I did some experimenting with the hyper-parameters (if that is the correct terminology) of my Which Watersport project (code on kaggle) to develop my sense of their effect. While recognising this is a pinhole view from a single use case (a dataset with 37 categories), it examines:
- successive application of multiple fine_tune_ing
- comparing 4 x fine_tune(5), 2 x fine_tune(10), 1 x fine_tune(20)
- comparing resnet16 versus resnet34
- comparing resize(400) versus random_resize_crop(400)
The progressive epoch error is visualised in this chart, which I’ve annotated with a few features…
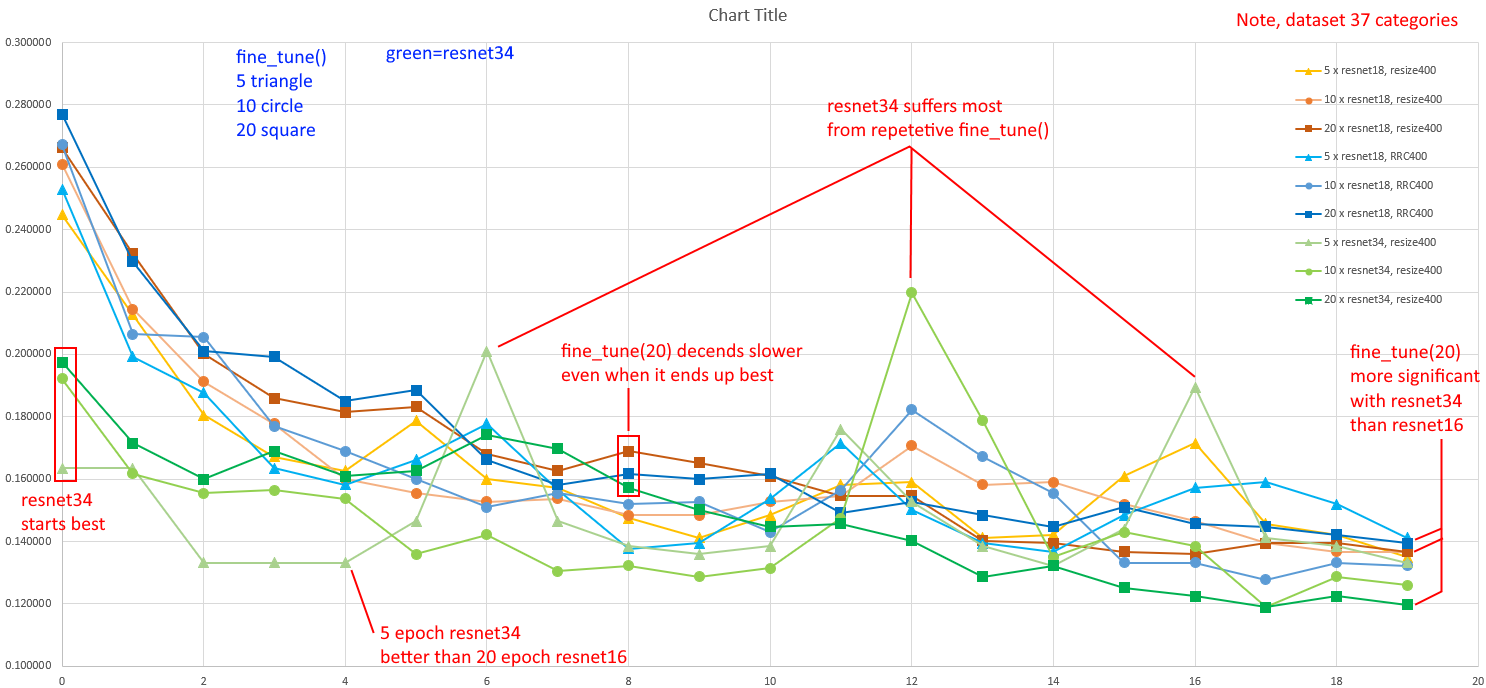
Raw data is in google sheet here. (Note, chart actually generated in Excel since it has a better charting tool) On thing that initially struck me as really bizzare is the great amount of six-decimal-place-numbers that are repeated. I’ve since speculated that the 20% size of the validation set means there are only some many combinations of fractions formed by this equation…
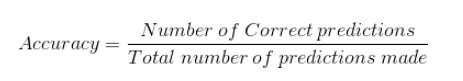
Another curious thing looking at the [resnet34 RRC150] tab, is that
RandomResizedCrop(150) with resnet18 performed much worse than the others.
I am wondering if the crop size might be too small, so too many irrelevant images containing only water are processed??
And that leads me to wondering… Lesson Three [20:48] indicates that the transformes done during training are repeated during inference processing. Is it possible that RandonResizedCrop is causing inferencing to be performed on crops containing only water, which would be really hard to classify to a pariticular sport??