Yes, you can do this by treating it as a regression problem. Here is an example that goes into a lot of detail so I’ll highlight the main part that shows this type of regression—notice that in DataBlock the blocks parameter is given an ImageBlock for the inputs and RegressionBlock for the outputs, in this case age is predicted by the image:

2 Likes
Awesome! That was exactly what I was referring to! Thanks for sharing this @vbakshi !
To dive into this a little bit deeper: Does somebody know if there exists a procedure for multidimensional targets that are statistically dependent to each other?
So assume instead of just 1 knob for temperature like in the example of my original post 2 days ago, we now would have to analyze images of stormy clouds. Our target consists of 3 knobs; 1 knob for guessing the temperature, 1 knob for guessing the pressure, 1 knob for guessing humidity. All of these 3 variables passively depend on each other, e.g. with higher temperature, there might be higher humidity as well. So how would you calculate a loss in this case? It’s like a multidimensional loss with more than 1 target, where the targets are not independent of each other - is something like this possible?
1 Like
I don’t know how the dependency of the different outputs on each other would affect the loss calculation, but this Walk with fastai example might answer your question on how to train multiple targets for each image.
1 Like
Is there a GitHub repository for the course videos? I’m particularly interested in the code for Lesson 13.
Cycle-gan from 2018? I think it is in this repo. https://github.com/fastai/course-v3/tree/master/nbs/dl2
I just assumed that maybe in case of dependency the loss of the multiple targets could also be calculated by using co variance matrices, but thanks again @vbakshi the walk with fastai example with multiple targets in an image was also exactly what I had in mind ! Thanks for sharing this !
Another question: does something like this exist / would it be possible to design a model that learns how to set some of these knobs? Something like a parameter / tensor / knob setting assistance tool?
So say you’d have a software for image or video editing or an digital audio workstation or any software that has knobs to set certain parameters to edit something. You’d create a lot of data for nearly unprocessed video / audio files / whatever and have a model X to learn the multiple targets (multiple knobs inside the software that are all pretty low in the first model X, so the dry/wet ratio would be something like 95/5, very little effect of the processing visible in the image/audio/etc).
Then you’d train a model Y with the exact same files / data like in model X, but with the difference that all of the data has been modified so that the processing of the software is set just about right. So in model Y for the exact same targets you would get a dry/wet ratio of maybe 50/50. Meaning that the targets in model X are all lower in value than the targets of model Y but essentially they are describing the same physical parameter. So in the final step you would sort of “measure the distance between the input data points of model X and model Y and learn what effect it has on the targets of model X and model Y” and put that information inside yet another model to have it learn how to get from data points X to data points Y buy changing targets X to targets Y. It’s like a model that watches inputs and outputs of two other models and learns how to get from one to another. Could this be done with two models that have multiple targets? Then you could use that third final model for uncompressed/unprocessed data to have kind of an “assistance parameter setting tool” where it would suggest certain settings inside the software automatically? Would something like this be possible?
There should be some ‘import’ lines before this. If working through Kaggle notebook, ensure you have run code in the previous cells.
Kaggle sometimes collapses code cells for brevity. e.g
‘’’
from duckduckgo_search import ddg_images
from fastcore.all import *
def search_images(term, max_images=30):
print(f"Searching for ‘{term}’")
return L(ddg_images(term, max_results=max_images)).itemgot(‘image’)
‘’’
it worked! , there was some other issue
thanks!
Is it possible to do “resnet18” finetuning with a single category + “or else”?
Context:
For the first lessons take-home assignment I want to recreate the “hotdog - not hotdog” app from HBO silicon valley.
Following a blogpost (linked in kaggle notebook, as new user only can post single url), I see it recommended to have a training set with images which are “hotdogs” and images which are “other food”.
Goal
I would like to have a probability how likely a given image is a hotdog, and if less than e.g. 50% would just say “not a hotdog”.
I want to only train/finetune the model on hotdog images so that it can detect those, but don’t provide any “non-hotdog” images in the trainingset.
My assumption is, that resnet already contains the info of millions of “or else” images, so it should be capable of figuring out that something is not a hotdog, right?
Code
This is the kaggle notebook I am working in Hotdog - Not Hotdog? | Kaggle
What you’re describing is binary classification (hotdog/not hotdog). You need to provide examples during training for the negative ‘not hotdog’ class. The model is going to find the easiest way to answer the question and if the answer is always ‘hotdog’ it’s going to just start always answering ‘hotdog’.
I believe hotdog was one of the original imagenet classes so you could just use the fully pretrained imagenet model (including the linear final linear layers) and perform inference only on that and ignore all the other labels, but that’s not really ‘training’ anything.
Hey guys, I’m quite sorry for such a irritating dumb question
I’ve been falling over the theory practice trap. I seem unable to bridge this gap.
How do you start?
I feel constantly overwhelmed, I know the theory, I went over it in university and in multiple courses.
But then I feel frozen, take a random kaggle competition and try what? Just methods I saw somewhere else until it gets decent?
Implement papers? Like I read them, understand them and I know I can code, but I just don’t know where to pick them up from.
I feel unable to apply anything, I just can’t figure out where to start for ages. I just want to do something that I can show and start iterating.
I’m quite frustrated with this and I know somebody must have gone through this, sorry for venting the frustration any help is very welcomed
Find something that interests you or that you like to do. If you don’t know what that is then you just need to try things until you do.
- Do you have a problem at work, school or in life that you think would be interesting to solve? If so start working on that. If you get stuck ask for help on the forums or maybe Twitter.
- Kaggle competitions can be fun and challenging. See how well you can do. Jeremy has videos where he walks through his process getting to the top of the leader board on the Paddy Doctor competition. That competition is a good starter competition, but if you’re more advanced and want to try a recent for money competition then I’d still watch Jeremy’s videos on his process because he has a lot of great tips and processes and then just try and submit something at least a few times a week but as often as you possibly can.
- Go through the fast.ai course and actually code all the notebooks from scratch yourself without looking at the examples.
- Write a blog post about the lessons. Pretend your audience is your former self 6 months ago.
Ultimately building things is the best way to learn and advance your skills. Finding something you find fun and interesting helps get you through the tough parts. Ultimately for me I just want to work on hard problem that I can see the benefit of. The more things you build to advance your skills, the better off you’ll be. Don’t be afraid to try a bunch of different things and follow your interests, you never know when what seemed like a tangent at the time will actually be an important stepping stone or skill in the future.
2 Likes
Thank you!
For some reason I had quite a shift in mentality since then, not perfect by far but just decided to jump in into a competition (beginner ones) and have been trying to make progress. Probably related to getting a temporary position where I’m likely going to help out on research and get paid to learn and wanting to pad my resume with proven skills.
It never feels like “adequate work” I just picked up Bert got results, then tried shifting to using PyTorch and am currently trying to implement models there (started with a basic linear one and now trying to use their LSTM and then implement it myself).
After this I will probably just cleanup the notebook and describe the steps and then maybe try to join another one and try to get to transformer.
Following that I don’t really know but I will already be pretty ahead from where I was and understanding it more I hope.
Essentially I think I have a problem with finding projects and things that truly motivate me, probably some kind of analysis paralysis or hard time picking stuff not sure. Constantly in a rush to get to something productive even though I’m not really sure what that is.
Hopefully I will find an interesting small project that calls me and I feel excited to contribute to!
Thank you a lot for your answer!
While it might be reasonable to assume by posting here you had done the fastai course, you don’t mention this, but that you’ve “only” done the theory - which doesn’t seem like something a fastai graduate would say.
So recommend your next step is to do https://course.fast.ai/, which operates the opposite of most courses by starting with practice and working back towards theory.
Also look at the live coding sessions Live-coding (aka walk-thrus) ✅
1 Like
Hey!
I have (actually a couple of times, once a few years ago but didn’t complete it and in May in a proper way), gone through every notebook and did everything, but had never joining a competition or found a project because I just didn’t find anything that sounded either interesting (I build a ton of simple classifiers) or that I could actually add anything to it.
You could say it was analysis paralysis. Right now I’m trying to get into a few datasets from Kaggle that seem complex and follow on existing notebooks to then apply to other datasets. To keep building up, I think it’s a mental block of wanting to be good and knowing what I’m doing from the get go. I’m trying to focus on the mentality that doing something gets me to a better place, if I’m not interested or hate it, then at least I will know better by trying. This and wanting to have deliverable things to actually point to.
Still at points (like today, trying to get into an medical imaging dataset) I just feel like frozen from the immensity. Like all I can do is run existing notebooks and that I will have an hard time making an actual contribution. That sure I can try different models (having a few ideas on what might work or not) but that doesn’t feel really insightful.
One major question I have is, when do you stop? How do you set a success state? I still struggled with the idea of just keep trying stuff to see what gets better. In the last one I stopped when I felt I was no longer feeling curious essentially.
1 Like
When doing practice problems and competitions, the drive is to perpetual improvement. For practical problems, “good enough” may be sufficient for task requirements. YMMV.
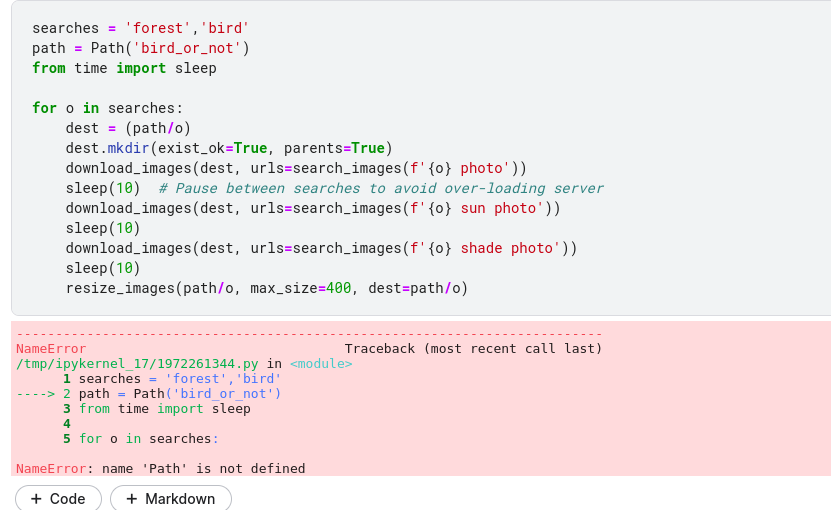
I am just starting with chapter-1 and the “Is it a bird” notebook. I am getting the following error on running the code
urls = search_images(‘bird photos’, max_images=1)
urls[0]
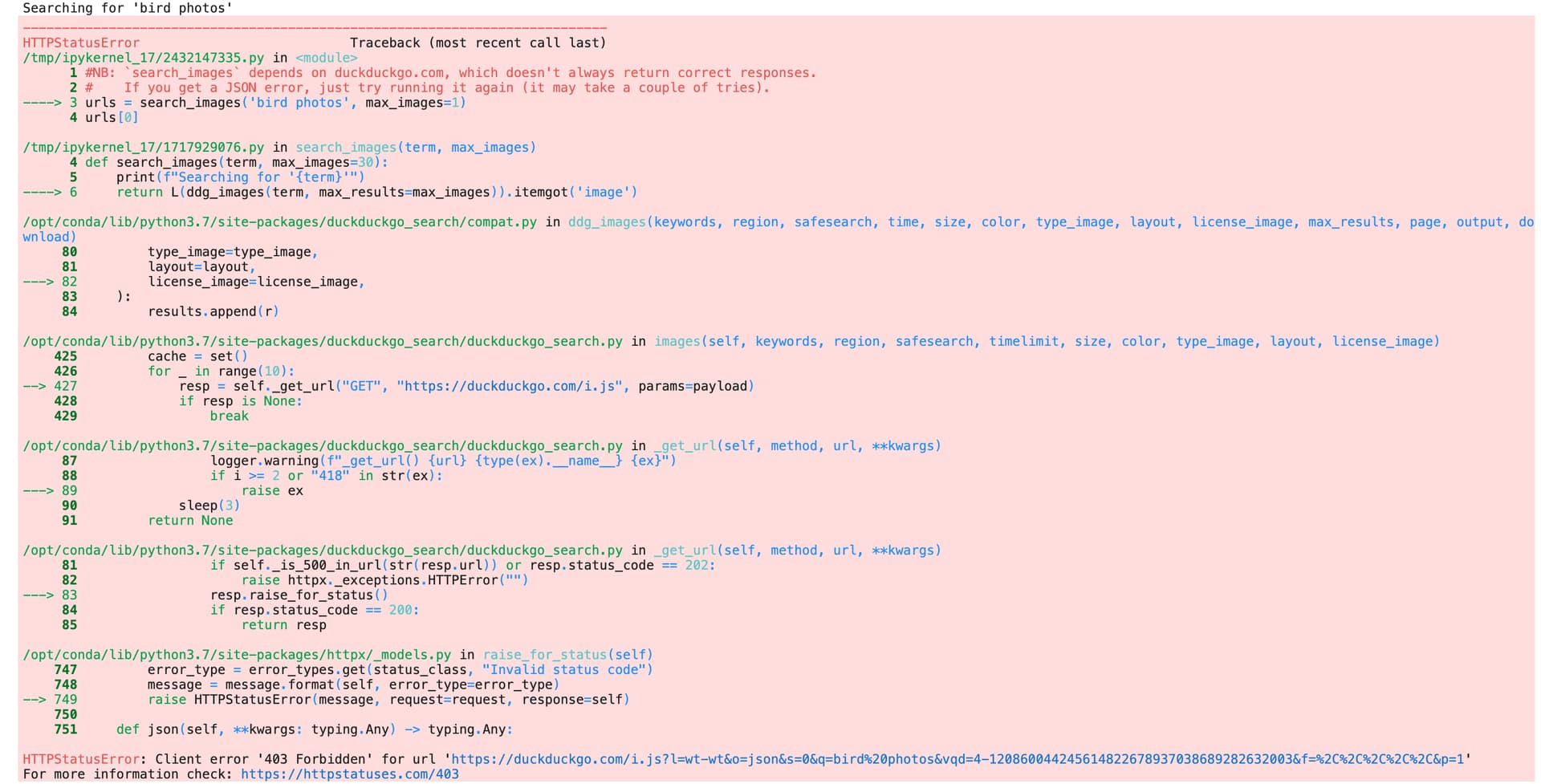
Has anyone faced this issue or know how to resolve this
2 Likes
Hi all, I’m having trouble doing the titanic data set. My accuracy never changes
I started it as talked about in the chapter 4 web page. I tried at first doing the Sequential nn like in the example in the book but saw the data loader for tabular data splits into category and continuous so the shape is wrong. I switched to just a tabular loader and learner and have this problem. My code is below
import torch
import fastai
from fastai.tabular.all import *
import pandas as pd
import numpy as np
train = pd.read_csv('train.csv')
def clean_data(pd_frame):
# select relevant rows
pd_frame["Sex"] = pd_frame["Sex"].map(lambda x: 1 if x == "male" else 0)
pd_frame.fillna(pd_frame.mean())
pd_frame["Age"] = pd_frame["Age"].replace(np.nan, pd_frame["Age"].mean())
pd_frame = pd_frame[["Survived", "Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]]
one_hot = pd.get_dummies(pd_frame["Embarked"])
pd_frame = pd_frame.drop('Embarked',axis = 1)
pd_frame = pd_frame.join(one_hot)
return pd_frame.astype(float)
print("cleaning data...")
train = clean_data(train)
print("data clean")
dls = TabularDataLoaders.from_df(train, y_names="Survived")
print(train.to_markdown())
loss = torch.nn.MSELoss
learn = tabular_learner(dls, opt_func=fastai.optimizer.SGD, metrics=fastai.metrics.accuracy)
print("Have learn")
learn.fit(40, lr=learn.lr_find())
I found my solution in another thread, it was not clear to me that I needed to pass y_block = CategoryBlock to the tabular loader in order for it to work.
1 Like