I’m getting somewhere - pulling the label was easy, now need to work out how to get the values from the confidences and maybe chart them.

Edit - more details and code in Share your work
I’m getting somewhere - pulling the label was easy, now need to work out how to get the values from the confidences and maybe chart them.
Edit - more details and code in Share your work
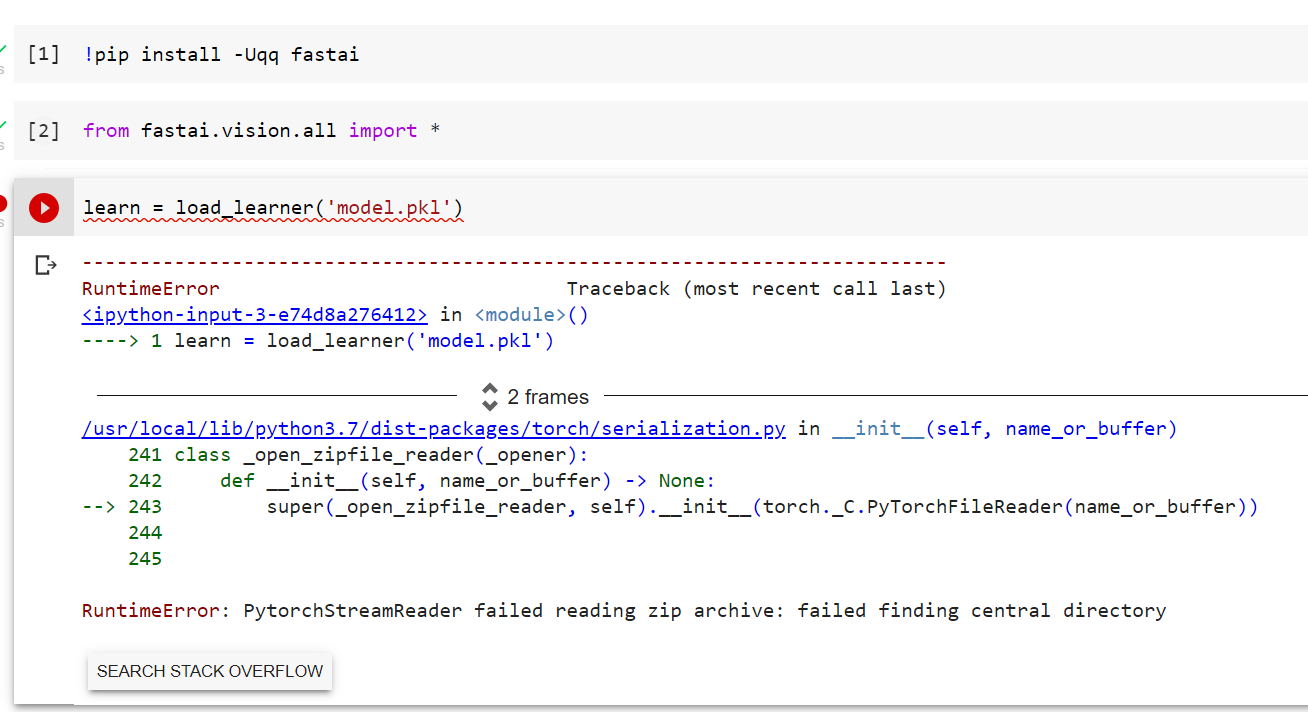
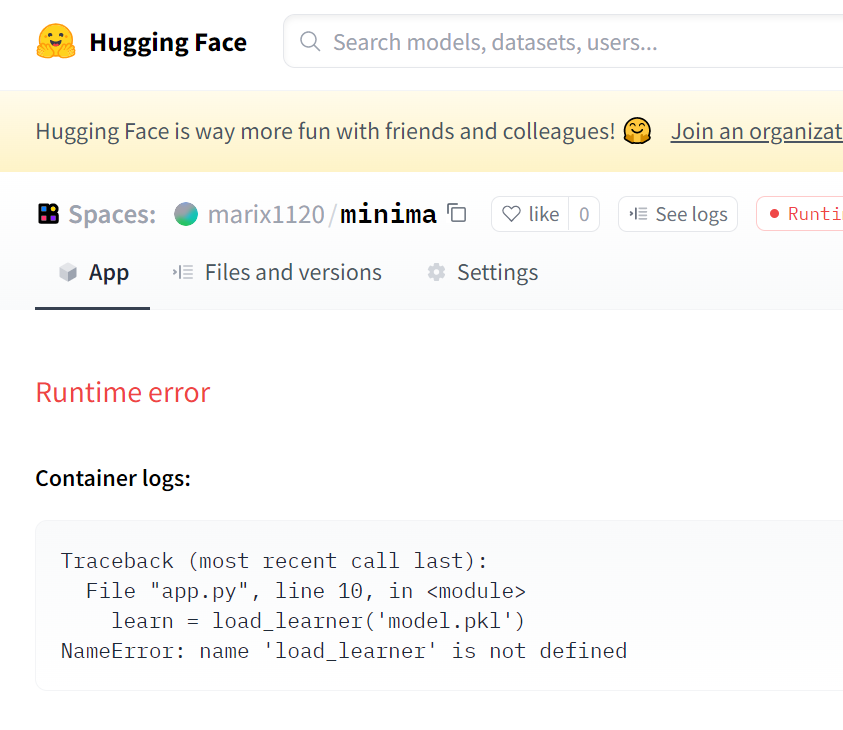
Hi. I am trying to load my model to create app.py file but getting this error message. How can I fix it?
The huggingface is also returning similar message where load_learner is not defined. What am I missing on my app.py file?
Thank you!
My bad - I forgot to mention you need to also add a file called “requirements.txt” which lists the python packages you need, one per line. In your case, it should just contain a single line containing:
fastai
Thanks Jeremy. It is still having the same error. For the requirements.txt to be referred, do I need to mention something in the app.py file?
Thanks,
If you’re not familiar with git, you don’t have to use it. Create your app.py file in whatever editor you prefer (e.g vscode), then go to your space on Spaces - Hugging Face, click “files and versions”, then “add file” (in the top right), and upload your file there.
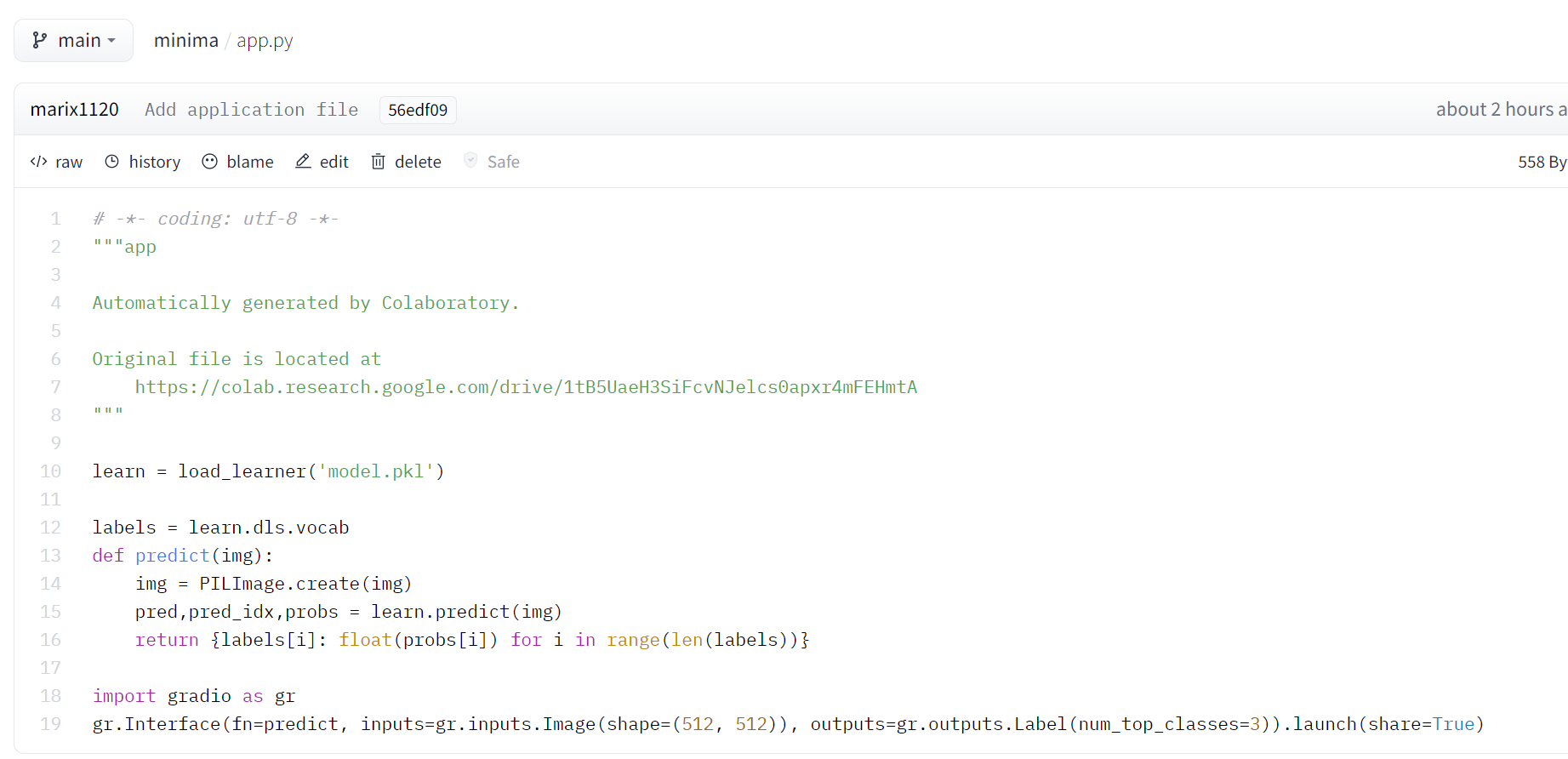
Yes it looks like you’re missing the import statement. I’d suggest starting with a known-working point and edit from there:
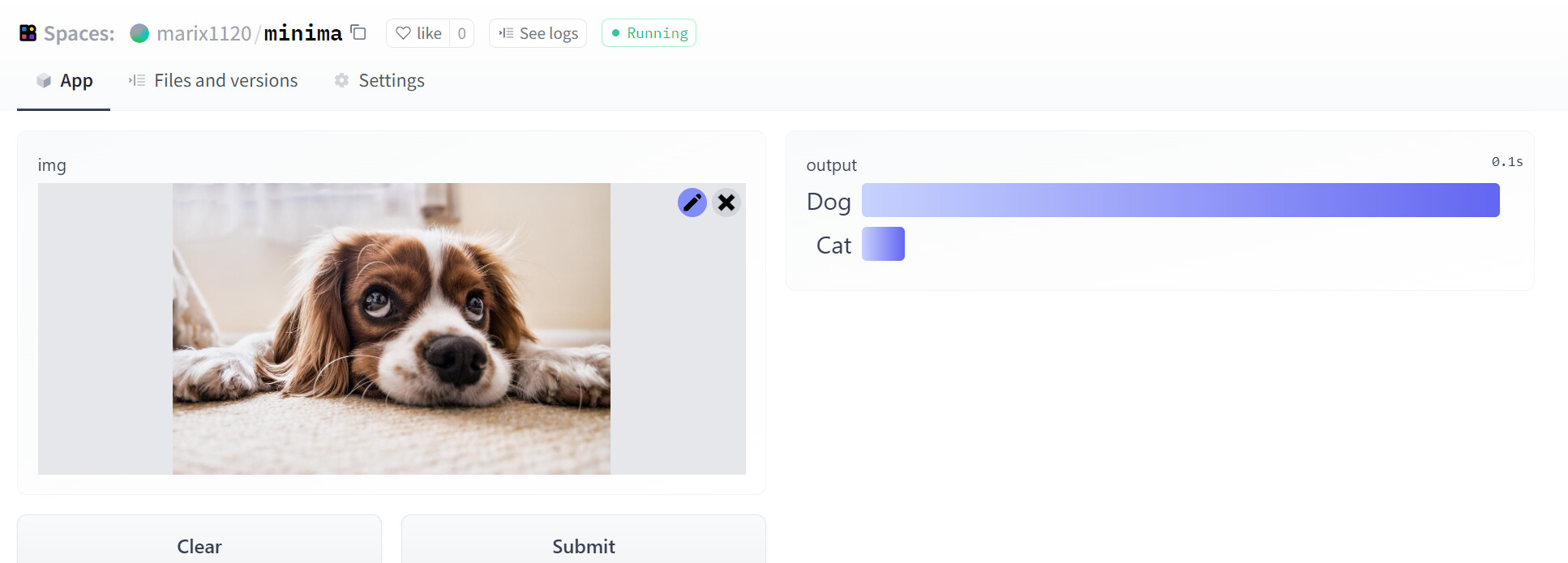
omg that’s such an adorable photo!
Hi everyone,
I’m trying to use my own dataset for a fun little project: trying to classify between two categories (exactly like in lesson 1: Forest vs Bird). I uploaded a dataset and created a Path object for that dataset. When I’m trying to run the dls line (feed the input to the model), I’m getting the following error: “TypeError: ‘NoneType’ object is not iterable”. I’m not sure if I created the Path object properly, given that it’s the input folder in Kaggle and not the output. Has anyone had similar issues with using your own datasets?
Thanks.
Unfortunately, there’s very little to go on here, but I can relate to you that I used my own searches on duck-duck-go to create my data set, and it seemed to work fine on Kaggle. Now, if I had my own custom data set, then what I would check is to see that the way the birds/forest data is stored (by the original notebook), is also the way that my own custom data is stored (equivalent paths, foldernames etc.) because the notebook has some built in assumptions about locations and names etc.
Good luck with your project!
Hi Mike, sorry for posting my questions not clearly.
Unlike the notebook from the first lesson, I skipped the part of using the search engine and storing the photos under the Output section (kaggle/working/…) and just uploaded my own dataset and now it shows up in the input section, and so I created a Path object of my dataset name (same as the folder name) in hopes that I could reuse the rest of the code using the new Path object. I guess I’m not sure whether the Input part (where my current data is stored) can be treated the same as the Output section on Kaggle when creating the Path objects.
It would help to share a public link to your code.
No worries @zymoide1 , thanks for expanding on it. I’m a beginner myself, so I can only offer a beginner type suggestion which is something I would do, and that would be to just move the data under the kaggle/working/output folder etc., and make the file/directory structure look as much like as the original notebook and see what the next error might be?
Having said that, I don’t see why having your dataset under /input would be any different than having it at any other location as long as the structure can be dealt with by the underlying assumptions of the code being used.
HTH
Thanks, everyone. I was able to copy the input folder to the output one via the following code I found in the kaggle forum
from distutils.dir_util import copy_tree
f= '../input'
t='temp'
copy_tree(f,t)
Dealing with the input folder is annoying. ![]()
As an example, I used my own input dataset here…
Oh wow, that simple?
dataroot = Path('../input/watersports')
Is that data part of a dateset you’ve uploaded (and was it public or private?)
Thanks!!
Its a dataset I created with this…
I downloaded the images to my local machine to manually clean the categories (this was prior to Lesson 2), then zipped them to upload.
The dataset is meant to be public - could you check your access to it.
Hello!
I am trying to use tabular data loader and got one question. In the dataset I have emails and handles I want to analyse. Both are free text values. Sometimes email patterns used (having many numbers inside, or using specific domain), or handles (like random letters) are indication of fraudulent users. The question is where I should put it? Or I should categorise and split this data myself somehow: numbers count in the email, email subdomain, handle letters length, and only then analyse it?
Thanks!
Also, if I have a user and a list of transactions (1 to N). So there are many users and many transactions and based on those patterns, I would love to make some call. What would be a proper way to load this data?
Hi there,
I am having trouble using git push to push my code to hugginface/gradio
The first git push with the sample “hello” code works fine, but after I add my model file (“export.pkl”) to the folder and push again, I receive the following error:
Writing objects: 100% (5/5), 41.55 MiB | 287.00 KiB/s, done.
Total 5 (delta 0), reused 0 (delta 0), pack-reused 0
remote: -------------------------------------------------------------------------
remote: Your push was rejected because it contains binary files.
remote: Please use https://git-lfs.github.com/ to store binary files.
remote: See also: https://hf.co/docs/hub/repositories-getting-started#terminal
remote: -------------------------------------------------------------------------
remote: Offending files:
remote: - export.pkl (ref: refs/heads/main)
To https://huggingface.co/spaces/...
! [remote rejected] main -> main (pre-receive hook declined)
error: failed to push some refs to 'https://huggingface.co/spaces/...'
This doesn’t happen in the recorded lesson. Has anyone else received this error? Help is very much appreciated