It’s been a while since there was a new article here. We still have to do a big edit on the transforms/data augmentation but in the meantime, here is a bit of NLP. I’ll cover two things today: the AWD-LSTM from Stephen Merity (which is our basic LM in fastai) and the pre-processing of texts in general.
AWD-LSTM
As it was the case with fastai, the basic Language Model in fastai_v1 will be the AWD-LSTM from Stephen Merity. There has been a lot of talking about the Transformer model, and we’ll probably propose it as an alternative later on, but the date where the library needs to be ready is near so we decided to focus on something we know well for now. All the new implementation is in notebook 007.
A language model is a model who is tasked to predict what the next word is in a sentence, given all the previous ones. They often use a Recurrent Neural Network which has the particularity of having a hidden state. Each time we feed a new word inside the model, the hidden stage is updated, but since it’s never reinitialized, it keeps track of everything that was said in the sentence, giving the model the aptitude to remember things (in a way).
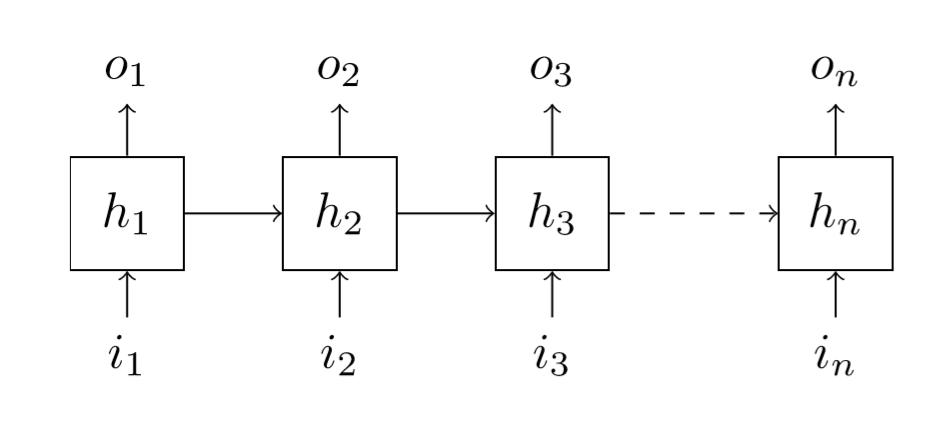
This gives us a constraint compared to traditional Computer Vision: we can’t shuffle the batches during training, we have to give them in the right order otherwise it will mess up those hidden states. Sadly, the GPU memory is constrained, so we need to reset the gradients after a certain amount of words is passed otherwise we’ll raise the traditional CUDA out of memory error. The number of words for which we keep the gradients is called bptt for backpropagation through time. It’s usually a fixed number, but the first genius idea of the article is to have it slightly modified at each batch (randomly), so that when we run another epoch, the model isn’t fed exactly the same sequences of words in the same order.
The second main idea of the article is to put dropout everywhere. Really everywhere, but in an intelligent way. There is a difference with the usual dropout, which is why you’ll see a RNNDropout module inside notebook 007: we zeros thing, as is usual in dropout, but we always zero the same thing according to the sequence dimension (which is the first dimension in pytorch). This ensures consistency when updating the hidden state through the whole sentences/articles. If we unroll our input like in the picture up there, it means we zero the same coordinates inside i1, i2…
This being given, there are five different dropouts:
- the first one, embedding dropout, is applied when we look the ids of our tokens inside the embedding matrix (to transform them from numbers to a vector of float). We zero some lines of it, so random ids are sent to a vector of zeros instead of being sent to their embedding vector.
- the second one, input dropout, is applied to the result of the embedding with dropout. We forget random pieces of the embedding matrix (but as stated in the last paragraph, the same ones in the sequence dimension).
- the third one is the weight dropout. It’s the trickiest to implement as we randomly replace by 0s some weights of the hidden-to-hidden matrix inside the RNN: this needs to be done in a way that ensure the gradients are still computed and the initial weights still updated.
- the fourth one is the hidden dropout. It’s applied to the output of one of the layers of the RNN before it’s used as input of the next layer (again same coordinates are zeroed in the sequence dimension). This one isn’t applied to the last output, but rather…
- the fifth one is the output dropout, it’s applied to the last output of the model (and like the others, it’s applied the same way through the first dimension).
Lastly, we have an additional regularization called AR (for Activation Regularization) and TAR (for Temporal Activation Regularization). They look a bit like weight decay, which can be seen as adding to the loss a scaled factor of the sum of the weights squared.
- for AR, we add to the loss a scaled factor of the sum of all the squares of the ouputs (with dropout applied) of the various layers of the RNN. Weight decay tries to get the network to learn small weights, this is to get the model to learn to produce smaller activations (intuitively)
- for TAR, we add to the loss a scaled factor of the sum of the squares of the h_(t+1) - h_t, where h_i is the output (before dropout is applied) of one layer of the RNN at the time step i (word i of the sentence). This will encourage the model to produce activations that don’t vary too fast.
Those are implemented in the callback RNNTrainer (previously in fastai it was the seq2seq_reg function).
Text preprocessing
This is covered in notebook 007a. The basic idea is to make it super easy for the end user and do all the necessary stuff inside the text dataset. This led to the class TextDataset, which can define such a dataset from multiple ways (folders with a train, valid structure, csv file, tokens, ids). It takes a tokenizer if you define it at a level below token and will create (or use if you pass it) the vocab that will convert such tokens to ids.
The tokenizer is wrapped in the Tokenizer class. This on takes a tokenizer function (like a spacy tokenizer), a language, and a set of rules such as remove multiple spaces or replace all caps word by TOK_UP then the word without caps. Special tokens of the fastai_v1 library all begin by xx, so we have xxbos, xxeos, xxpad, xxunk…
If you remember the imdb notebook, you know that tokenizing can take quite a bit of time, so the TextDataset class creates a folder where it stores all the computed arrays (tokens, then ids) so that it doesn’t recalculate them next time you go through the notebook (unless you’ve changed something). All in all, the goal is to have something that is as easy to use as the ImageData in old fastai.