Have you followed the hints/instructions it gives there to install git-lfs?
The other option is to upload the binary files through the web interface on your app’s huggingface spaces page.
Go to the ‘files and versions tab’ and click the ‘add file’ button and then select ‘upload files’ option.
I am new to the forums and also to fastai. I was going through the text classifier tutorial and found it to be very interesting, considering this I would like to build a classifier on my own data. Can someone please guide me to the documentation or tutorial where I can understand the format of the dataset that is required to train the text classifier so that I can convert my own data in a required format.
It would be very helpful, looking forward to learn a lot from this community.
The data follows an ImageNet-style organization, in the train folder, we have two subfolders, pos and neg (for positive reviews and negative reviews)
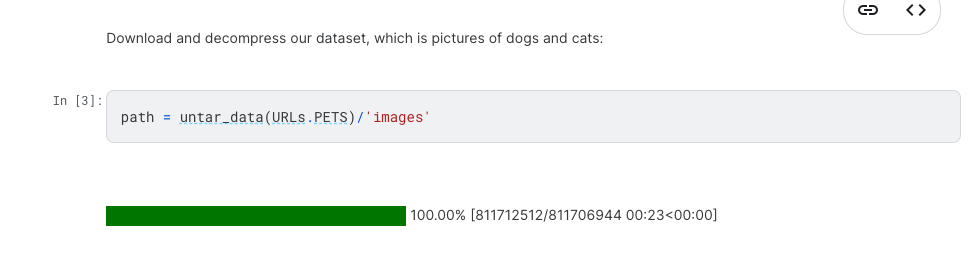
You can create a new dataset by following the same format, to get a better look at the structure for the dataset, take a look in the directory path where the dataset is downloaded.
path = untar_data(URLs.IMDB)
path.ls()
At its simplest, the structure for this dataset is just a dataset name folder which contains a train and test directory, which contain a ‘neg’ and ‘pos’ directory (the categories), and inside those go plain text files that contain the example text (e.g ‘Great movie. I was laughing all time through’)
and saved with a unique filename. It looks like this.
Hi, I am currently following lesson 2 (Part 1 2022) and trying to deploy the app on HuggingFace spaces (the “testing” example). When I use git push I get the following error
@Kamui I found in my case the remote end hung up error was followed by: git-lfs filter-process: git-lfs: command not found
I installed git-lfs using homebrew (brew install git-lfs) and that solved the issue for me.
ImportError: cannot import name ‘Doc’ from ‘typing_extensions’ (/Users/m/anaconda3/lib/python3.11/site-packages/typing_extensions.py)
I’m running this Jupyter notebook locally with Python 3.8. Gradio is v3.50.2 and FastAPI is v 0.104.0.
I’ve tried uninstalling gradio, FastAPI and typing-extensions and downgrading the versions but to no avail.
How can I proceed with Lesson 2? Any help is much appreciated.
Here’s the error in full:
File ~/anaconda3/lib/python3.11/site-packages/fastapi/exceptions.py:6
4 from starlette.exceptions import HTTPException as StarletteHTTPException
5 from starlette.exceptions import WebSocketException as StarletteWebSocketException
----> 6 from typing_extensions import Annotated, Doc # type: ignore [attr-defined]
9 class HTTPException(StarletteHTTPException):
10 “”"
11 An HTTP exception you can raise in your own code to show errors to the client.
12
(…)
34 ```
35 “”"
ImportError: cannot import name ‘Doc’ from ‘typing_extensions’ (/Users/m/anaconda3/lib/python3.11/site-packages/typing_extensions.py)
I get the same error in Google Colab. I copy-pasted the code from Tanishq’s tutorial on Gradio+Huggingface Spaces into a copy of 02_production.ipynb (2nd notebook from the book).
labels = learn_inf.dls.vocab
def predict(img):
img = PILImage.create(img)
pred,pred_idx,probs = learn_inf.predict(img)
return {labels[i]: float(probs[i]) for i in range(len(labels))}```
import gradio as gr
gr.Interface(fn=predict, inputs=gr.Image(shape=(224, 224)), outputs=gr.Label(num_top_classes=3)).launch(share=True)
<ipython-input-28-859b48895f67> in <cell line: 1>()
----> 1 import gradio as gr
2 gr.Interface(fn=predict, inputs=gr.Image(shape=(224, 224)), outputs=gr.Label(num_top_classes=3)).launch(share=True)
13 frames
/usr/local/lib/python3.10/dist-packages/fastapi/exceptions.py in <module>
4 from starlette.exceptions import HTTPException as StarletteHTTPException
5 from starlette.exceptions import WebSocketException as StarletteWebSocketException
----> 6 from typing_extensions import Annotated, Doc # type: ignore [attr-defined]
7
8
ImportError: cannot import name 'Doc' from 'typing_extensions' (/usr/local/lib/python3.10/dist-packages/typing_extensions.py)
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.`
I’ve been banging my head against the wall on this for several hours now. import gradio is giving me this error message: no module named ‘gradio’. I’ve installed gradio, I’m able to locate it in Finder. It is located in:
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/
untar_data is a fastai function that takes a URL and extracts the paths from it. URLs is a fastai object that contains different URL values corresponding to freely available datasets.
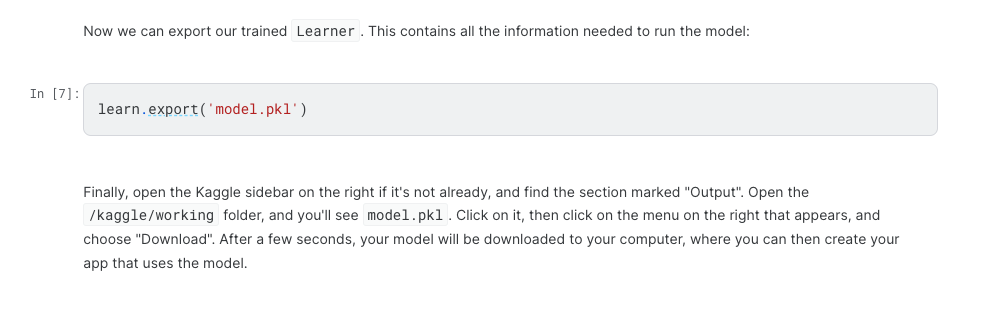
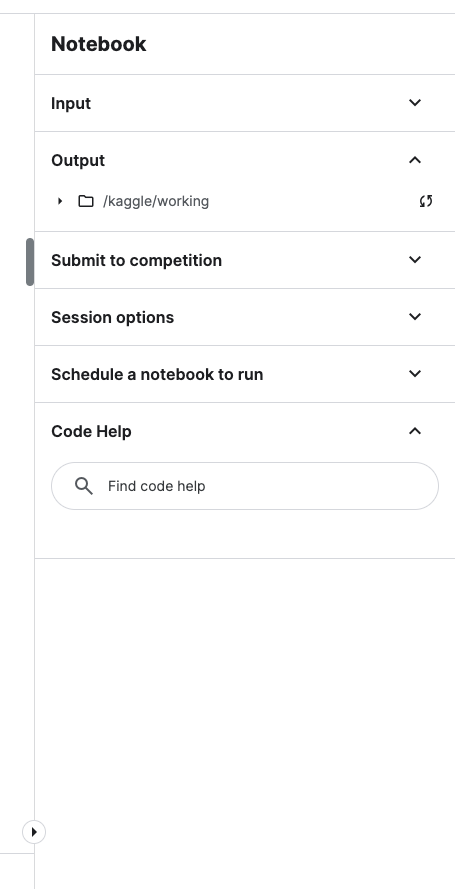
If you are looking for the saved model output from the following line:
Either download it while your Kaggle notebook is running from the '/kaggle/workig folder in the sidebar, or after you save your notebook (by clicking “Save Version” > “Save & Run All (Commit)”), you should be able to access the exported model in the “Output” tab on the page in your screenshot.
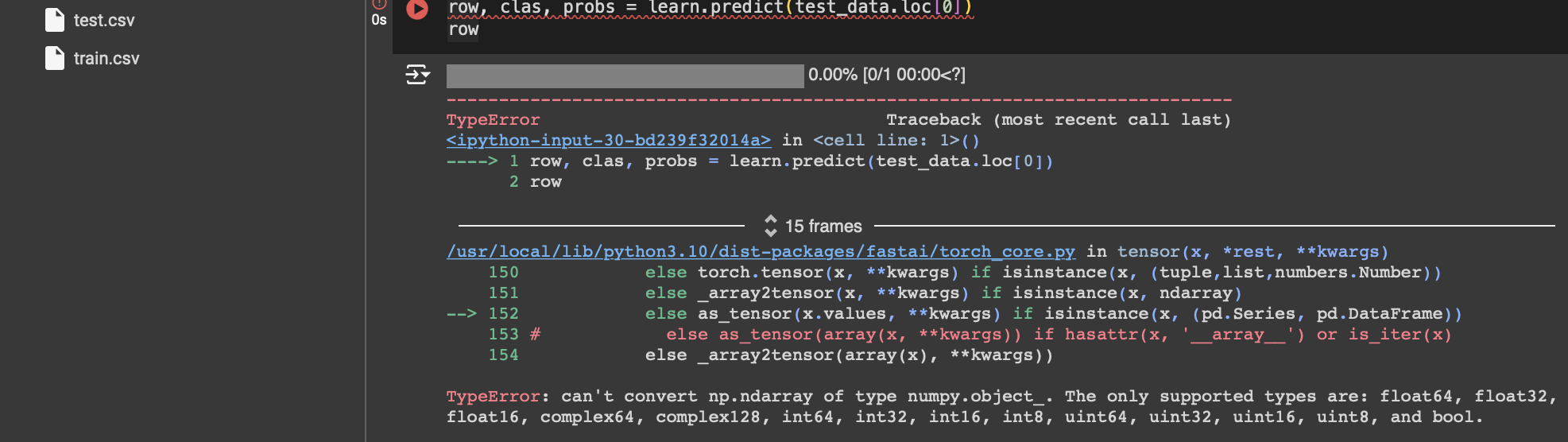
I am experimenting with a tabular data where the Unique ids and zip codes are in number format , but they are categorical features so I converted them to string
but the model is not predicting on them saying its object
Hi, I want to create a classifier for one of the Tensorflow datasets called bee_dataset with multiple class labels. Is there any tutorial on how to do it, meaning how to get from the Tensorflow’s dataset to fastai’s DataLoaders? I am trying to first convert the tf dataset into Pytorch’s DataLoader and then pass it to DataLoaders but I came across multiple problems with this approach. Is there some notebook that is doing the similar thing that I can examine? Thanks!