9.9GB), 4.5GB of swap space
02_fully_conn Without einsum 19 sec 151msec
02_fully_conn nn.Linear 10.1 sec 1.1sec
06_cuda_cnn_h ConvNet 1min 11 sec 1.87 sec uses 1.3GB fits in RAM
06_cuda_cnn_h CUDA 50.3 sec 2.27 sec uses CUDA 2.3GB fits in RAM
06_cuda_cnn_h CUDA refactor 30.9 sec 2.29 sec uses CUDA 2.3GB fits in RAM
I was also able to run some of the other notebooks, but didn’t save the timings.
OK, it’s a lot slower, but it works!
Will this work for YOLO, Resnet50, GANS, maybe for inference, but probably not for training. But to model a small problem, quickly and for free, definitely! This is not a toy system.
OK, so it’s possible, now how do I get one?
Follow the instructions here. The only step missing is how to download the fastai_docs notebooks from git, because that post is not in this private (for now) section of the fast.ai forum.
 I know it’s a lot to ask…
I know it’s a lot to ask…