Yah I suppose so.
I’ll refactor this today and push something to the repo. (never mind, is see @sgugger already did it).
-wg
Yah I suppose so.
I’ll refactor this today and push something to the repo. (never mind, is see @sgugger already did it).
-wg
Currently, pre_trained LM weights are assumed to be located in DATA_PATH/models. The problem with this is, I need to make copies (or softlink the weight and the itos vocab) of the weights for each project I work on in that project’s directory. How about we specify a separate pre_trained_path for just loading the pre_trained weights? Would that be something that could be considered? I can submit a PR that does that.
For now, keep the simlinks. We’ll be adding more pretrained models, and as we do, we’ll come with a solution to have them centralized somewhere (and automatically downloaded if needed like pytorch does). This should come in v1.1.
Any ETA on that?
I’m beginning to port my NLP work from old fastai to the new framework, but not until we have both a forward and backwards pre-trained wiki103 at the very least.
If ya’ll need any help, let me know.
-wg
I trained a new LM on custom dataset after fine-tuning it on the pre-trained LM. Happy to say that everything worked without any problems and it was extremely easy! Kudos to the fastai team.
I have one question. Before training the model, I split my texts into 80/10/10 for train, val, test and passed all there of them to the factory function to create my data_lm. I can see from the progress outputs how the training loss, val loss, accuracy indicating that the training and val datasets have been use. I’m not sure how to use the test data sets after I created, trained and saved the model.
In other words, how would I “test” this LM. Please note that I intend to use this on another task (regression instead of classification) so that would serve as a good test. But I was wondering how to use the test set that I passed to the factory method.
Thank you
You should use learn.get_preds(is_valid=False) to get your predictions on the test test.
I’m glad you like it so far 
That method throws an error saying get_preds does not exist:
learn.get_preds
AttributeError Traceback (most recent call last)
in
----> 1 learn.get_preds
AttributeError: ‘RNNLearner’ object has no attribute ‘get_preds’
Ah yes, that’s because we removed the tta import from there I guess. Try from fastai.tta import * and tell me if this works, will fix in function of what you report.
I did as per your instructions and ran into the following error:
TypeError Traceback (most recent call last)
in
----> 1 learn.get_preds(is_valid=False)
TypeError: _learn_get_preds() got an unexpected keyword argument ‘is_valid’
Since is_valid doesn’t seem to be there, it tried learn.get_preds(is_test=True) and that threw up the following error:
AttributeError Traceback (most recent call last)
in
----> 1 learn.get_preds(is_test=True)
~/fastai/fastai/tta.py in _learn_get_preds(learn, is_test)
18 def _learn_get_preds(learn:Learner, is_test:bool=False) -> List[Tensor]:
19 “Wrapper of get_preds for learner”
—> 20 return get_preds(learn.model, learn.data.holdout(is_test))
21 Learner.get_preds = _learn_get_preds
22
~/fastai/fastai/tta.py in get_preds(model, dl, pbar)
14 def get_preds(model:Model, dl:DataLoader, pbar:Optional[PBar]=None) -> List[Tensor]:
15 “Predicts the output of the elements in the dataloader”
—> 16 return [torch.cat(o).cpu() for o in validate(model, dl, pbar=pbar)]
17
18 def _learn_get_preds(learn:Learner, is_test:bool=False) -> List[Tensor]:
~/fastai/fastai/basic_train.py in validate(model, dl, loss_fn, metrics, cb_handler, pbar)
40 with torch.no_grad():
41 return zip(*[loss_batch(model, xb, yb, loss_fn, cb_handler=cb_handler, metrics=metrics)
—> 42 for xb,yb in progress_bar(dl, parent=pbar, leave=(pbar is not None))])
43
44 def train_epoch(model:Model, dl:DataLoader, opt:optim.Optimizer, loss_func:LossFunction)->None:
~/fastai/fastai/basic_train.py in (.0)
40 with torch.no_grad():
41 return zip(*[loss_batch(model, xb, yb, loss_fn, cb_handler=cb_handler, metrics=metrics)
—> 42 for xb,yb in progress_bar(dl, parent=pbar, leave=(pbar is not None))])
43
44 def train_epoch(model:Model, dl:DataLoader, opt:optim.Optimizer, loss_func:LossFunction)->None:
~/fastai/fastai/basic_train.py in loss_batch(model, xb, yb, loss_fn, opt, cb_handler, metrics)
18 out = model(*xb)
19 out = cb_handler.on_loss_begin(out)
—> 20 if not loss_fn: return out.detach(),yb[0].detach()
21 loss = loss_fn(out, *yb)
22 mets = [f(out,*yb).detach().cpu() for f in metrics] if metrics is not None else []
AttributeError: ‘tuple’ object has no attribute ‘detach’
A question about loading saved model: After I finish my run I save my model as so learn.save('name') and then shutdown the kernel and then in a new kernel load it up again learn.load('name') (after creating new instances of data_lm and ‘learn’ ). Can the recorder and associated metrics/plots be accessed again? Or are they only available after training? Because when I tried to plot (after loading up the saved weights) I get the following error:
AttributeError Traceback (most recent call last)
in
----> 1 learn.recorder.plot_losses()
AttributeError: ‘RNNLearner’ object has no attribute ‘recorder’
Thank you.
Yes the argument is is_test, sorry about that. And it won’t work for an RNN because the output is a tuple and not a tensor, and the callbacks to handle that aren’t called there, so you kind of have to write your own loop.
As for the recorder, it isn’t saved with the model, so it stays as long as you keep your learn object around, but if you restart your notebook, it will have disappeared, yes.
Hi, since I am beginner here, I would like also know how to do the prediction. In Scikit-learn or Keras, there are very simple and intuitive functions to train and make prediction:
How about it here? is there any similar way to do it? from my experience trying ULMFit, this is not clear and easy as I had using other frameworks. Thanks.
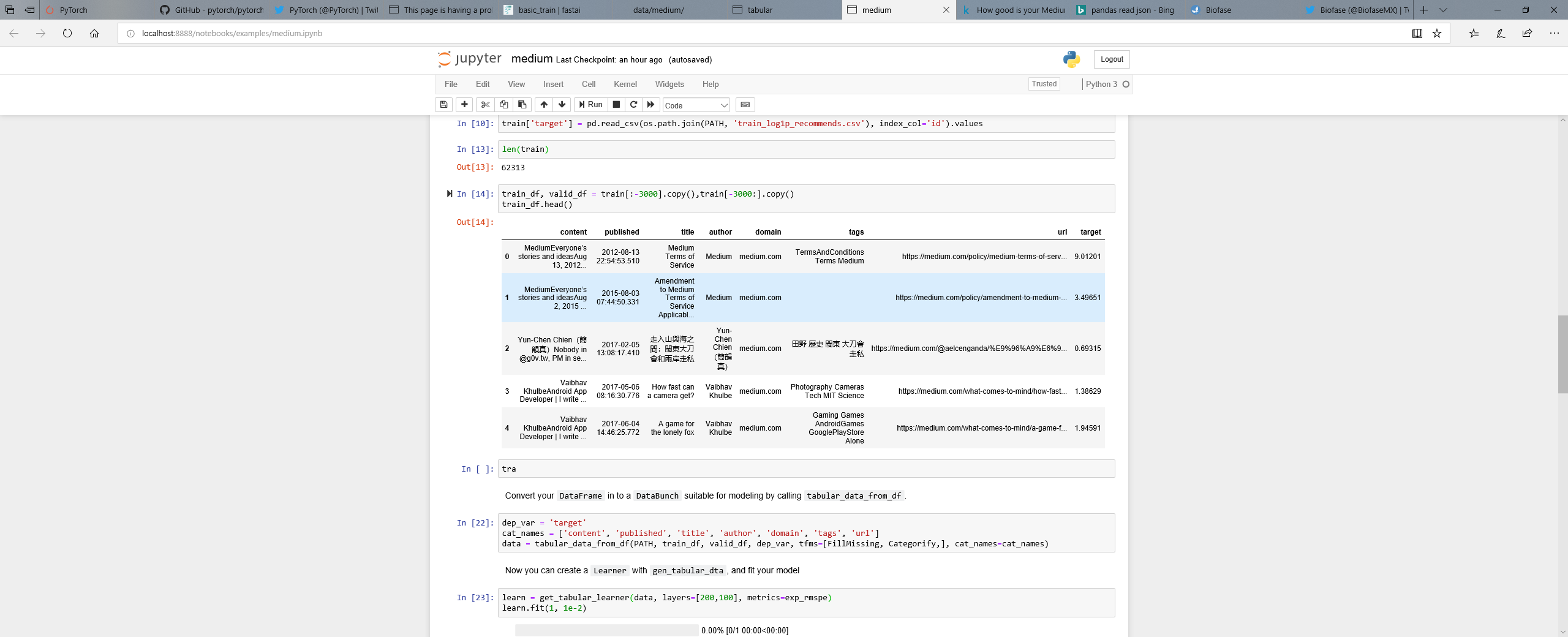
I have something like this
When I’m running
learn = get_tabular_learner(data, layers=[200,100], metrics=exp_rmspe)
learn.fit(1, 1e-2)
BrokenPipeError Traceback (most recent call last)
in ()
1 learn = get_tabular_learner(data, layers=[200,100], metrics=exp_rmspe)
----> 2 learn.fit(1, 1e-2)
c:\users\gerar\fastai\fastai\basic_train.py in fit(self, epochs, lr, wd, callbacks)
132 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
133 fit(epochs, self.model, self.loss_fn, opt=self.opt, data=self.data, metrics=self.metrics,
–> 134 callbacks=self.callbacks+callbacks)
135
136 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
c:\users\gerar\fastai\fastai\basic_train.py in fit(epochs, model, loss_fn, opt, data, callbacks, metrics)
85 except Exception as e:
86 exception = e
—> 87 raise e
88 finally: cb_handler.on_train_end(exception)
89
c:\users\gerar\fastai\fastai\basic_train.py in fit(epochs, model, loss_fn, opt, data, callbacks, metrics)
69 cb_handler.on_epoch_begin()
70
—> 71 for xb,yb in progress_bar(data.train_dl, parent=pbar):
72 xb, yb = cb_handler.on_batch_begin(xb, yb)
73 loss,_ = loss_batch(model, xb, yb, loss_fn, opt, cb_handler)
~\Anaconda3\lib\site-packages\fastprogress\fastprogress.py in iter(self)
59 self.update(0)
60 try:
—> 61 for i,o in enumerate(self._gen):
62 yield o
63 if self.auto_update: self.update(i+1)
c:\users\gerar\fastai\fastai\data.py in iter(self)
45 def iter(self):
46 “Process and returns items from DataLoader.”
—> 47 self.gen = map(self.proc_batch, self.dl)
48 return iter(self.gen)
49
~\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py in iter(self)
499
500 def iter(self):
–> 501 return _DataLoaderIter(self)
502
503 def len(self):
~\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py in init(self, loader)
287 for w in self.workers:
288 w.daemon = True # ensure that the worker exits on process exit
–> 289 w.start()
290
291 _update_worker_pids(id(self), tuple(w.pid for w in self.workers))
~\Anaconda3\lib\multiprocessing\process.py in start(self)
110 ‘daemonic processes are not allowed to have children’
111 _cleanup()
–> 112 self._popen = self._Popen(self)
113 self._sentinel = self._popen.sentinel
114 # Avoid a refcycle if the target function holds an indirect
~\Anaconda3\lib\multiprocessing\context.py in _Popen(process_obj)
221 @staticmethod
222 def _Popen(process_obj):
–> 223 return _default_context.get_context().Process._Popen(process_obj)
224
225 class DefaultContext(BaseContext):
~\Anaconda3\lib\multiprocessing\context.py in _Popen(process_obj)
320 def _Popen(process_obj):
321 from .popen_spawn_win32 import Popen
–> 322 return Popen(process_obj)
323
324 class SpawnContext(BaseContext):
~\Anaconda3\lib\multiprocessing\popen_spawn_win32.py in init(self, process_obj)
63 try:
64 reduction.dump(prep_data, to_child)
—> 65 reduction.dump(process_obj, to_child)
66 finally:
67 set_spawning_popen(None)
~\Anaconda3\lib\multiprocessing\reduction.py in dump(obj, file, protocol)
58 def dump(obj, file, protocol=None):
59 ‘’‘Replacement for pickle.dump() using ForkingPickler.’’’
—> 60 ForkingPickler(file, protocol).dump(obj)
61
62 #
BrokenPipeError: [Errno 32] Broken pipe
pytorch 0.4.1
Windows 10 Pro
Neither of these are supported. Please see the readme.
I will fix both tonight
If I have a JSON with fields (categorical, contiguous) and text and I manage to load them in a data frame
Can I still use the tabular_data_from_df?
What is the best way to include the text in the embedding?
Should I just include it as an additional category?
I’m talking about a hybrid model (images, text, columns)
Maybe fields and a photo with description.
Note that there has been a big change in the API to get your data (arguments are more or less the same, it’s just the name to call you have to adapt).
See here for all the details, examples and docs are updated.
I have a CSV with a single column which contains an article on each row. I do not have any labels associated with them since I would like to create a language model. When I run
data_lm = TextLMDataBunch.from_csv(PATH, bs=bs)
I get the following error:
~/.local/lib/python3.6/site-packages/fastai/text/data.py in tokenize(self)
87 df = next(dfs) if (type(dfs) == pd.io.parsers.TextFileReader) else self.df
88 lbl_type = np.float32 if len(self.label_cols) > 1 else np.int64
---> 89 lbls = df[self.label_cols].values.astype(lbl_type) if (len(self.label_cols) > 0) else []
90 self.txt_cols = ifnone(self.txt_cols, list(range(len(self.label_cols),len(df.columns))))
91 texts = f'{FLD} {1} ' + df[self.txt_cols[0]].astype(str)
ValueError: invalid literal for int() with base 10: '...'
Do we still need label columns while we are trying to instantiate TextLMDataBunch? According to the documentation, it sounds like we do but it’s a bit confusing.
I ended up setting n_labels=0. This let the DataBunch to be created successfully but when I run
learn.fit_one_cycle(4, 1e-2)
I get the following error:
ValueError: Target size (torch.Size([1024])) must be the same as input size (torch.Size([1024, 60002]))
Seems like I’m missing something. Could you help me understand the API? Should I be creating a dummy label column in my input CSV?
I guess this is the necessary step!
Let us now if it worked out.
Best regards
Michael
Just add a column of zeros. You can do it many ways. Either load it into a dataframe in pandas and add a column of zeros. Or you can just do it in the terminal. If you google for how to add column to csv you might get some useful results. Its just a dummy columns that serves no purpose for the language model other than to maintain a consistent API.
I see. If this is the necessary step to keep the API consistent, I think it should be spelled out more explicitly in the documentation. My expectation was TextLMDataBunch.from_csv function would do that for me automatically.
Important change! I’ve just updated the API to be more torchvision-like so when you want to use the fastai pretrained model, you should now use:
learn = RNNLearner.language_model(data_lm, pretrained_model=URLs.WT103)
It will download the model for you in the .fastai/models/ folders the first time you use it (so it’s at one place once and for all and you don’t have to download it in all your projects) then load it. You can still use the old pretrained_fnames=[{weights_fname},{itos_fname}] if you train your own model locally.
Example is properly updated, docs will follow soon.