This worked spot on when I tried the notebook shared by @shravan.koninti . Really interesting problem. Thanks for sharing solution @KevinB
2 Likes
After some iterations: I have this.
I launched the gradio app inside kaggle notebook. It throwed an error after I saved the version. "FileNotFoundError: [Errno 2] No such file or directory: ‘/opt/conda/lib/python3.7/site-packages/typing_extensions-4.2.0.dist-info/METADATA’
Here is the link for gradio app (Only applicable for 72 hours as it is not launched in HF spaces) : Flowers_Fruits_Classifier
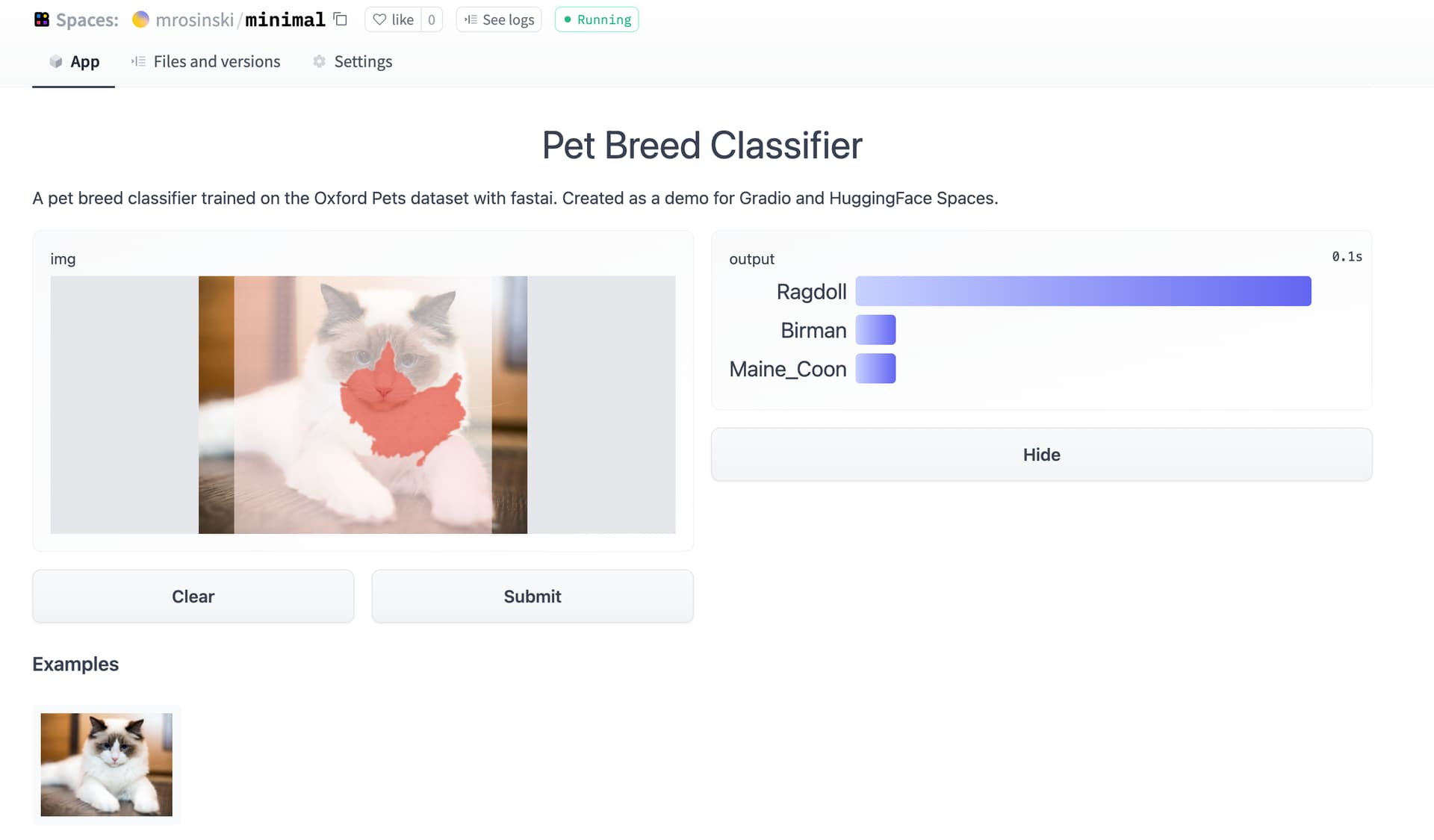
So I just trained a pet breed classifier and deployed it on Hugging Face Spaces. My biggest issue was not reading all of Tanishq’s blog post before pushing. Needed to install git-lfs and track both .pkl and .jpg files. But a previous commit that did not have tracking enabled was causing errors. I ended up having to recreate the repo because I wasn’t able to reset/fix previous commits.
It’s pretty exciting to have a way to get inference models into an app that you can so easily share with others! Here’s my Pet Breed Classifier!
7 Likes
Oh I guess its not running.
Better I deploy in HF spaces. Will get back again. thanks
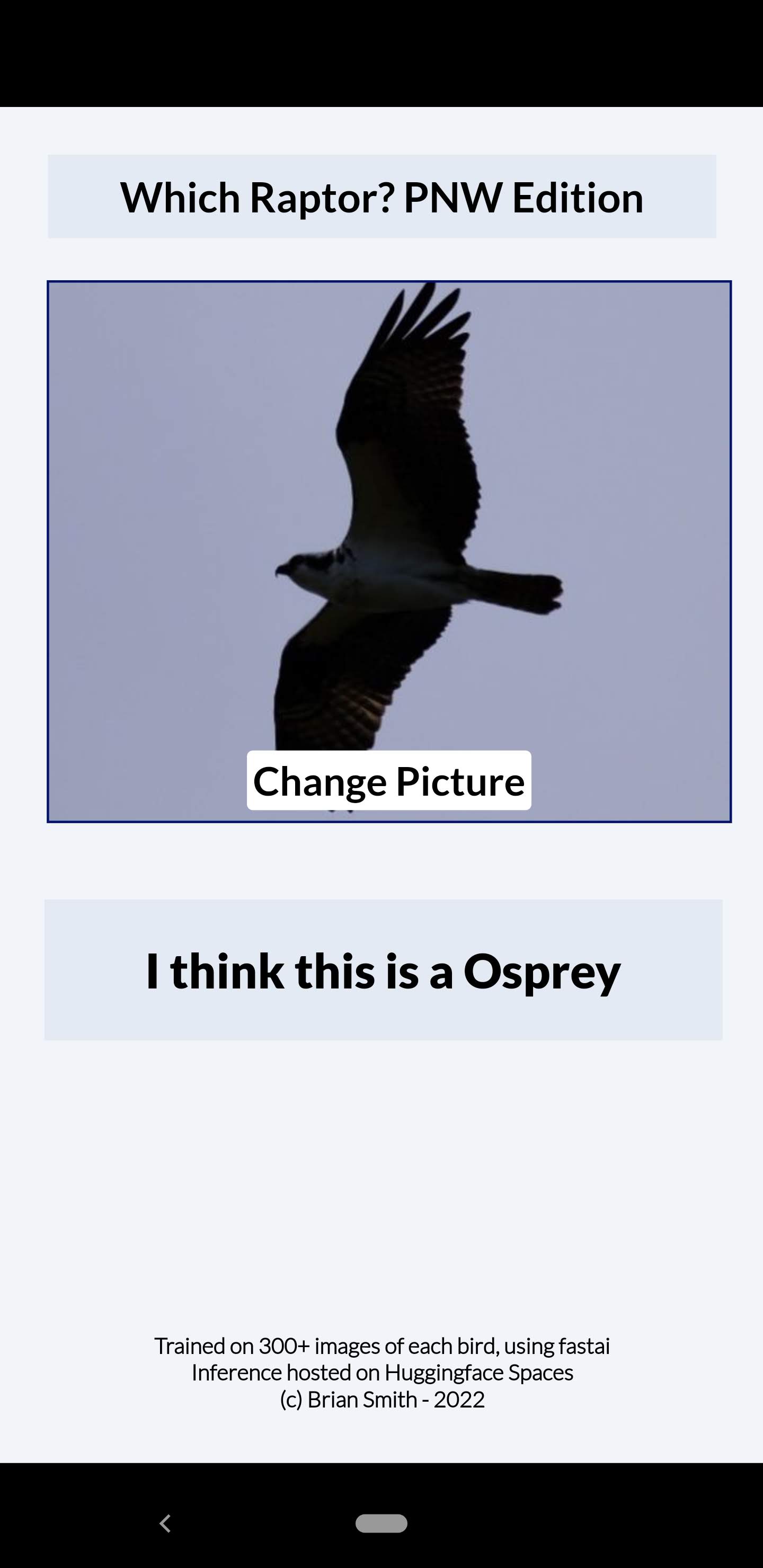
I created a Power App that sent pictures from my phone to the Huggingface API to identify from some common raptors I see on my local walks. The Power Apps solution file and swagger are shared on the Huggingface Spaces - link in the blog (Powerapps | Brian Smith’s Data Science Journey) as well as some general details of how I did it. If more detail is needed then let me know. This may be a great solution for any low-code people on the course!
12 Likes
So I decided to build on the Art Movement classifier that I shared earlier by leveraging the WikiArt Dataset - I kept the Genres that had at least 1000 photos to train on, which left 20 genres. Demo here.
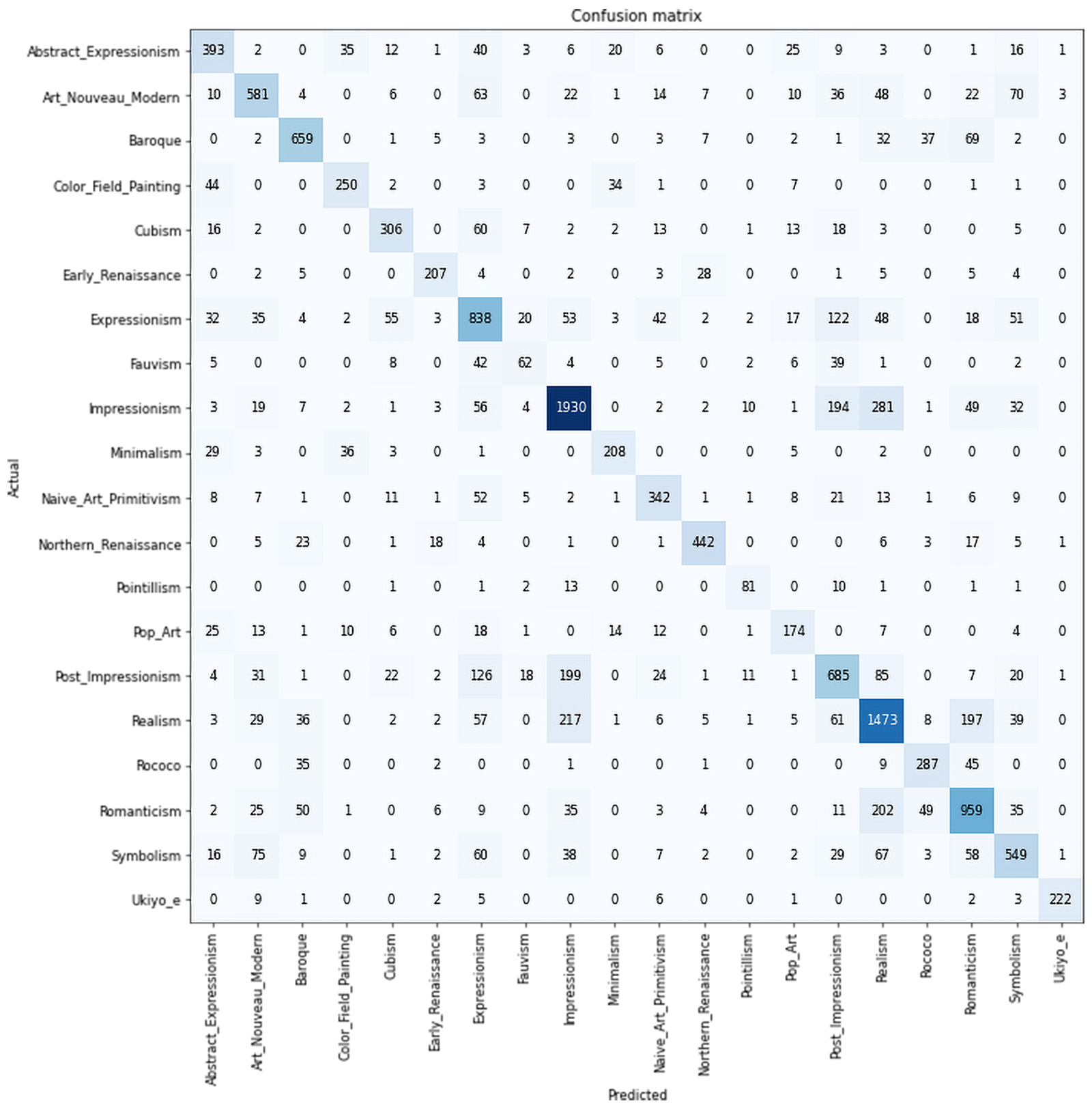
It’s interesting to look back at the first papers to do classification on this dataset - Saleh and Elgammal (2015) were getting accuracies around 50% with CNNs (training from scratch), and 58% using SVM on classeme features. Recognizing Art Style Automatically in painting with deep learning (2017) used transfer learning with a ResNet50 plus Bagging & Data Augmentation to get Top-1 accuracy of 62.5%.
Training a ResNet50 using presizing I was able to get to around 67% accuracy, and a good part of the remaining confusion between images may be coming from the blurriness of the boundaries of the art categories themselves: (E.g., Fauvism & Expressionism / Post-Impressionism, Impressionism and Post-Impressionism)
It would be really nice to be able to go a little deeper into which paintings are getting categorized to an art movement different from the WikiArt label: is there a way to output to csv the image names with predicted categories?
Training was interesting - on my RTX 2070 I was getting 14 minutes/epoch, with a batch size of 64 and using mixed-precision. On Colab with a V100 it was more like 36 minutes/epoch. I was curious what the limiting factor was, and I thought it might be CPU doing the image resizing - some images were as large as 3000x4000, and in my DataBlock item_tfms I’m resizing to 512px.
So per the fastai performance suggestions I switched out Pillow to Pillow-SIMD and libjpeg to libjpeg-turbo, and I also resized the WikiArt dataset to a largest-size resolution of 512px. This left my CPU cores no longer completely maxed out during training, and my training time was cut in half, down to about 6 min/epoch locally.
The GPU gods also blessed me on Colab with an A100, which allowed me to bump my batch size way up - epoch times were about 3min, and I was able to confirm that running with full precision didn’t improve accuracy.
I did get a 2% improvement in accuracy going from 224px to 256px in my batch_tfms size
I created a new HuggingFace Space to demo this model: and beyond the accuracy stats I’m pretty pleased with its top-3 as a reliable indicator of how much those styles are represented in the image independent of its historical association with an art movement:
Like Matisse’s "Portrait of Madame Matisse (1905) is correctly categorized as Fauvism, but also as Post-Impressionist + Expressionist, which fits:

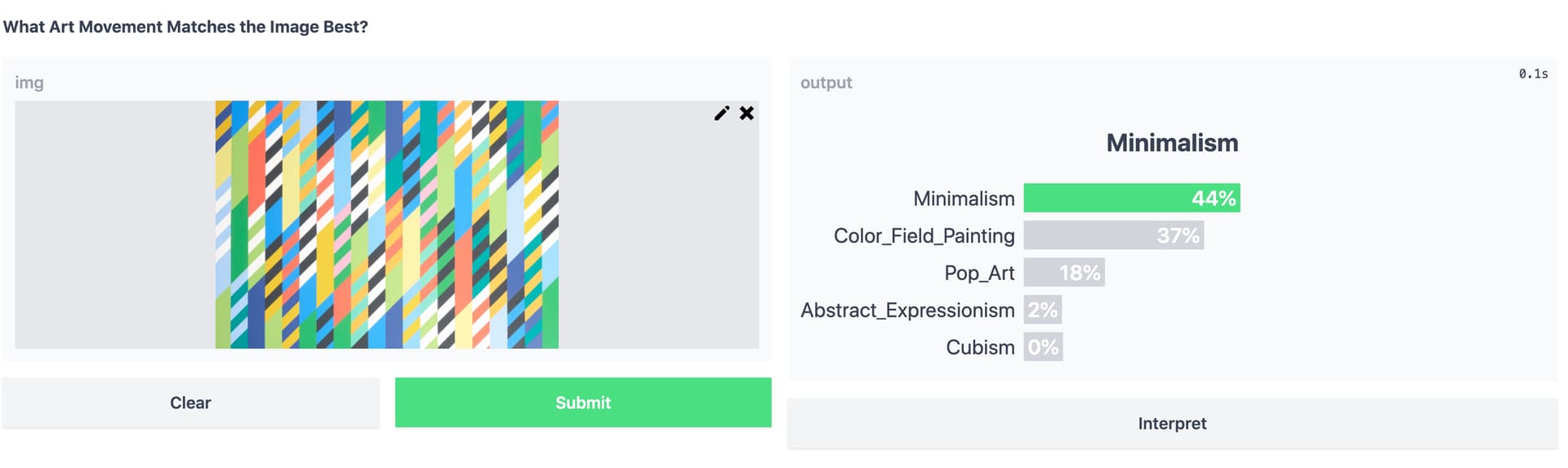
Bridget Riley’s work is prototypical Op-Art, which wasn’t included as a category in training, and for this painting I get Minimalism > Color Field > Pop-Art > Abstract Expressionism, which seems pretty reasonable to me
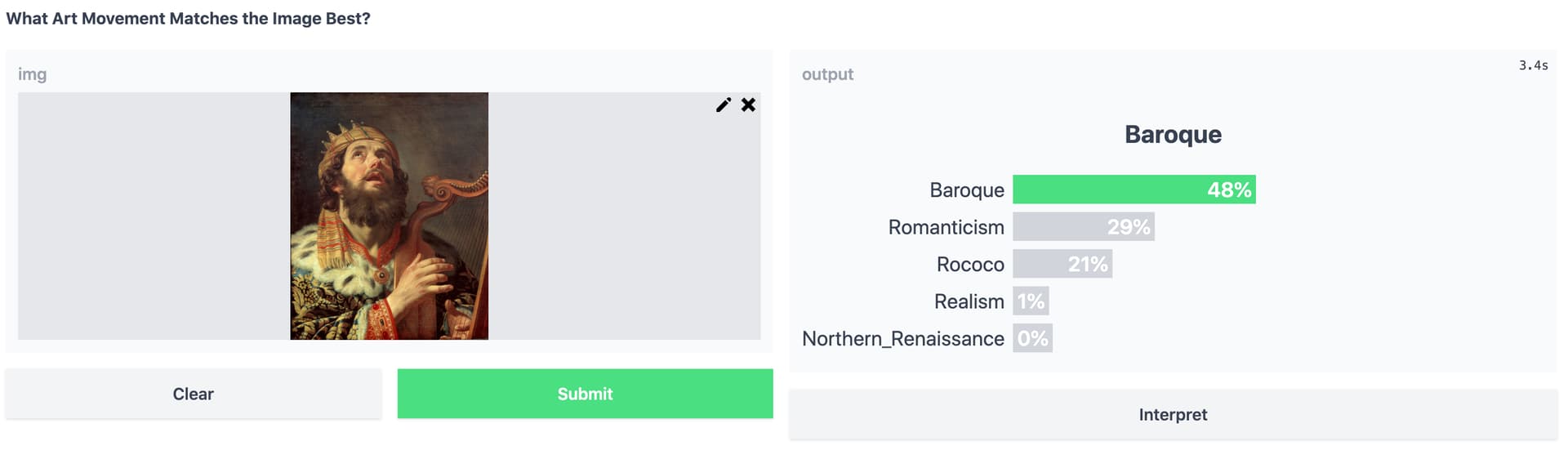
And Jan de Bray’s David Playing the Harp (1670), is Baroque / Dutch Golden Age, which is matched by the top-1, and Romanticism + Rococo as runners-up makes sense.
Going forward there’s some interesting recent work around the WikiArt dataset, like Artemis: Affective Language for Visual Art, which includes a dataset of 439K emotion attributions and explanations from humans, on these same 81K artworks from WikiArt.
They trained and demonstrated a series of captioning systems capable of expressing and explaining emotions from visual stimuli which is really cool, I’d be curious to see if I could even just use their model in a JavaScript API endpoint integration like Jeremy demoed at the end of Lecture 2 to augment my visual classifier with an emotionally descriptive caption.
If you’re familiar with BatBot’s image captioning on the EleutherAI Discord, this seems very similar but I believe BatBot uses Clip + Personality captioning. Would be very cool to combine BatBot with Artemis, and maybe some question answering or something with a LLM, will have to investigate further. Any ideas or suggestions are super welcome!
25 Likes
Brilliant stuff ! We can clearly see that you’ve enjoyed building this classifier. Thank you for sharing the details and also telling us a bit more about different art styles. 
While we’re at it, I also have some questions around some of the things you’ve raised/mentioned. Perhaps people with more experience in the current fastai library can clarify / talk more about it, and/or provide pointers to documentation/blogs etc.
I’ve been in a similar situation working on a project this week (dataset: 1024x1024px). I first thought that it would probably make sense to pre-resize images, so that the training loop could “feed the GPU” faster. But then, I thought of using the RandomResizedCrop augmentation, which would introduce more variation to the training process. As far as I understand, this is done in-memory on CPU per item (aug_transforms). Am I correct in understanding that there would be no real alternative to pre-compute this step ? (the equivalent pre-sizing technique using up a lot of disk space to create more randomly-resized-and-cropped training data, and still it wouldn’t really cover the possibilities of on-the-fly every-time randomisation.)
I also would like to experiment with this and understand this better. Right now, I used the RandomResizedCrop to 512px to get better results than 224px, the number being somewhat arbritary. Is there a good post/article that talks about how resizing affects the training process, mostly in terms of model performance(in terms of loss/metrics), perhaps also providing general hints on how to go about resizing when starting out with a baseline all the way to fine-tuning ?
It’s been a while since I’ve used the lib, so I’m just trying to figure out these details that might seem obvious to the “actively been using fastai” people here. Cheers and thanks in advance ! 
4 Likes
Wow! amazing work! and thanks for sharing! I really enjoyed playing around with the HF space and top three really do seem to get the jist of the piece.
While playing around with this, I had the idea that using something like this, it might even be possible to separate out the fakes from originals for a given artist?
1 Like
4 Likes
FYI: I’m refactoring my “Is it a Marvel Character” image regression model one session at a time, making sure to note from what lesson each refactoring comes from.
Why am I doing this?
As we are introduced to new ways of improving our models each week, it can be confusing remembering where we learned about each of them. When you want to dive deeper into one of these improvements and revisit the particular lesson where it is covered, frankly, it can be difficult to find out where that was. I’m hoping to remedy some of this by releasing new versions of my Kaggle notebook and indicating the lesson from which each change derives.
Anyways, hopefully this will be of value to some folks (it is for me at least).
Just added the bits learned from session 2 with a twist: Showing you how to clean up data used in a regression task (rather than the multiclassification task discussed in session 1)
 Notebook: Is it a Marvel Character? | Kaggle
Notebook: Is it a Marvel Character? | Kaggle
 HF Space: Is it a Marvel Character? - a Hugging Face Space by wgpubs
HF Space: Is it a Marvel Character? - a Hugging Face Space by wgpubs
Btw, this is the last time I spam this post in the forums. If you want to follow, follow … if not, no worries 
8 Likes
This stimulates a naive idea to simply the process.
A function RandomResizedCropToMatchGPU() might be useful. This would use the GPU memory size to determine optimal crop-size to maximally use the GPU, maybe even adjust dynamically if needed. Downside may be varying results depending on where code runs.
1 Like
This week (post lesson 2) I created a few deployed MVP demos showcasing things I’ve learned so far, uploading them to the Huggingface Hub and using a Gradio Demo hosted on Huggingface Spaces.
I first created a ‘Space’ showcasing a simple classification app, got it running on Spaces (here) and then used the inference API to adapt one of the Github Pages examples (here). (Thanks to @nuvic for the base example and thanks to @ilovescience for the HF/Gradio blog tutorial… both super useful!)
I then decided to think a bit bigger and made a HF Spaces MVP application that showcases two models.
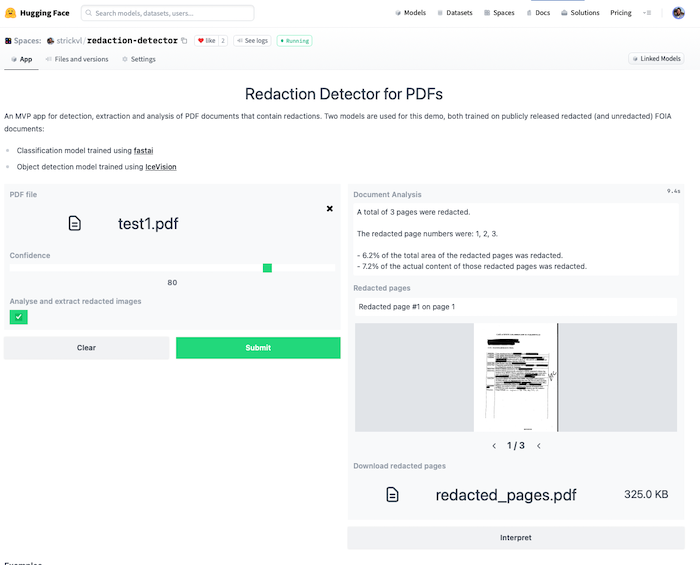
This MVP app runs two models to mimic the experience of what a final deployed version of the project might look like.
- The first model (a classification model trained with fastai, available on the Huggingface Hub here and testable as a standalone demo here), classifies and determines which pages of the PDF are redacted. I’ve written about how I trained this model here.
- The second model (an object detection model trained using IceVision (itself built partly on top of fastai)) detects which parts of the image are redacted. This is a model I’ve been working on for a while and I described my process in a series of blog posts.
This MVP app does several things:
- it extracts any pages it considers to contain redactions and displays that subset as an image carousel. It also displays some text alerting you to which specific pages were redacted.
- if you click the “Analyse and extract redacted images” checkbox, it will:
- pass the pages it considered redacted through the object detection model
- calculate what proportion of the total area of the image was redacted as well as what proportion of the actual content (i.e. excluding margins etc where there is no content)
- create a PDF that you can download that contains only the redacted images, with an overlay of the redactions that it was able to identify along with the confidence score for each item.
I was — and continue to be — surprised that the free Huggingface Spaces environment has no problem running all this fairly compute-intensive inference on their backend. (That said, if you try to upload a document containing dozens or hundreds of pages and you’ll quickly hit up against the edge of what they allow.)
Full blog writeup of the process / the context around the app / use case is here.
(UPDATE: I added in my efforts to convert my Gradio app to a Streamlit app (see the blogpost) and some of the tradeoffs I discovered along the way.)
16 Likes
Very cool. I love sharing writeups like this on twitter - do you have a tweet about it you could link to here, so I can retweet it?
1 Like
Yep I’ll share that on Monday. Still reflecting on whether I did the best job writing it up. I’ll tag fastai so you see it.
Best is to tag me - I don’t check the fastdotai account often.
1 Like
Fantastic job, Alex, and great writeup! Next challenge for you: predict the text inside those redacted boxes
4 Likes
Brilliant stuff ! 
1 Like
Well… we do have a considerable number of paired documents where we have the redacted version that was later released in a completely unredacted form. Unfortunately for the most part the things that get redacted are, I’d say, fairly unpredictable – names or email addresses or phone numbers etc. The thing that I can thing would make sense to create would be something that predicts the kind of the thing that has been redacted. I.e. is it just a name that’s been redacted, or is it something else. That would be a challenging next step for the project, esp if the idea would be for it to generalise.
4 Likes
Well, I was just kidding assuming it would be nearly impossible, but those next steps you mention sound like a reasonable (and demanding) challenge!
2 Likes